先简单介绍数据集,然后基于keras构建一个多层神经网络,实现对房价的回归预测。
波士顿房价数据集(Boston House Price Dataset)
[code: https://github.com/zylhub/More_Python/blob/e646b6bad152c09a15a003a674df6631c93e0963/keras_TOT/simple-network-boston.py ]
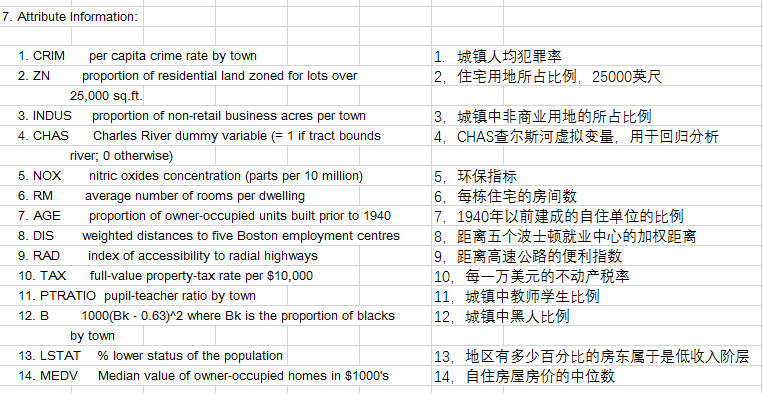
- 每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。
- 每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。
CRIM 城镇人均犯罪率
ZN 占地面积超过2.5万平方英尺的住宅用地比例
INDUS 城镇非零售业务地区的比例
CHAS 查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0)
NOX 一氧化氮浓度(每1000万份)
RM 平均每居民房数
AGE 在1940年之前建成的所有者占用单位的比例
DIS 与五个波士顿就业中心的加权距离
RAD 辐射状公路的可达性指数
TAX 每10,000美元的全额物业税率
PTRATIO 城镇师生比例
B 1000(Bk - 0.63)^2 其中 Bk 是城镇的黑人比例
LSTAT 人口中地位较低人群的百分数
MEDV 以1000美元计算的自有住房的中位数
整个数据集包含13个特征,涵盖了用地情况、教育、人种、收入、环保、犯罪等多个方面。(这是一个标准数据集,特征包含的物理因素也是特征工程的参考。) 同时这是一个1970的数据集,出现的一些数据会和现在有明显的差异。
更多关于波士顿数据集介绍可以参考:http://www.cnblogs.com/wwwjjjnnn/p/7323862.html 或 http://sklearn.apachecn.org/cn/0.19.0/sklearn/datasets/descr/boston_house_prices.html
该数据集在sklearn和keras都内置了,直接调用,开箱即用。
# coding=utf-8
# ---------------------------
# @Time : 17-12-24 上午9:01
# @Author : zylhub
# @File : simple-network-boston.py
# ---------------------------
from keras.datasets import boston_housing
# boston房价数据集,预测房价变化
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
print('train_data shape ', train_data.shape)
print('test_data.shape ', test_data.shape)
print('train_targets: ', train_targets)
# 预处理数据,转化为正态分布
mean = train_data.mean(axis=0) # 求均值
train_data -= mean
std = train_data.std(axis=0) # 求标准差
train_data /= std
test_data -= mean
test_data /= std
# 搭建模型
from keras import models
from keras import layers
def build_network():
network = models.Sequential()
network.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1], )))
network.add(layers.Dense(64, activation='relu'))
network.add(layers.Dense(1))
network.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) # 均方误差作为损失
return network
# k-fold 验证 , 基于numpy实现
import numpy as np
k = 4
num_val_samples = len(train_data)//k
num_epochs = 500
all_scores = []
all_mae_histories = []
for i in range(k):
print("processing fold #", i)
# Prepare the validation data
val_data = train_data[i*num_val_samples: (i+1)*num_val_samples]
val_targets = train_targets[i*num_val_samples: (i+1)*num_val_samples]
#Prepare the training dataa: data from all other partitions
partial_train_data = np.concatenate(
[train_data[: i*num_val_samples],
train_data[(i+1)*num_val_samples:]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[: i*num_val_samples],
train_targets[(i+1)*num_val_samples:]],
axis=0
)
network = build_network()
# 记录每次迭代的训练集和验证集 acc和loss
history = network.fit(partial_train_data, partial_train_targets, epochs=num_epochs,
batch_size=1, verbose=1,
validation_data=(val_data, val_targets))
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
# val_mse, val_mae = network.evaluate(val_data, val_targets, verbose=1)
#
# all_scores.append(val_mae)
# print('all_scores: ', all_scores)
# print('mean ', np.mean(all_scores))
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
print('average_mae_history: ', average_mae_history)
# Plotting validation scores
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history)+1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
# -------------------------------
plt.clf()
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor + point*(1-factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history)+1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
# 根据前面的MAE分析, epochs=80 会是一个合适的模型,下面重新训练模型
model = build_network()
model.fit(train_data, train_targets,
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
print('test_mae_score: ', test_mae_score) # Mean Squared Error
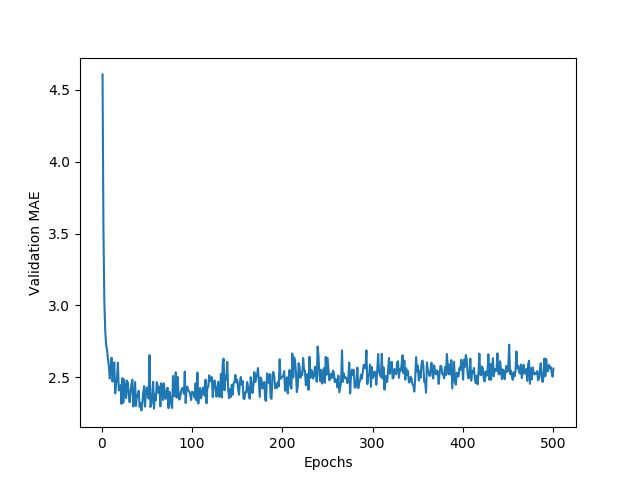
myplot-1.png
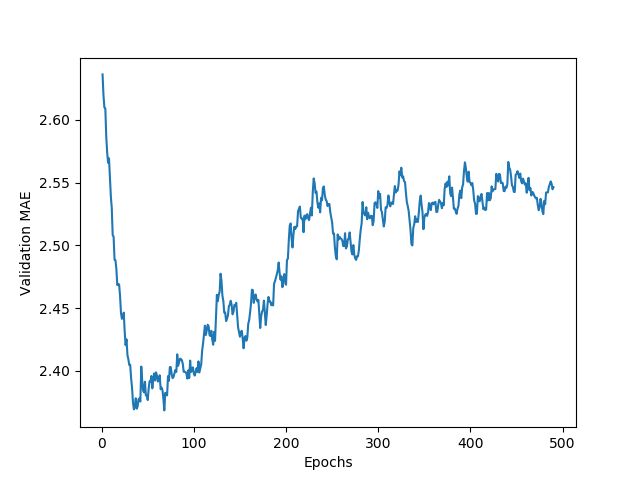
myplot-2.png