李航《统计学习方法》——第六章逻辑回归和最大熵模型笔记及理解+习题
文章目录
- 1 模型
- 1.1 二项逻辑回归模型
- 1.1.1 逻辑斯蒂分布
- 1.1.2 线性模型
- 1.1.3 二项逻辑回归模型
- 角度一
- 角度二
- 1.1.4 多项逻辑回归
- 1.1.5 逻辑回归形象化理解
- 1.2 最大熵模型
- 1.2.1 最大熵原理
- 1.2.2 最大熵模型的定义
- 2 策略
- 2.1 二项逻辑回归模型
- 2.2 最大熵模型的学习
- 3 算法
- 逻辑回归的Python实现
- 补充
- 最大熵模型和逻辑回归模型的关系
- 最大熵模型的优缺点
- 4 习题
1 模型
1.1 二项逻辑回归模型
1.1.1 逻辑斯蒂分布
连续随机变量X服从逻辑斯蒂分布时,具有以下分布函数和概率密度函数: F ( x ) = P ( X < x ) = 1 1 + e − ( x − μ ) / γ f ( x ) = F ′ ( x ) = e − ( x − μ ) / γ γ ( 1 + e − ( x − μ ) / γ ) 2 γ 为 形 状 参 数 , μ 为 位 置 参 数 F(x) = P(X<x) = \frac{1}{1+e^{-(x-\mu)/\gamma}} \\ f(x) = F'(x) = \frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2} \quad \gamma 为形状参数,\mu为位置参数 F(x)=P(X<x)=1+e−(x−μ)/γ1f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γγ为形状参数,μ为位置参数一般在讨论逻辑回归模型的时候采用最简单的形式,即参数都等于1.即 F ( x ) = 1 1 + e − x F(x) = \frac{1}{1+e^{-x}} F(x)=1+e−x1
1.1.2 线性模型
f ( x ) = w ⋅ x ( w ∈ R n + 1 , x ∈ R n + 1 ) f(x) = w\cdot x\quad (w\in R^{n+1} ,x\in R^{n+1}) f(x)=w⋅x(w∈Rn+1,x∈Rn+1),n 表示特征个数。
根据最小化均方差则 w ∗ = a r g m i n w ( y − w ⋅ x ) T ( y − w ⋅ x ) w^* = argmin_w (y-w\cdot x)^T(y-w\cdot x) w∗=argminw(y−w⋅x)T(y−w⋅x),
根据矩阵关系对 w w w求导,并令导数等于0,则 w ∗ = ( x T x ) T x T y w^* = (x^Tx)^Tx^Ty w∗=(xTx)TxTy,
这个最优解需要满足 x T x x^Tx xTx满秩,也就是需要特征的数量小于样本的个数如果不是,需要做一些其他的处理。
为方便,所有的线性模型均使用扩展 w w w和 x x x的 f ( x ) = w ⋅ x f(x) = w\cdot x\quad f(x)=w⋅x表示
1.1.3 二项逻辑回归模型
线性回归是逻辑斯蒂回归的基础,线性回归是真正的连续值的回归问题,逻辑回归得到的是概率值,解决的是二分类问题。
- 得到的概率值没有任何物理含义。
- 可以推广到多分类问题
我一直以来的理解是,逻辑回归与线性回归的区别在于,线性回归不满足一些特定问题(非线性),使用sigmoid()函数对线性回归的结果做一个变换,可以得到两个类别的概率。神经网络里面会考虑神经元是否激活,可以认为是二分类问题,因此常用的激活函数有sigmoid()对神经元的输出做变换,确定神经元是否被激活。
角度一
也就是我理解的角度,逻辑回归模型就是 h ( x ) = s i g m o i d ( f ( x ) ) = F ( w ⋅ x ) = 1 1 + e − w ⋅ x h(x) = sigmoid(f(x)) = F(w\cdot x) = \frac{1}{1+e^{-w\cdot x}} h(x)=sigmoid(f(x))=F(w⋅x)=1+e−w⋅x1其中 w ⋅ x w\cdot x w⋅x的值域是 R R R, s i g m o i d ( ) sigmoid() sigmoid()函数的值域是[0,1],可以知道,线性模型的输出越接近无穷,概率值越接近1,线性模型的输出接近负无穷,则概率值越接近0.
