如何让语言模型充分利用GPU:针对大规模并行设备的N-gram
爱丁堡大学的论文《N-gram language models for massively parallel devices》介绍了用于大规模并行设备的 N-gram 语言模型。机器之心技术分析师对该论文进行了解读。
论文:https://aclweb.org/anthology/P/P16/P16-1183.pdf
引言
这篇论文谈的是用于大规模并行设备(GPU)的 N-gram 语言模型,这是最早为 GPU 设计的语言模型(至少在这篇论文发表时是这样)。N-gram 语言模型的查询速度存在计算瓶颈,而且尽管 GPU 擅于计算,但在 GPU 上却并不好实现,因为还不存在针对 GPU 的已有的数据结构类型。这个问题导致我们无法完全发挥 GPU 的效力。
1 背景
也许有的读者并不真正了解 N-gram 模型是什么,因此首先我会先简要介绍一些基本概念:
N-gram 语言模型
参阅:https://lagunita.stanford.edu/c4x/Engineering/CS-224N/asset/slp4.pdf
为词序列分配概率的模型被称为语言模型(LM)。N-gram 是目前最简单的语言模型。N-gram 是 N 个词构成的序列:2-gram(bi-gram)是两个词构成的词序列,比如“please turn”;3-gram(tri-gram)是三个词构成的词序列,比如“please turn your”。
我们需要关注的有两点(至少这篇论文是这么说的):
- 给定之前的词,如何使用 N-gram 模型来估计 N-gram 中最后一个词的概率?
- 如何将概率分配给整个序列?
(注意:我们通常会丢弃“模型”这个词,这样 N-gram 既可表示词序列本身,也可表示为其分配概率的预测模型。这或许会产生一点术语歧义。)
对数概率
为什么为语言模型使用对数概率?因为(按照定义)概率是小于或等于 1 的,所以相乘的概率越多,所得到的积就会越小。乘上足够多的 N-gram 就会导致数值下溢。通过使用对数概率而非原始概率,我们能得到不会那么小的值。在对数空间中相加等效于在线性空间中相乘,这样我们就可以通过加法来将对数概率结合到一起。在对数空间中执行所有计算和存储是很方便的,如果我们想查看结果,只需要将结果转换到普通概率空间既可,即求该对数概率的指数:p1 × p2 × p3 × p4 = exp(log p1 +log p2 +log p3 +log p4)
2 这篇论文的动机
因为 N-gram 语言模型的查询速度在 CPU 上存在计算瓶颈(Heafield (2013) 和 Green et al. (2014) 在静态机器翻译任务上展现了这一问题,而且众所周知神经网络需要大量计算),因此人们转而使用 GPU。但是,GPU 采用了特殊的结构设计,在很多方面都不同于 CPU,使用已有的数据结构和算法很难最大化对这一资源的利用。
这篇论文提出了首个专门为这种硬件(GPU)设计的语言模型,它使用了 trie,其中每个节点都由 B-tree 表示,这能最大化数据并行以及最小化内存占用和延迟。
3 GPU 计算模型
