干货 :六招教你用Python分分钟构建好玩的深度学习应用
[导读]深度学习是近来数据科学中研究和讨论最多的话题。得益于深度学习的发展,数据科学在近期得到了重大突破,深度学习也因此得到了很多关注。据预测,在不久的将来,更多的深度学习应用程序会影响人们的生活。实际上,我认为这种影响已经开始了。
如果你站在圈外的角度,深度学习可能看起来让人望而生畏。 像TensorFlow,Keras,基于GPU的计算等专业术语可能会吓到你。 但是,悄悄告诉你 – 深度学习并不难! 紧追前沿的深度学习技术的确需要花费时间和精力,但应用它们解决日常生活中的问题还是很容易的。
有趣的是,在我应用深度学习技术的过程中,我重拾了孩童时期的乐趣和好奇心。在这篇文章里,我将介绍6个这样的应用。它们开始的时候看起来很难实现,但是如果利用深度学习,问题就可以在一个小时内迎刃而解。本文展示了一些具有突破性价值的成果,并向你介绍它们是如何运作的。
目录
1.使用现有API的应用程序
-
深度学习API的优缺点
-
利用深度学习为照片着色(使用Algorithmia 开发的API)
-
使用Watson API构建聊天机器人
-
基于情感分析的新闻聚合器(使用Aylien 开发的API)
2.开源应用程序
-
开源代码的优缺点
-
利用深度学习进行语句校正
-
利用深度学习进行男女肖像转换
-
开发深度强化学习机器人来玩Flappy Bird这款游戏
3.其他有价值的资源
1.使用现有API的应用程序
API不过是一种运行在远端PC的程序。可以在本地通过互联网远程连接。例如,即使你的电脑里已经内置了扬声器,你仍可以再插入一个蓝牙。这样,利用笔记本电脑就可以远程访问扬声器。
API 的概念类似于有人已经帮你实现了较难的那部分工作。你可以用它来快速解决手上的问题。
我将列出一些使用API构建应用程序的优缺点。
1.1.1深度学习API的优点
-
深度学习应用程序通常对GPU计算能力和数据存储/处理性能有较高要求。因此,你可以创建自己的工作站(或使用任意云服务),并在本地使用任意系统来访问工作站并运行应用程序。
-
本地系统不受计算负担影响。
-
轻松集成新功能。
1.1.2深度学习API的缺点
-
构建API的成本很大。开发和维护一个API需要投入时间和资源,这多少有点沉闷乏味。
-
容易受到互联网连接的限制。任何时刻的连接失败都会导致整个系统的中断。
-
如果任何人可以轻松连接你的应用,它将暴露安全问题。你必须设置额外的安全层,例如设置用户名和密码,并限制在一段时间内可以访问的次数。
让我们开始吧!
1.2使用深度学习(Algorithmia API)为照片着色
自动着色一直是计算机视觉社区中的热门话题。从一张黑白图片获得一张彩色照片似乎是件超现实的事。想象一个4岁的孩子拿着蜡笔全神贯注于涂鸦本的场景,我们是否能教会人工智能同样去做这件事情呢?