假设:
P ( y = 1 ∣ x ) = 1 1 + e − w ⋅ x = e w ⋅ x 1 + e w ⋅ x = ϕ ( x ) P (y=1|x) = \frac{1}{1+e^{-w\cdot x}} = \frac{e^{w\cdot x}}{1+e^{w\cdot x}} = \phi(x) P(y=1∣x)=1+e−w⋅x1=1+ew⋅xew⋅x=ϕ(x),则 P ( y = 0 ∣ x ) = 1 − 1 1 + e − w ⋅ x = 1 1 + e w ⋅ x = 1 − ϕ ( x ) P (y=0|x) =1- \frac{1}{1+e^{-w\cdot x}} = \frac{1}{1+e^{w\cdot x}} =1- \phi(x) P(y=0∣x)=1−1+e−w⋅x1=1+ew⋅x1=1−ϕ(x),那么整个数据集的准确率也就是似然函数可以写为: l ( x ) = ∏ i = 1 N [ ϕ ( x i ) ] y i [ 1 − ϕ ( x i ) ] 1 − y i l(x) = \prod_{i=1}^N[\phi(x_i)]^{y_i}[1-\phi(x_i)]^{1-y_i} l(x)=i=1∏N[ϕ(xi)]yi[1−ϕ(xi)]1−yi,为方便计算取对数似然函数为: L ( x ) = ∑ i = 1 N [ y i l o g ϕ ( x i ) 1 − ϕ ( x i ) + l o g ( 1 − ϕ ( x i ) ) ] = ∑ i = 1 N [ y i ( w ⋅ x i ) − l o g ( 1 + e w ⋅ x i ) ] L(x) = \sum_{i=1}^N[y_ilog\frac{\phi(x_i)}{1-\phi(x_i)}+log(1-\phi(x_i))]\\ = \sum_{i=1}^N[y_i(w \cdot x_i )-log(1+e^{w\cdot x_i})] L(x)=i=1∑N[yilog1−ϕ(xi)ϕ(xi)+log(1−ϕ(xi))]=i=1∑N[yi(w⋅xi)−log(1+ew⋅xi)]那么需要最大化似然函数 L L L求解参数 w w w. w w w是线性回归的拟合系数,所以逻辑回归实质是根据训练数据对分类边界线建立合适的回归公式。
角度二
统计学习方法首先从逻辑回归模型的定义出发,即已知 P ( y = 1 ∣ x ) = 1 1 + e − w ⋅ x = e w ⋅ x 1 + e w ⋅ x = ϕ ( x ) P (y=1|x) = \frac{1}{1+e^{-w\cdot x}} = \frac{e^{w\cdot x}}{1+e^{w\cdot x}} = \phi(x) P(y=1∣x)=1+e−w⋅x1=1+ew⋅xew⋅x=ϕ(x), P ( y = 0 ∣ x ) = 1 − 1 1 + e − w ⋅ x = 1 1 + e w ⋅ x = 1 − ϕ ( x ) P (y=0|x) =1- \frac{1}{1+e^{-w\cdot x}} = \frac{1}{1+e^{w\cdot x}} =1- \phi(x) P(y=0∣x)=1−1+e−w⋅x1=1+ew⋅x1=1−ϕ(x),从这个公式出发得到逻辑回归模型与线性模型的关系。
一个事件的几率是指该事件发生的概率和不发生的概率的比值,如果一个事件发生的概率是p,那么该事件的几率是 p 1 − p \frac{p}{1-p} 1−pp.