比起 CPU,GPU 有很多更小的核,它们各自都实现一个线程,而且其中很多都属于下图所示的一个器件。本质上,在 GPU 上是并行的函数或核执行计算,并会定义一个将被应用的数据元素网格(如下所示)。每个计算都由一个并行线程的模块处理。每个任务都会被分配一整个包(warp)——至少 32 个核。因此,如果这个任务不需要所有这些核,那么剩下的核就会闲置。GPU 编程的更多信息可参考:https://people.maths.ox.ac.uk/gilesm/old/pp10/lec2_2x2.pdf
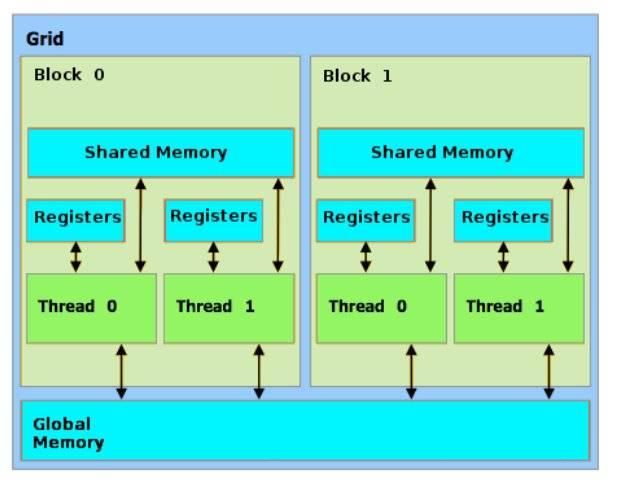
因为运行需要内存存取,所以我们希望使用较小的数据结构。当一个线程向全局内存请求一个字节时,数据会与很多周围的字节一起被复制到共享内存,这样我们就可以使用聚合的读取访问内存了。避免分支指令能充分利用计算资源以及防止线程闲置。从图中可以看到,需要较长时间才能访问全局 GPU 内存,所以我们需要最小化全局内存访问(Bogoychev and Lopez, 2016)。

注意:这里给出一个例子帮助你理解我们应该避免分支指令的原因:如果 a=0,那么 b=1;否则 b=2。我们首先必须评估其条件,然后处理接下来的指令。只有满足条件的线程才会运行,其它线程则会闲置。这能部分地解释我们在并行架构中需要分支的原因。
4 简单介绍 Backoff 语言模型
设有一个句子 w1 w2 w3 w4 … wi,其中 wi 是指第 i 个词。N-gram 模型将 w 的概率定义为:
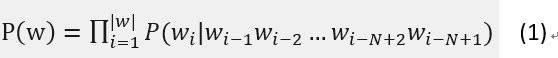
Chen And Goodman (1999) 根据 N-gram 概率定义了 Backoff 语言模型:
这针对的是从 1 到 N 的所有 N,使用了两个参数:N-gram 参数
和
我们可以简单地将它们视为数值参数以简化我们的阐述,所以我们有:
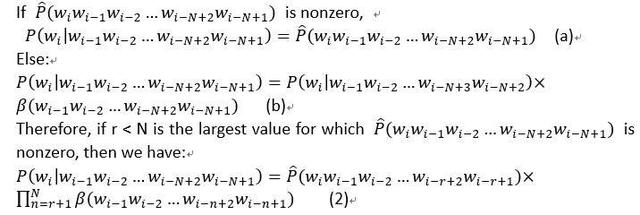
我们可以用 (a) 和 (b) 得到等式 (2)。因此,如果可以轻松得到 p_hat 和 β,我们就可以通过等式 (2) 得到 n-gram 概率。Bogoychev 和 Lopez 基于这种计算设计了一种语言模型数据结构。这篇论文中设计的数据结构可以有效访问这些参数。
5 大规模并行语言模型(这篇论文的成果)
Trie 语言模型
Bogoychev 使用了 Heafield (2011) 设计的 trie 数据的变体来满足上述 Backoff 语言模型的计算需求。(其实验证明了这一假设:trie 更慢的查询速度可以通过 GPU 的吞吐量得到补偿。我们后面会谈到这一实验。)下面展示了一些常见数据结构的细节,以满足 Backoff 和在 GPU 上实现的需求。他选择了 Trie 作为基本结构:

注意:本文假设读者对 Backoff 语言模型已有一定了解;这是描述性的,而不是教程。要真正理解究竟发生了什么,你也许应该尝试下面的练习:假设你有 5-gram“I like pie with rhubarb”,你想要根据上面的 (2) 式计算 P(rhubarb | I like pie with)。
- 如果 p_hat(rhubarb | I like pie with) > 0,你会使用哪几项?
- 如果 p_hat(rhubarb | I like pie with) = 0 但 p_hat(rhubarb | like pie with) > 0,你会使用哪几项?