这是当然一个难题。人类在观察事物颜色的过程中得到了经年累月的训练,我们自己可能不会注意到,但是我们的大脑在捕捉生活的每一刻,并从中提取有意义的信息,如天空是蓝的、草是绿的。这很难在人工智能体中建模。
近期的一项研究表明,如果我们基于大量准备好的数据集,对神经网络进行足够的训练,就能够从灰度图像中幻化出颜色的模型。下面是一个图像着色器的示例:
为了实现这一点,我们使用由Algorithmia开发的API。
规格要求:
-
Python(2或3)
-
网络连接(用于调用API端点)
-
12个积分(积分需要支付获得,不过注册Algorithmia可免费获赠5000积分)
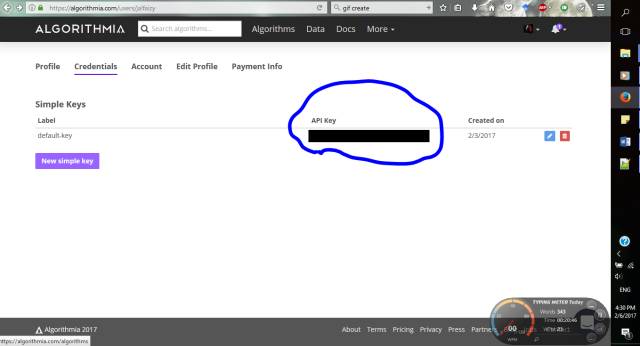
步骤1:在Algorithmia上注册并获取您自己的API密钥。 你可以在个人资料中找到API密钥。
pip install algorithmia
步骤2:输入pip语句安装Algorithmia。
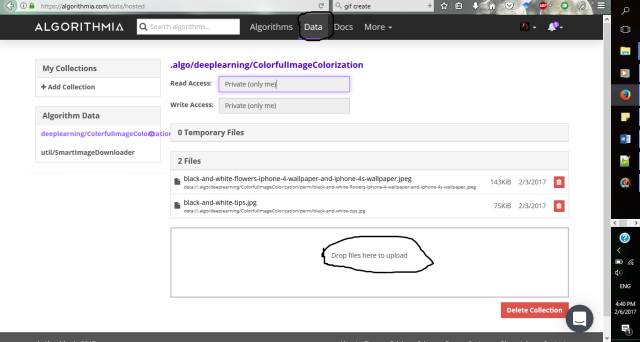
步骤3:选择要着色的照片,并将其上传到algorithmia提供的Data文件夹中。
步骤4:在本地创建一个文件,命名为trial1.py。 打开它,并写如下代码。注意需要输入你的图像在data文件夹中的路径,还有你的API密钥.
import Algorithmia
input = {
"image": "data:// … " # Set location of your own image
}
client = Algorithmia.client(‘…’) #insert your own API key
algo = client.algo('deeplearning/ColorfulImageColorization/1.1.5')
print algo.pipe(input)
步骤5:打开命令提示符并输入“python trial1.py”运行刚才的代码。 输出的结果将自动保存在数据文件夹中。这是我得到的:


就是这样 - 你刚刚创建了一个简单的应用程序,它就像个孩子,可以填充图像中的颜色!容我自high一下:一颗赛艇!
1.3构建聊天机器人(Watson API)
Watson是一个展现人工智能的杰出例子。你可能听说过Watson在一个问答游戏中战胜人类的故事。 Watson集合了许多技术,深度学习是其学习过程的核心部分,特别是在自然语言处理方面。在此,我们将使用Wastson众多应用中的一个来构建对话服务。也就是聊天机器人。聊天机器人是一个能像人一样回答常见问题的智能体。它可以很好地与客户交流并作出及时回复。
这里有一个演示平台:

要求和规格:
-
Python(2或3)
-
网络连接(用于调用API端点)
-
激活的Bluemix帐户(试用期为30天)
让我们来看看如何用Watson一步步构建简单的聊天机器人。
步骤1:在Bluemix上注册并激活保护服务以获取凭据

步骤2:打开terminal界面,运行命令如下:
pip install requests responses
pip install --upgrade watson-developer-cloud
步骤3:创建一个文件trial.py并复制以下代码。记住加入个人凭据。
import json
from watson_developer_cloud import ConversationV1
conversation = ConversationV1(
username='YOUR SERVICE USERNAME',
password='YOUR SERVICE PASSWORD',
version='2016-09-20')
# replace with your own workspace_id
workspace_id = 'YOUR WORKSPACE ID'
response = conversation.message(workspace_id=workspace_id, message_input={
'text': 'What\'s the weather like?'})
print(json.dumps(response, indent=2))
步骤4:保存文件并在控制台中输入“python trial.py”运行程序。你可以在控制台中得到Watson对输入信息的输出响应。
输入:显示附近的内容。
输出:我明白你想要我找到一个便利设施。我可以在附近找到餐厅,加油站和洗手间。
如果你想构建一个包含动态汽车仪表盘(如上面gif所示)的完整对话服务项目。查看这个github存储库。
几分钟就能实现聊天机器人和着色应用,不错~
1.4基于情绪分析的新闻聚合器(Aylien API)
有时我们只想看到世界上的美好事物。如果读报纸的时候,只看到“好”消息,过滤掉所有坏消息,这将是多么酷的一件事。
使用先进的自然语言处理技术(其中之一是深度学习)使得一切成为可能。你现在可以根据情绪分析文本对新闻进行过滤,并将其呈现给读者。
采用Aylien的新闻API可以实现这一功能。下面是演示的截图。你可以构建自定义查询,并检查结果。
让我们看看在python中的实现。
要求和规格:
-
Python(2或3)
-
网络连接(用于访问API端点)
步骤1:在Aylien网站上注册一个帐户。
步骤2:登录时从个人资料中获取API_key和App_ID。
步骤3:进入terminal界面输入下面的语句,安装Aylien新闻API。
pip install aylien_news_api
步骤4:创建一个文件“trial.py”并复制以下代码。
import aylien_news_api
from aylien_news_api.rest import ApiException
# Configure API key authorization: app_id
aylien_news_api.configuration.api_key['X-AYLIEN-NewsAPI-Application-ID'] = ' 3f3660e6'
# Configure API key authorization: app_key
aylien_news_api.configuration.api_key['X-AYLIEN-NewsAPI-Application-Key'] = ' ecd21528850dc3e75a47f53960c839b0'
