http://www.toutiao.com/a6475623583879004685/?tt_from=weixin&utm_campaign=client_share&app=news_article_social&utm_source=weixin&iid=15964468510&utm_medium=toutiao_ios&wxshare_count=1
随着公司业务的增长,大量和业务、流程、规则相关的半结构化数据也爆发式增长。但数据分散在公司的各个系统中,如何将它们汇总并形成统一的企业级数据仓库,使企业灵活,高效的运用成了难题。
如需将分散的各个底层数据汇总则需建立完整的体系,支撑风控的大数据框架则是重中之重。
拥有5000万+注册用户;13亿+设备标签;100亿+行为数据;1500万+行业关注名单等海量多维数据的拍拍信则是从这几个方面落实:
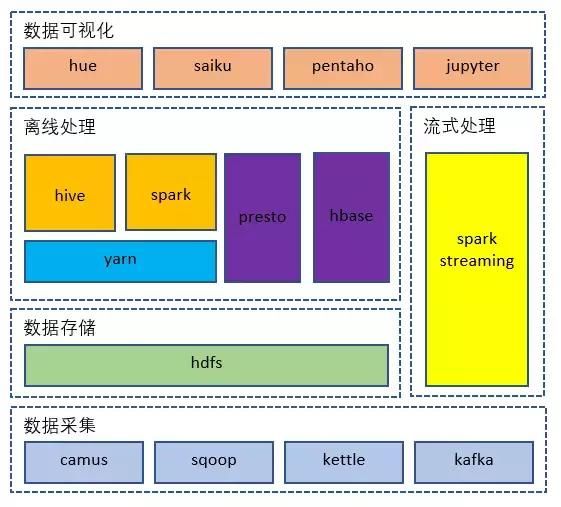
1. 数据采集
面对来源各异、以结构化/半结构化为主的数据,我们使用linkedin开源的camus来采集消息类数据,使用kettle来采集RMDB的数据。
2. 数据储存
将采集到的原始数据存储到hadoop集群的分布式文件系统中。此外,基于hdfs文件系统对小文件并不是很友好的前提下,定期对历史文件进行合并、压缩、归档的操作也很有必要。
3. 离线处理
数据的离线处理则是一个非常大的话题,相当多的工作量都在这里,但它的价值却往往不会马上得到体现,从而被企业忽视。不仅仅包含以下这些内容:
l 构建并不停地丰富数据仓库
参照传统的ODS,DW,DM将数仓分层,对数据进行加密、去重后分门别类,持续不断的坚持做这件事。
l 管理元数据
建立数据字典,统一数据编码,描绘数据血缘等。
l 检测数据质量
从众数、少数、中位数、平均值等多维度来检测和把握数据的质量。
4. 流式处理
我们使用spark streaming将特征工程、模型结果计算与流式处理相结合,提供秒级的输出。甚至成功的将类似RNN(循环神经网络)这样的深度学习计算添加到整个流式处理的过程中。
5. 数据可视化
使用不同的工具以满足不同场景、不同职责的人员对数据的使用。不仅仅包含以下这些内容:
l 数据的即席查询
懂SQL、随意组合查询条件,进行自助查询,可以忍受分钟级的耗时。
l 多维分析
不懂SQL的情况下,在给定的维度和指标下,随意组合,并在秒级得到查询结果。
l 静态报表
只关注关键性指标。
l 数据分析挖掘
会使用像python、R这样的语言,结合集群的Spark、hive这样的分布式处理工具,对数据进行更深层次的利用。
经过处理的底层大数据相对于以往,在实际业务中使源数据种类更丰富,数据量更多, 借助集群的助力,处理速度更快,回溯时间更久远。
实际运用:
模型训练:风控模型是互联网金融,传统金融等行业在风控流程中不可或缺的环节。
模型应用:将模型与流式计算相结合,提供秒级的风控决策。
数据产品:对数据加工处理,产生像多头、风险名单一类的数据产品。
常用业务:企业在日常工作中各个环节都涉及到数据如:处理数据,更新数据,数据调用,查询日志等。
运用大数据架构前后比对:
| 项目 |
前 |
后 |
| 数据体量 |
GB级 |
TB ~ PB级 |
| 响应时效 |
h级 |
ms ~ min级 |
| 回溯 |
日/月 |
年 |
| 成本 |
反复人工成本 |
一次投入,多方使用 |
在进行大数据框架搭建时还需注意以下几点:
现在即使在同一细分领域,也有很多开源技术可供选择,请尽量选用相对成熟,社区活跃的;能选用开源的,尽量避免自研;另外代码如果要维护自己分支,请特别要谨慎,避免与社区越走越远;hadoop最初并没有太多的考虑数据安全方面,这点要自己加强;高稳定性和高性能往往一个是鱼,一个是熊掌,请考虑好取舍。
本期对大数据底层架构的分享就到这里,欢迎大家联系探讨。