- 如果 p_hat(rhubarb | like pie with) = 0 但 p_hat(rhubarb | pie with) > 0,你会使用哪几项?
……这应当有助于使该递归过程清晰。
我们将 n-gram 键值存储在一个有序数组 A 中,并将它们的相关值
存储在同等长度的数组 V 中。
我想用一个真实案例来解释这篇论文中的逆 trie 模型的过程、K-ary 搜索和 B-tree。
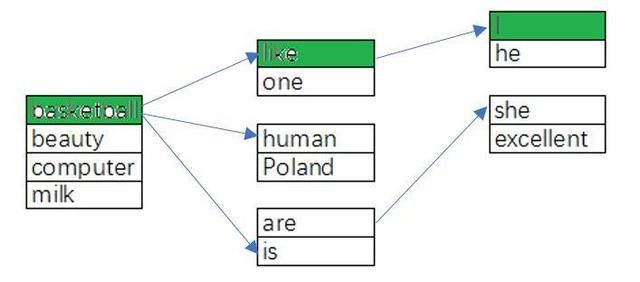
逆 trie(基于Bogoychev and Lopez 中的图像)
这里用绿色展示了 N-gram “I like basketball”的路径。对 N-gram “they like basketball”的查询能遍历同一路径,但最后的节点中没有“they”,因此它会为键值 b
返回键值对,并且由于 backoff 参数 β(they like),只会返回根一次。对于更大的 n,只需迭代式地检索计算式 (2) 所需的参数。
注意:原论文这一段第五行有一个错误,描述了当 n>1 时的查询过程:
这与我们刚刚描述的一样,因为这里没有任何与 K 有关的描述,作者也确认了这个错误。
K-ary 搜索和 B-tree
上面描述的 trie 搜索算法效率不高,需要太多次搜索。K-ary 搜索的速度比二元搜索更快,但需要从全局内存读取数据,因为完整的 trie 必须驻留于全局内存中以适应大型语言模型。Bogoychev 和 Lopez 使用 B-tree(Bayer and McCreight)来替换连续内存位置中的 K 个元素,使得它们可以从全局内存被复制到共享内存,以便合并读取。
所以其完整的数据结构是 trie,其中根节点之外每个节点都是一个 B-tree。根节点包含所有可能的键(unigram),这可以由在没有任何搜索的恒定时间内索引的数组表示。下图准确地展示了这一数据结构(来自 Bogoychev 的论文):
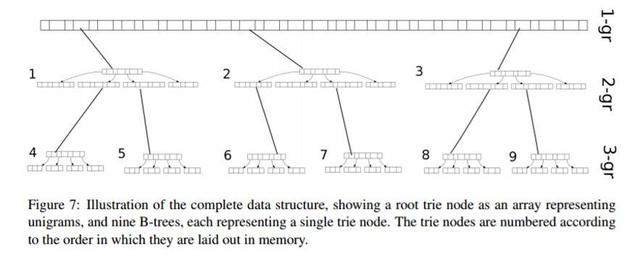
在这幅图中,第一行是 unigram。第二行是 2-gram,第三行是 3-gram。(注意:小图 1 是来自那一段根的 4-ary。)