所以以逻辑回归模型的定义得到正样本的概率是 ϕ ( x ) \phi(x) ϕ(x),负样本的概率是 1 − ϕ ( x ) 1-\phi(x) 1−ϕ(x),那么该事件的几率是 ϕ ( x ) 1 − ϕ ( x ) = e w ⋅ x \frac{\phi(x)}{1-\phi(x)}=e^{w\cdot x} 1−ϕ(x)ϕ(x)=ew⋅x,如果取对数几率,就可以得到 l o g ( ϕ ( x ) 1 − ϕ ( x ) ) = w ⋅ x log(\frac{\phi(x)}{1-\phi(x)})=w\cdot x log(1−ϕ(x)ϕ(x))=w⋅x.也就是说,在逻辑回归中,输出 y = 1 y=1 y=1的对数几率是输入 x x x的线性函数。
1.1.4 多项逻辑回归
推广到多项逻辑回归,用于多分类。 P ( y = k ∣ x ) = e x p ( w k ⋅ x ) 1 + ∑ k = 1 K − 1 e x p ( w k ⋅ x ) P ( y = K ∣ x ) = 1 1 + ∑ k = 1 K − 1 e x p ( w k ⋅ x ) P(y=k|x) = \frac{exp(w_k\cdot x)}{1+\sum_{k=1}^{K-1}exp(w_k\cdot x)}\\P(y=K|x) = \frac{1}{1+\sum_{k=1}^{K-1}exp(w_k\cdot x)} P(y=k∣x)=1+∑k=1K−1exp(wk⋅x)exp(wk⋅x)P(y=K∣x)=1+∑k=1K−1exp(wk⋅x)1其中 x ∈ R n + 1 , w k ∈ R n + 1 , y ∈ 1 , 2 , ⋯ , K x\in R^{n+1},w_k\in R^{n+1},y\in {1,2,\cdots,K} x∈Rn+1,wk∈Rn+1,y∈1,2,⋯,K,参数估计可以由逻辑回归推广得到。
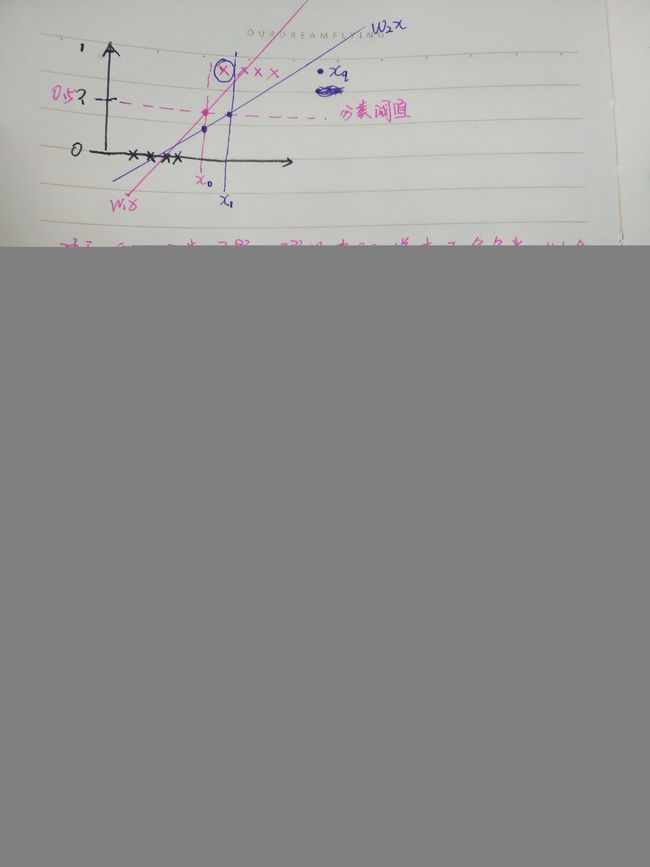
1.1.5 逻辑回归形象化理解
1.2 最大熵模型
统计学习方法很多时候在过渡,联系上不太详细。这里我认为最大熵模型是逻辑回归的推广,两者都可以用于二分类和多分类,那么推广的点在于什么呢?参考两者的公式可以认为,最大的不同在于特征函数的引入,这就使最大熵模型更加严谨。两者具有一定的等价性,但是是从不同的角度看待问题的。
1.2.1 最大熵原理
最大熵原理是统计学中的一个概念,《数学之美》中对最大熵模型的概念举的是关于投资的例子,就是平常我们说的不要把鸡蛋放在一个篮子里,均分一下熵才比较大嘛。
简单一点说就是,保留全部的不确定性,将风险降到最小。复杂一点,对于一个随机事件的概率分布进行预测时,预测应当满足全部已知的条件,而对未知情况不要做任何主观假设,在这种情况下,概率分布最均匀,预测的风险最小。
举例来说,如果假设随机变量X有5个取值 A , B , C , D , E {A,B,C,D,E} A,B,C,D,E,要估计取格格之的概率P(A),P(B),P©,P(D),P(E)。如果没有先验条件,那么每个取各个值的概率均匀分布时熵最大,也就是如果有五只基金,对此一无所知,那么平均投资可以使得风险最小。但是如果已知 P ( A ) + P ( B ) = 3 5 P(A)+P(B)=\frac{3}{5} P(A)+P(B)=53,那么需要先满足这个条件,然后其他的几个随机变量均匀分布才可以得到最大熵。
1.2.2 最大熵模型的定义
【1】【2】延伸引入,【3】结合找到等价关系也就是条件。
【1】给定训练数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) T={(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)} T=(x1,y1),(x2,y2),⋯,(xN,yN),可以确定联合分布和边缘分布的经验分布[经验分布:关于样本点的额累计分布函数估计],分别用 P ~ ( X , Y ) , P ~ ( X ) \widetilde{P}(X,Y),\widetilde{P}(X) P (X,Y),P (X)表示。 P ~ ( X , Y ) = v ( X = x , Y = y ) N P ~ ( X ) = x ( X = x ) N \widetilde{P}(X,Y) = \frac{v(X=x,Y=y)}{N} \\ \widetilde{P}(X) = \frac{x(X=x)}{N} P (X,Y)=Nv(X=x,Y=y)P (X)=Nx(X=x)其中 v ( ) v() v()表示样本出现的频数, N N N表示样本容量。