# create an instance of the API class
api_instance = aylien_news_api.DefaultApi()
opts = {
'title': 'trump',
'sort_by': 'social_shares_count.facebook',
'language': ['en'],
'published_at_start': 'NOW-7DAYS',
'published_at_end': 'NOW',
'entities_body_links_dbpedia': [
'http://dbpedia.org/resource/Donald_Trump',
'http://dbpedia.org/resource/Hillary_Rodham_Clinton'
]
}
try:
# List stories
api_response = api_instance.list_stories(**opts)
print(api_response)
except ApiException as e:
print("Exception when calling DefaultApi->list_stories: %s\n" % e)
步骤5:保存文件并通过键入“python trial.py”开启运行。输出将是如下所示的jason dump:
{'clusters': [],
'next_page_cursor': 'AoJbuB0uU3RvcnkgMzQwNzE5NTc=',
'stories': [{'author': {'avatar_url': None, 'id': 56374, 'name': ''},
'body': 'President Donald Trump agreed to meet alliance leaders in Europe in May in a phone call on Sunday with NATO Secretary General Jens Stoltenberg that also touched on the separatist conflict in eastern Ukraine, the White House said.',
'categories': [{'confident': True,
'id': 'IAB20-13',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20-13',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20'},
'score': 0.3734071532595844,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB11-3',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB11-3',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB11'},
'score': 0.2898707860282879,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB10-5',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10-5',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10'},
'score': 0.24747867463774773,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB25-5',
'level': 2,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB25-5',
'parent': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB25'},
'score': 0.22760056625597547,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB20',
'level': 1,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB20',
'parent': None},
'score': 0.07238470020202414,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB10',
'level': 1,
'links': {'_self': 'https://api.aylien.com/api/v1/classify/taxonomy/iab-qag/IAB10',
'parent': None},
'score': 0.06574918306158796,
'taxonomy': 'iab-qag'},
{'confident': False,
'id': 'IAB25',
...
哇!我可以做一个根据兴趣筛选新闻的对话应用程序了!我相信,现在你对深度学习感到很兴奋!
2.开源应用程序
现阶段,对研究社区起最大帮助的是开源思维。研究人员分享他们取得的成果,深度学习也因此得到了跨越式发展。这里我涉及了一些开源成果,它们都是从从研究论文中转变过来的。
2.1.1开源应用的优点
-
由于应用程序是开源的,你可以查看应用程序的任何细节,并且如果需要,还可以轻松自定义。
-
来自不同组织、拥有不同经验的开发人员会在应用程序中协作。这使得应用程序比原始版本更好。此外,因为很多人都可以使用,所以这个应用程序可以不断地进行测试,更方便地被使用。
2.1.2开源应用程序的缺点
-
因为没有组织从背后支持,开源项目中往往缺少“责任意识”,如果发生问题也不知道该责问谁。
-
还有明显的许可问题,许多公司都不愿将他们的项目“公开”。
注意:对于开源应用程序,我建议你浏览一遍官方的存储库。因为很多项目仍处于初级阶段,可能会因为未知的原因而中断。
让我们来看一些开源应用程序!
