为什么80%的码农都做不了架构师?>>> 
一、Spark集成ElasticSearch的设计动机
ElasticSearch 毫秒级的查询响应时间还是很惊艳的。其优点有:
1. 优秀的全文检索能力
2. 高效的列式存储与查询能力
3. 数据分布式存储(Shard 分片)
相应的也存在一些缺点:
1. 缺乏优秀的SQL支持
2. 缺乏水平扩展的Reduce(Merge)能力,现阶段的实现局限在单机
3. JSON格式的查询语言,缺乏编程能力,难以实现非常复杂的数据加工,自定义函数(类似Hive的UDF等)
Spark 作为一个计算引擎,可以克服ES存在的这些缺点:
1. 良好的SQL支持
2. 强大的计算引擎,可以进行分布式Reduce
3. 支持自定义编程(采用原生API或者编写UDF等函数对SQL做增强)
所以在构建即席多维查询系统时,Spark 可以和ES取得良好的互补效果
二、Spark与ElasticSearch结合的架构和原理
ES-Hadoop无缝打通了ES和Hadoop两个非常优秀的框架,我们既可以把HDFS的数据导入到ES里面做分析,也可以将es数据导出到HDFS上做备份,归档,其中值得一提的是ES-Hadoop全面的支持了Spark框架,其中包括Spark,Spark Streaming,Spark SQL,此外也支持Hive,Pig,Storm,Cascading,当然还有标准的MapReduce,无论用那一个框架集成ES,都是非常简洁的。最后还可以使用Kibana提供的可视化的数据分析一条龙服务,非常棒的组合
整个数据流转图如下

而我们今天要介绍的,就是使用ES-Hadoop里面的ES-Spark插件,来完成使用spark向ES里面大批量插入数据和加载数据。
三、集群的硬件配置
Spark集群含有3个节点,FEA-spk和Spark集群的交互采用yarn-client。
| 主机 |
cpu |
mem |
disk |
| 10.68.23.89 |
1200MHZ*8 |
50g |
400g |
| 10.68.23.90 |
1200MHZ*8 |
50g |
400g |
| 10.68.23.91 |
1200MHZ*8 |
50g |
400g |
四、写入elasticsearch的数据介绍
elasticsearch副本数量是2个,每一个副本的大小是216.4g
数据的条数为88762914,字段的个数73个
五、FEA-spk写入ElasticSearch的原语实现
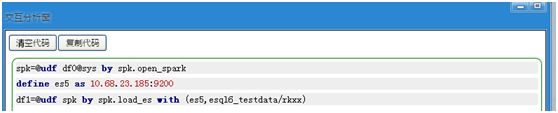
(1) 创建spk的连接
(2) 创建ElasticSearch的连接

(3) 加载数据到es中
数据的格式如下表所示

(4) 查看一下df1表的前十行


(5)将df1表的数据写回到ES里面,其中spark是index,people是type
![]()
由于数据量比较大,所以我们选择后台运行

进入spark web界面,查看运行情况
![]()
我们可以看到花费了2.3小时,如果对集群的资源和参数优化,时间可能会更短
六、Spark写回数据到ES的性能计算
每秒处理的数据条数=总条数/总时间=88762914/(2.5*60*60)=9863条
每条记录的大小=总大小/总条数=216.4*1024*1024k/88762914=3K
每秒能写多少兆=每秒处理的数据条数*每条记录的大小/1024=9863*3/1024=29M
七、FEA-spk结合ES适用的场景
不会使用Spark,想使用Spark分析存放在ES中的数据,把结果写入到ES里面,FEA-spk是一个不错的选择。