【2】特征函数: f ( x , y ) f(x,y) f(x,y)描述输入x,输出y之间的某一个事实。【特征函数可以是任何实值函数】 f ( x , y ) = { 1 , 如 果 y = y 0 且 x = x 0 0 , o t h e r w i s e f(x,y) = \left\{ \begin{aligned} 1,\quad 如果y=y_{0} 且 x=x_0\\ 0,\quad\quad\quad\quad otherwise \\ \end{aligned} \right. f(x,y)={1,如果y=y0且x=x00,otherwise 事实这个词让我懵逼了很久,可以理解为用来表示 x的某个取值和y的某个取值是否存在联合分布。如果复杂一点,可以表示如果满足哪几个特征才会为1,也就是特征之间符合什么关系为1,主要还是要看特征函数里面怎么定义的,而这些值统计出来的就是满足这个特征函数的特征值。这样的定义有一个问题,就是模型几乎没有泛化能力。
【3】特征函数关于经验分布 P ~ ( X , Y ) \widetilde{P}(X,Y) P (X,Y)的期望值,用 E P ~ ( f ) E_{\widetilde{P}}(f) EP (f)表示。 E P ~ ( f i ) = ∑ x , y P ~ ( x , y ) f ( x , y ) E_{\widetilde{P}}(f_i) = \sum_{x,y} \widetilde{P}(x,y)f(x,y) EP (fi)=x,y∑P (x,y)f(x,y)特征函数关于模型 P ( Y ∣ X ) P(Y|X) P(Y∣X)与经验分布 P ~ ( X ) \widetilde{P}(X) P (X)的期望值,用 E P ( f ) E_{P}(f) EP(f)表示。 E P ( f i ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f ( x , y ) E_{P}(f_i) = \sum_{x,y} \widetilde{P}(x)P(y|x)f(x,y) EP(fi)=x,y∑P (x)P(y∣x)f(x,y) 如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等。以此作为模型学习的条件,如果有n个特征函数就有n个约束条件。
根据贝叶斯定理,如果不考虑符号的问题,这两个期望值是相等的。如果考虑符号,根据训练集计算,只有模型P(y|x)是未知的,也就是在计算条件熵时候的未知量,对这个未知量进行期望值相等约束,就成为一个约束最优化问题了。
定义: 假设满足所有约束条件的模型集合为 C = { P ∈ ℜ ∣ E p ( f i ) = E P ~ ( f i ) , i = 1 , 2 , ⋯ , n } C = \{P\in \Re | E_p(f_i) = E_{\widetilde{P}}(f_i),i=1,2,\cdots,n\} C={P∈ℜ∣Ep(fi)=EP (fi),i=1,2,⋯,n},定义在条件概率分布P(Y|X)上的条件熵为: H ( P ) = − ∑ x , y P ~ P ( y ∣ x ) l o g P ( y ∣ x ) H(P) = -\sum_{x,y}\widetilde{P}P(y|x)logP(y|x) H(P)=−x,y∑P P(y∣x)logP(y∣x)则模型集合C中条件熵最大的模型成为最大熵模型,对数为自然对数。
集合C就是解决分类的问题的区间,也就是要满足在该区间上进行求解,满足该区间的条件。
2 策略
2.1 二项逻辑回归模型