B-tree 节点包含 K 个子节点相对地址(非全局地址以节省空间)、键 w 和关联值
6 实验和结论
这篇论文设计了七个实验并将该模型与另一个已有的语言模型 KenLM(Heafield, 2011)进行了比较,考虑了实践中的资金成本和性能。
- GPU:英伟达 Geforce GTX, 于 2015 年第一季度发布(1000 美元)
- CPU:单线程的 CPU 测试,英特尔 Quad Core i7 4720HQ,于 2015 年第一季度发布(280 美元)
- 多线程 CPU:两个英特尔 Xeon E5-2680 CPU,能提供 16 核和 32 线程(3500 美元)
查询速度
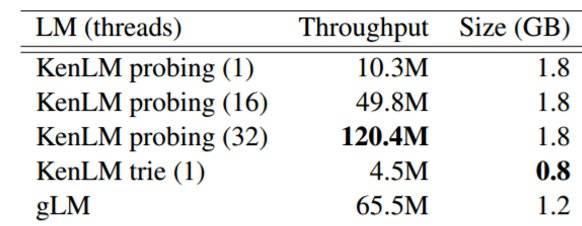
上表通过修改 KenLM 的线程数而对这两个模型进行了比较。当 KenLM 的表现优于 gLM 时,CPU 的成本也更高(3500 比 1000),所以从经济角度看,gLM 在这一实验中更优。
B-tree 节点大小的影响
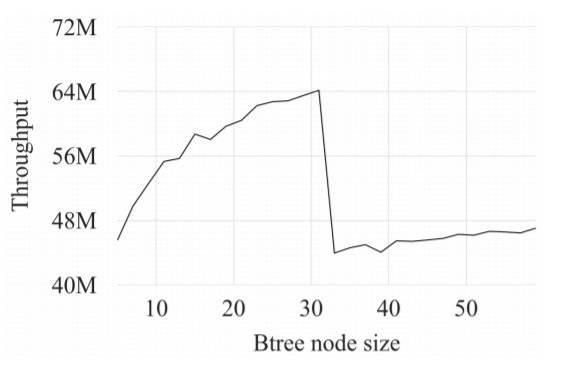
随着节点增大,吞吐量(每秒的 n-gram 查询)也会增大,直到达到 33 的节点大小,接着吞吐量陡然下降。
使 GPU 饱和
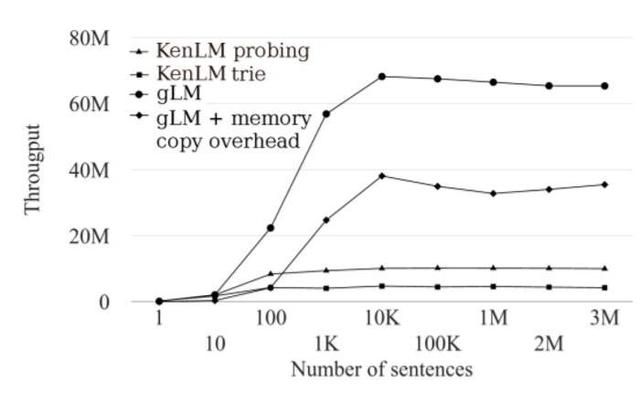
这一实验比较了吞吐量随批大小的变化情况,以观察我们何时能使 GPU 饱和,以充分利用 GPU。
模型大小和 N-gram 顺序对性能的影响
第四个实验展示了不同语言模型大小下的性能(吞吐量)。
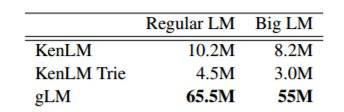
第五个实验展示了不同 n-gram 顺序下的性能(吞吐量)。
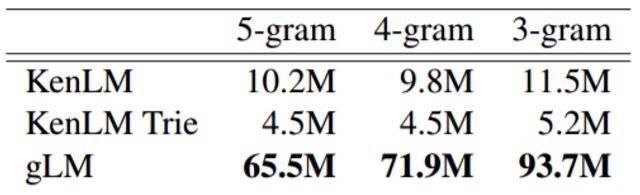
此外,这篇论文还通过改变内存类型验证了 gLM 的计算限制,但语言模型通常受 CPU 上的内存限制。
总结和个人看法
这篇论文为我们展现了一个新领域:探索 GPU 上的基本数据结构。因为 GPU 和 CPU 之间的差异,高效利用 GPU 是非常重要的。这篇论文认为,gLM 模型并没有在真实的机器翻译系统上实现。因为 NMT 通常运行在 GPU 上,所以这可能是一个提升 NMT 的好方法。