该放弃正在堕落的“RNN和LSTM”了

递归神经网络(RNN),长期短期记忆(LSTM)及其所有变体:
现在是放弃它们的时候了!
在2014年,LSTM和RNN重新复活。我们都阅读过Colah的博客和Karpathy对RNN的赞赏。但那个时候我们都很年轻,没有经验。随着这几年的技术的发展,我们才慢慢发现序列变换(seq2seq)才是真正求解序列学习的真正模型,它在语音识别领域创造了惊人的结果,例如:苹果的Siri,Cortana,谷歌语音助手Alexa。还有就是我们的机器翻译,它可以将文档翻译成不同的语言。
然后在接下来的15年、16年,ResNet和Attention模型出现了。人们可以更好地认识到了LSTM其实就是一种巧妙的搭桥技术。注意,MLP网络可以通过平均受上下文向量影响的网络来取代,这个下文再谈。
通过两年的发展,今天我们可以肯定地说:“放弃你的RNN和LSTM!”
有证据表明,谷歌,Facebook,Salesforce等企业正在越来越多地使用基于注意力模型的网络。所有的这些公司已经取代了RNN和基于注意力模型的变体,而这只是一个开始,因为RNN相较于注意力模型需要更多的资源来训练。
为什么?
RNN和LSTM及其变体主要是随着时间的推移使用顺序处理,请参阅下图中的水平箭头:
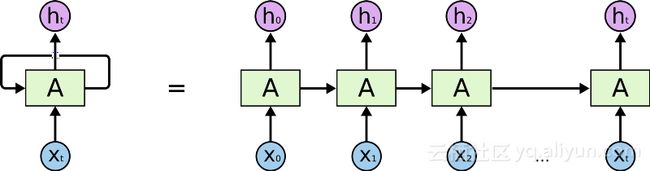
这个箭头意味着,数据必须在到达当前处理单元之前顺序穿过所有单元,这意味着它可以很容易出现梯度消失的问题。
为此,人们推出了LSTM模块,它可以被看作是多个开关门的组合,ResNet就延续了它的设计,它可以绕过某些单元从而记住更长的时间步骤。因此,LSTM可以消除一些梯度消失的问题。
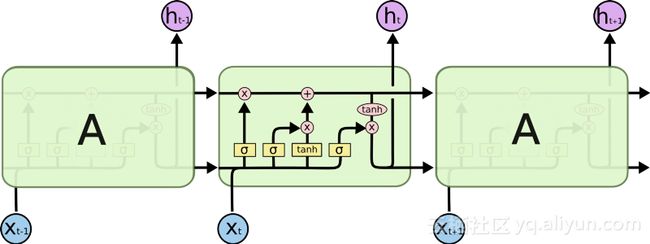
但并不是完全解决,正如你从上图所看到的那样。尽管如此,我们仍然有一条从过去的单元到现在的单元的顺序路径,实际上,现在这些路径甚至变得更加复杂,因为路径上还连接了加如记忆的分支和遗忘记忆的分支。毫无疑问,LSTM和GRU及变体能够学习大量长期的信息!但他们只是可以记住100s的序列,而不是1000s或10000s甚至更多。
并且RNN的另一个问题是需要消耗大量的计算资源。在云中运行这些模型也需要大量资源,并且由于语音到文本的需求正在迅速增长,云能提供的计算能力慢慢的满足不了它了。
我们应该怎么办?
如果要避免顺序处理,那么我们可以找到“向前预测”或更好的“向后回顾”的计算单元,因为我们处理的数据大部分都是实时因果数据。但在翻译句子或分析录制的视频时并非如此,例如,我们拥有所有数据并且可以为其带来更多时间。这样的向前回溯/后向回顾单元就是神经注意力模块,我们此前在此解释。
为了结合多个神经注意力模块,我们可以使用来自下图所示的“ 层级神经注意力编码器”:
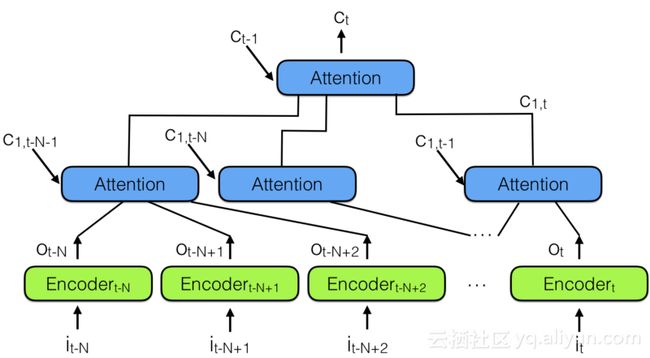
观察过去信息的更好方式是使用注意力模块将过去编码向量汇总到上下文向量 C_t。请注意上面有一个层级注意力模块,它和层级神经网络非常相似。这也类似于下面的备注3中的时间卷积网络(TCN)。
在层级神经注意力编码器中,多层级关注可以查看最近过去的一小部分,比如说100个向量,而上面的层可以查看这100个关注模块,有效地整合100 x 100个向量的信息。这将层级神经注意力编码器的能力扩展到10,000个以前的向量。但更重要的是查看表示向量传播到网络输出所需的路径长度:在分层网络中,它与log(N)成正比,其中N是层次结构层数。这与RNN需要做的T步骤形成对比,其中T是要记住的序列的最大长度,并且T >> N。
简单的说就是回顾更多的历史信息并预测未来!
这种架构跟神经图灵机很相似,但可以让神经网络通过注意力决定从内存中读出什么。这意味着一个实际的神经网络将决定哪些过去的向量对未来决策的重要性。
但是存储到内存呢?上述体系结构将所有先前的表示存储在内存中,这可能是相当低效的。我们可以做的是添加另一个单元来防止相关数据被存储。例如,不存储与以前存储的向量太相似的向量。最好的办法就是让应用程序指导哪些载体应该保存或不保存,这是当前研究的重点。
我们看到很多公司仍然使用RNN / LSTM来完成自然语言处理和语音识别等任务模型,但很多人不知道这些网络如此低效且无法扩展。
总结:
关于训练RNN / LSTM:RNN和LSTM很难训练,因为它们需要内存、带宽、这些因素限制计算的效率,这对于硬件设计师来说是最糟糕的噩梦,并且最终限制了神经网络解决方案的适用性。简而言之,每个LSTM单元需要的4个线性层(MLP层)在每个序列时间步上运行。线性层需要计算大量的内存带宽,事实上,他们并不能经常使用很多计算单元,因为系统没有足够的内存带宽来提供计算单元。添加更多计算单元很容易,但很难增加更多的内存带宽。因此,RNN / LSTM和变体与硬件加速不太匹配,我之前曾讨论过这个问题在这里和这里。
注:
注1:层级神经注意力与WaveNet中的想法类似。但是我们不使用卷积神经网络,而是使用层级神经注意力模型。
注2:层级神经注意力模型也可以是双向的。
注3:这是一篇比较CNN和RNN的论文。时间卷积网络(TCN)“在不同范围的任务和数据集上优于经典的经常性网络,如LSTM,同时展示更大的有效内存。”
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
本文由@阿里云云栖社区组织翻译。
文章原标题《the-fall-of-rnn-lstm》,
译者:虎说八道,审校:袁虎。
文章为简译,更为详细的内容,请查看原文。