最大化对数似然函数,即 L ( x ) = ∑ i = 1 N [ y i l o g ϕ ( x i ) 1 − ϕ ( x i ) + l o g ( 1 − ϕ ( x i ) ) ] = ∑ i = 1 N [ y i ( w ⋅ x i ) − l o g ( 1 + e w ⋅ x i ) ] L(x) = \sum_{i=1}^N[y_ilog\frac{\phi(x_i)}{1-\phi(x_i)}+log(1-\phi(x_i))]\\ = \sum_{i=1}^N[y_i(w \cdot x_i )-log(1+e^{w\cdot x_i})] L(x)=i=1∑N[yilog1−ϕ(xi)ϕ(xi)+log(1−ϕ(xi))]=i=1∑N[yi(w⋅xi)−log(1+ew⋅xi)]
2.2 最大熵模型的学习
对于给定的训练数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) T={(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)} T=(x1,y1),(x2,y2),⋯,(xN,yN),以及特征函数 f i ( x , y ) f_i(x,y) fi(x,y), i = 1 , 2 , ⋯ , n i=1,2,\cdots,n i=1,2,⋯,n,最大熵模型等价于约束最优化问题: m a x p ∈ C H ( P ) = − ∑ x , y P ~ P ( y ∣ x ) l o g P ( y ∣ x ) s . t . E p ( f i ) = E P ~ ( f i ) i = 1 , 2 , ⋯ , n ∑ y P ( y ∣ x ) = 1 max_{p\in C}\quad H(P) = -\sum_{x,y}\widetilde{P}P(y|x)logP(y|x) \\ s.t. \quad E_p(f_i) = E_{\widetilde{P}}(f_i)\quad i=1,2,\cdots,n \\ \sum_y P(y|x) = 1 maxp∈CH(P)=−x,y∑P P(y∣x)logP(y∣x)s.t.Ep(fi)=EP (fi)i=1,2,⋯,ny∑P(y∣x)=1转换成标准的最优化问题形式就是: m i n p ∈ C − H ( P ) = ∑ x , y P ~ P ( y ∣ x ) l o g P ( y ∣ x ) s . t . E p ( f i ) − E P ~ ( f i ) = 0 i = 1 , 2 , ⋯ , n ∑ y P ( y ∣ x ) = 1 min{p\in C}\quad -H(P) = \sum_{x,y}\widetilde{P}P(y|x)logP(y|x) \\ s.t. \quad E_p(f_i) - E_{\widetilde{P}}(f_i) = 0 \quad i=1,2,\cdots,n \\ \sum_y P(y|x) = 1 minp∈C−H(P)=x,y∑P P(y∣x)logP(y∣x)s.t.Ep(fi)−EP (fi)=0i=1,2,⋯,ny∑P(y∣x)=1约束优化问题可以转化为无约束优化问题的对偶问题,使用拉格朗日函数,将原始问题转化为对偶问题,这里需要证明原问题与对偶问题的等价性,这里直接给出问题的结果。 L ( P , w ) = m i n P ∈ C [ − H ( P ) + w 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n w i ( E p ( f i ) − E P ~ ( f i ) ) ] = ∑ x , y P ~ ( x ) P ( y ∣ x ) l o g P ( y ∣ x ) + w 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n w i [ ∑ x , y P ~ ( x , y ) f i ( x , y ) − ∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) ] L(P,w) = min{P\in C} [-H(P) + w_0(1-\sum_yP(y|x))+\sum_{i=1}^nw_i(E_p(f_i) - E_{\widetilde{P}}(f_i) )] \\ = \sum_{x,y}\widetilde{P}(x)P(y|x)logP(y|x)+w_0(1-\sum_yP(y|x)) \\ +\sum_{i=1}^nw_i[\sum_{x,y}\widetilde{P}(x,y)f_i(x,y)-\sum_{x,y}\widetilde{P}(x)P(y|x)f_i(x,y)] L(P,w)=minP∈C[−H(P)+w0(1−y∑P(y∣x))+i=1∑nwi(Ep(fi)−EP (fi))]=x,y∑P (x)P(y∣x)logP(y∣x)+w0(1−y∑P(y∣x))+i=1∑nwi[x,y∑P (x,y)fi(x,y)−x,y∑P (x)P(y∣x)fi(x,y)]原始问题 m i n P ∈ C m a x w L ( P , w ) w min_{P\in C} max_{w}L(P,w) \quad w minP∈CmaxwL(P,w)w 表示拉格朗日乘子,是个向量。对偶问题 m a x w m i n P ∈ C L ( P , w ) max_{w} min{P\in C}L(P,w) maxwminP∈CL(P,w), ϕ ( w ) = m i n P ∈ C L ( P , w ) \phi(w) = min{P\in C}L(P,w) ϕ(w)=minP∈CL(P,w)最大化可以得到 P w ( y ∣ x ) = Z w ( x ) = ∑ y e x p ( ∑ i = 1 n w i f i ( x , y ) ) Z w ( x ) = ∑ y e x p ( ∑ i = 1 n w i f i ( x , y ) ) 是 规 范 化 因 子 P_w(y|x) = Z_w(x) = \sum_y exp(\sum_{i=1}^{n}w_if_i(x,y)) \\ Z_w(x) = \sum_yexp(\sum_{i=1}^{n}w_if_i(x,y)) 是规范化因子 Pw(y∣x)=Zw(x)=y∑exp(i=1∑nwifi(x,y))Zw(x)=y∑exp(i=1∑nwifi(x,y))是规范化因子然后再求解对偶问题外部的极大化 m a x ϕ ( w ) max\phi(w) maxϕ(w)。 w ∗ = a r g m a x w ϕ ( w ) w* = argmax_w\phi(w) w∗=argmaxwϕ(w),这时可以利用最优化算法来求解最优的拉格朗日乘子。
即 P w ( y ∣ x ) , Z w ( x ) P_w(y|x),Z_w(x) Pw(y∣x),Zw(x)可以利用训练数据和拉格朗日乘子w来表示,最后化成只含有w的最大化优化问题,使用常用的优化算法即可求解。具体求导过程参看统计学习方法第六章。
3 算法
这里可以涉及很多工程优化的算法,例如最小梯度,牛顿,拟牛顿法,DFP算法,改进的迭代尺度算法(IIS)【专用最大熵问题求解算法】等。
这里就不复习了,关键是找到变量的迭代步长和搜索方向,步长一般使用一维搜索方法求解,各个优化算法的不同则在于搜索方向的变化。
逻辑回归的Python实现
# -*- coding: utf-8 -*-
from numpy import *
## 机器学习实战,直接使用两维进行数据导入,但是特征可能有很多维,这里有一些改动
##并且x进行了维度扩展,第一列全为1,也就是将回归问题的w,b合并到一起了
def flatten_list(nested):
if isinstance(nested, list):
for sublist in nested:
for item in flatten_list(sublist):
yield float(item)
else:
yield nested
def loadData(filename):
dataDat = [];labels = [];
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split()
dataDat.append(list(flatten_list([1.0,lineArr[0:-1:1]])))
labels.append(int(lineArr[-1]))
return dataDat,labels
def sigmoid(z):
return 1.0/(1+exp(-z))
'''
梯度上升算法,每次更新权重需要遍历整个数据集
整个矩阵求导 可得 关于w的导入为 X^T*Y-X^T*H = X^T*(Y-H)
(Y-H) 就是error