2.2利用深度学习进行语句校正
现在的系统可以轻松检测和纠正拼写错误,但纠正语法错误有点困难。为了提升这一能力,我们可以使用深度学习。这个存储库是特意为此设置的。
我整理一下……
这里我们使用一个语料库来训练序列预测神经网络,该语料库包含一系列语法错误的句子以及它的更正结果。
训练模型为语句的矫正提供了正确答案。下面是一个例子:
输入:‘Kvothe went to market’
输出:‘Kvothe went to the market’
你可以在网站上查看演示:http://atpaino.com/dtc.html
该模型仍然无法校正所有的句子,但随着更多的训练数据和高效的深度学习算法,结果会越来越好。
要求:
-
Python(2或3)
-
GPU(可选用于更快的训练)
步骤1:从官网上安装tensorflow。另外,从GitHub下载存储库,并从https://github.com/atpaino/deep-text-corrector保存到本地。
步骤2:下载数据集(Cornell Movie-Dialogs Corpus),并将其解压到工作目录中
步骤3:通过运行命令创建训练数据
python preprocessors/preprocess_movie_dialogs.py --raw_data movie_lines.txt \
--out_file preprocessed_movie_lines.txt
并创建训练,验证和测试文件,并将其保存在当前工作目录中
步骤4:现在训练深度学习模型:
python correct_text.py --train_path /movie_dialog_train.txt \
--val_path /movie_dialog_val.txt \
--config DefaultMovieDialogConfig \
--data_reader_type MovieDialogReader \
--model_path /movie_dialog_model
步骤5:该模型需要一些时间来训练。训练完成后,可以通过以下方式进行测试:
python correct_text.py --test_path /movie_dialog_test.txt \
--config DefaultMovieDialogConfig \
--data_reader_type MovieDialogReader \
--model_path /movie_dialog_model \
--decode
2.3利用深度学习进行男女肖像转换
在谈到该应用程序之前,请观察以下结果:
这里第二张图片是第一张图片通过深度学习得到的!这个有趣的应用程序表明深度学习无所不能!该应用程序的核心在于GAN(生成对抗网络),这种类型的深度学习能够本中生成新样本。
要求:
-
Python(3.5+)
-
Tensorflow(r0.12 +)
-
GPU(可选用于更快捷的训练)
操作之前给你提个醒,如果不使用GPU,模型训练需要花很长的时间。即使使用高端GPU(Nvidia GeForce GTX 1080),一个图像的训练也需2小时。
步骤1:下载存储库并在本地解压缩https://github.com/david-gpu/deep-makeover
步骤2:从CelebA数据集下载“Align&Cropped Images”。创建数据集文件夹,并命名为“dataset”,并把所有图片解压到其中。
步骤3:通过以下方式训练模型:
python3 dm_main.py --run train
然后通过传递想要转换的图像进行测试
python3 dm_main.py --run inference image.jpg
2.4搭建深度强化学习机器人来玩Flappy Bird这款游戏
你可能玩过Flappy Bird这款游戏。对于不知道这个游戏的人来说,这款Android游戏很让人上瘾。在游戏里,玩家需要避开障碍,让小鸟一直在空中飞翔。
在这个应用中,这个飞鸟机器人就是利用强化学习技术创造的。这下面是一个训练好的机器人演示。
要求:
-
Python(2或3)
-
Tensorflow(0.7+)
-
Pygame
-
Opencv-python
实现这个应用很容易,因为多数的基本要素都已经包含其中
步骤1:下载官方存储库。
步骤2:确保已安装所有依赖项。一旦准备完成,运行如下命令。
python deep_q_network.py
4.其他值得一提的资源
本文只是涉及了深度学习模型强大能力的皮毛。每天都有大量论文发表,带来大批像这样的应用。关键是谁能最先提出想法
我还列了一些其他值得一看的资源。
-
A compilation of deep learning applications by Károly Zsolnai-Fehér
-
Neural Artistic Style
-
Building a toy self-driving car bot on Mario Kart.
-
9 Cool Deep Learning Applications | Two Minute Papers
-
10 More Cool Deep Learning Applications | Two Minute Papers
-
10 Even Cooler Deep Learning Applications | Two Minute Papers
-
List of Deep Learning Startups
-
List of awesome Deep Learning Projects
结语
希望你在阅读这篇文章的过程中找到乐趣。这些应用程序绝对会让你感到震撼。有的人可能已经了解这些应用,有的人还没有。如果你参与过这些应用程序的开发,请分享你的经验。我们会拭目以待。
原文发布时间为:2017-03-04
本文作者:卢苗苗、朱煜奇
本文来自云栖社区合作伙伴“数据派THU”,了解相关信息可以关注“数据派THU”微信公众号