最近公司项目周期比较赶, 项目是软硬结合,在缺少硬件的情况下,通过接口模拟设备上下架和购买情况,并进行压力测试,
本次主要使用三个接口 分别是3个场景: 生成商品IP, 对商品进行上架, 消费者购买商品
最大问题:是数据库是用ssh,只能用127.0.0.1去链接数据库,
试过用ssh链接数据库, 用requests 去跑脚本没有问题,换上locust 就有问题
最后使用putty作为代理链接 ,有个缺陷就是 链接时效性不强,经常要重新链接putty
环境:
win10 mysql locust python3.7
1.locust:
Locust是一个用于可扩展的,分布式的,性能测试的,开源的,用Python编写框架/工具,它非常容易使用,也非常好学。
它的主要思想就是模拟一群用户将访问你的网站。每个用户的行为由你编写的python代码定义,同时可以从Web界面中实时观察到用户的行为。
Locust完全是事件驱动的,因此在单台机器上能够支持几千并发用户访问。
与其它许多基于事件的应用相比,Locust并不使用回调,而是使用gevent,而gevent是基于协程的,可以用同步的方式来编写异步执行的代码。
每个用户实际上运行在自己的greenlet中。
2. 安装
pip install locust
安装 pyzmq
If you intend to run Locust distributed across multiple processes/machines, we recommend you to also install pyzmq.
如果打算运行Locust 分布在多个进程/机器,需要安装pyzmq.
通过pip命令安装。
pip install pyzmq
3.Locust主要由下面的几个库构成:
1) gevent
gevent是一种基于协程的Python网络库,它用到Greenlet提供的,封装了libevent事件循环的高层同步API。
2) flask
Python编写的轻量级Web应用框架。
3) requests
Python Http库
4) msgpack-python
MessagePack是一种快速、紧凑的二进制序列化格式,适用于类似JSON的数据格式。msgpack-python主要提供MessagePack数据序列化及反序列化的方法。
5) six
Python2和3兼容库,用来封装Python2和Python3之间的差异性
6) pyzmq
pyzmq是zeromq(一种通信队列)的Python绑定,主要用来实现Locust的分布式模式运行
当我们在安装 Locust 时,它会检测我们当前的 Python 环境是否已经安装了这些库,如果没有安装,它会先把这些库一一装上。并且对这些库版本有要求,有些是必须等于某版本,有些是大于某版本。我们也可以事先把这些库全部按要求装好,再安装Locust时就会快上许多
4. 脚本解读:
1、创建ScriptTasks()类继承TaskSet类: 用于定义测试业务。 2、创建index()、about()、demo()方法分别表示一个行为,访问http://example.com。用@task() 装饰该方法为一个任务。1、2表示一个Locust实例被挑选执行的权重,数值越大,执行频率越高。在当前ScriptTasks()行为下的三个方法得执行比例为2:1:1 3、WebsiteUser()类: 用于定义模拟用户。 4、task_set : 指向一个定义了的用户行为类。 5、host: 指定被测试应用的URL的地址 6、min_wait : 用户执行任务之间等待时间的下界,单位:毫秒。 7、max_wait : 用户执行任务之间等待时间的上界,单位:毫秒。
5.执行脚本:
web/UI 界面:
if __name__ == '__main__': import os os.system("locust -f godemo.py --host=http://xx.api.xxxxx.net")
或者在命令行:
locust -f godemo.py --host=http:xxx.xxx.xx.net
或者:
locust -f godemo.py --H=http:xxx.xxx.xx.net
no-web:
dos进入Scripts目录下,执行 locust -f ****.py --csv=onetest --host=http://0.0.0.0:0000 --no-web -c10 -r10 -t2
(PS:-f 指定运行的py文件的名字,--csv 生成报告的名字,--host 测试的http服务的ip和port,--no-web 不用web启动,-c 设置虚拟用户数, -r 设置每秒启动虚拟用户数, -t 设置运行时间)
下面是脚本:
创建一个方法保存在goconn,从数据库读取数据传入请求:
import pymysql from sshtunnel import SSHTunnelForwarder import random def conn(): #本地通过putty链接数据库,在链接跳板机 lcDB = pymysql.connect(host="127.0.0.1",port=8807, user="rt",passwd="qwqwqw12",db="go") cur = lcDB.cursor() #随机生成一个数字,作为查询的结果的结果数 num = random.randint(0,10) sql = "select no from goods where operator_id =%s order by rand() limit %s"%(11, num) print(sql) rfid = [] try: cur.execute(sql) data = cur.fetchall() for row in data: good_no = row[0] rfid.append(good_no) # print(good_no) return rfid except: print("Error") finally: #关闭连接 lcDB.close()
请求:
import goconnfrom locust import HttpLocust,TaskSet,task class goDemo(TaskSet): def getRfid(self): gID = goconn.conn() data = { "goods_no[]": gID, "num": 1, } print("2") r = self.client.post("/test/api/XXX", data=data) rfid = eval(r.content)["result"] print(rfid) return rfid def stock(self,did, oid, rfid): data = { "device_id": did, "operator_id": oid, "data[add][]": rfid, "data[remove][]": "", } result = self.client.post("/test/api/XX2", data= data) print(result.content) def purchase(self,did,uid,rfid): data = { "device_id":did, "user_id":uid, "data[]":rfid, } req = self.client.post("/test/api/XXX3", data = data) res =eval(req.content)["result"] print(req.content) @task(1) def test_getrfid(self): self.getRfid() @task(3) def test_stock(self): rfid = self.getRfid() self.stock(28,11,rfid) @task(7) def test_purchase(self): rfid = self.getRfid() self.stock(28,11,rfid) self.purchase(28,172,rfid) class WebsiteUser(HttpLocust): task_set = goDemo min_wait = 3000 max_wait = 5000
测试结果:
Number of users to simulate:设置模拟的用户总数,
Hatch rate (users spawned/second):每秒启动的虚拟用户数 ,
Start swarming:执行locust脚本
UI界面:运行200个, 每秒启动2个用户:

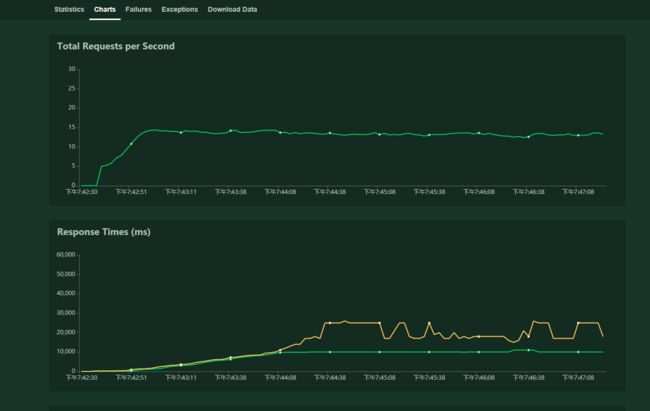
参考文章:
http://www.pianshen.com/article/6404330705/
关于性能好文章:
https://www.cnblogs.com/botoo/p/7410283.html
设计locust:
参数化 ,关联等:
http://www.cnblogs.com/ailiailan/p/9474973.html