w 的更新公式就变为 w = w + alpha*X^T*error
'''
def gradAscend(dataSet,labels,alpha):
data = mat(dataSet)
labels = mat(labels).transpose()
epoches = 500 #最大迭代次数
m,n = shape(data)
weights = ones((n,1))
for i in range(epoches):
h = sigmoid(data*weights)
error = labels - h
weights = weights + alpha*data.transpose()*error
return weights
'''
随机梯度上升算法,有新的数据就会在线更新权重,不需要对整个数据集进行遍历
效果极差,因为只相当于遍历了一次数据集
'''
def stocGradAsend(dataSet,labels,alpha):
data = array(dataSet)
#data = dataSet
m,n = shape(data)
weights = ones(n)
for i in range(m):
h = sigmoid(sum(data[i]*weights))
error = labels[i] - h
weights = weights+alpha*error*data[i]
return weights
'''
改进
学习率变化,样本随机选取,
'''
def stocGradAsend(dataSet,labels,epoches=500):
data = array(dataSet)
#data = dataSet
m,n = shape(data)
weights = ones(n)
for i in range(epoches):
dataIndex = list(range(m))
for j in range(m):
alpha = 4/(1.0+i+j)+0.01
index = int(random.uniform(0,len(dataIndex)))
h = sigmoid(sum(data[index]*weights))
error = labels[index] - h
weights = weights+alpha*error*data[index]
del(dataIndex[index])
return weights
def plotBestFit(weights,filename):
import matplotlib.pyplot as plt
dataMat,labelMat=loadData(filename=filename)
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
def main():
filename = 'testSet.txt'
dataDat,labels = loadData(filename)
weights = stocGradAsend(dataDat,labels)
plotBestFit(weights,filename)
return dataDat,labels,weights
if __name__ == "__main__":
dataDat,labels,weights = main()
补充
最大熵模型和逻辑回归模型的关系
把最大熵模型推导成 logistic 回归模型
将y限制为二元变量,同时特征函数 f ( x , y ) = { g ( x ) , 如 果 y = y 0 0 , 如 果 y = y 1 f(x,y) = \left\{ \begin{aligned} g(x),\quad 如果y=y_{0}\\ 0,\quad\quad\quad\quad 如果y=y_1 \\ \end{aligned} \right. f(x,y)={g(x),如果y=y00,如果y=y1g(x)表示就是sigmoid()函数,带入最大熵模型求解就是逻辑回归模型。
最大熵模型的优缺点
最大熵模型在分类方法里算是比较优的模型,但是由于它的约束函数的数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数优化求解的迭代过程非常慢,scikit-learn甚至都没有最大熵模型对应的类库。但是理解它仍然很有意义,尤其是它和很多分类方法都有千丝万缕的联系。
最大熵模型作为分类方法的优缺点:
最大熵模型的优点有:
a) 最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
b) 可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
最大熵模型的缺点有:
a) 由于约束函数数量和样本数目有关系,导致迭代过程计算量巨大,实际应用比较难。
4 习题
6.1确认逻辑斯蒂分布属于指数族分布
指数族分布,满足一下形式 P ( y ; η ) = b ( y ) e x p ( η T T ( y ) − a ( η ) ) P(y;\eta) = b(y)exp(\eta^TT(y)-a(\eta)) P(y;η)=b(y)exp(ηTT(y)−a(η))η被称为分布的自然参数(也称为规范参数)
T(y)是充分统计量(通常情况下有T(y)=y)
a(η)被称为对数划分函数。这一项本质上是起到了正则化常数的作用,确保了分布p(y;η)的总和或是积分在y到1上。
固定T,a和b,我们定义一族以η为参数的分布;随着η的变化,我们可以在这个族中得到不同的分布。
证明逻辑斯蒂分布属于指数族分布,关键是找到相应的T,a,b,使之满足以上形式。
对于线性回归,为方便讨论,使 w = [ w , b ] w = [w,b] w=[w,b],并将 x x x扩展最后一列为1,则 f ( x ) = w T x T f(x) = w^Tx^T f(x)=wTxT,引入逻辑回归之后,sigmoid函数作用在 f ( x ) f(x) f(x)上,最后的逻辑回归模型为: P ( y = 1 ∣ x ) = s i g m o i d ( f ( x ) ) = 1 1 + e − ( w T x T ) P(y=1|x) = sigmoid(f(x)) = \frac{1}{1+e^{-(w^Tx^T)}} P(y=1∣x)=sigmoid(f(x))=1+e−(wTxT)1 P ( y = 0 ∣ x ) = s i g m o i d ( f ( x ) ) = 1 − 1 1 + e − ( w T x T ) P(y=0|x) = sigmoid(f(x)) = 1-\frac{1}{1+e^{-(w^Tx^T)}} P(y=0∣x)=sigmoid(f(x))=1−1+e−(wTxT)1则逻辑回归模型为 P ( y ∣ x ) = P ( y = 1 ∣ x ) y P ( y = 0 ∣ x ) 1 − y = ( 1 1 + e − ( w T x T ) ) y ( 1 − 1 1 + e − ( w T x T ) ) 1 − y = e y l o g ( ϕ ) + ( 1 − y ) l o g ( ( 1 − ϕ ) ) ( 令 1 1 + e − ( w T x T ) = ϕ ) = e l o g ( ϕ 1 − ϕ ) y + l o g ( 1 − ϕ ) P(y|x) = P(y=1|x)^yP(y=0|x)^{1-y} \\ = (\frac{1}{1+e^{-(w^Tx^T)}})^y(1-\frac{1}{1+e^{-(w^Tx^T)}})^{1-y} \\ = e^{ylog(\phi)+(1-y)log((1-\phi))}\quad (令 \frac{1}{1+e^{-(w^Tx^T)}} =\phi ) \\ =e^{log(\frac{\phi}{1-\phi})y+log(1-\phi)} P(y∣x)=P(y=1∣x)yP(y=0∣x)1−y=(1+e−(wTxT)1)y(1−1+e−(wTxT)1)1−y=eylog(ϕ)+(1−y)log((1−ϕ))(令1+e−(wTxT)1=ϕ)=elog(1−ϕϕ)y+log(1−ϕ)令 T ( y ) = y , b = 1 , a = l o g ( 1 − ϕ ) = l o g ( 1 1 + e η ) T(y)=y,\quad b=1,\quad a = log(1-\phi) = log(\frac{1}{1+e^\eta}) T(y)=y,b=1,a=log(1−ϕ)=log(1+eη1)[ η = l o g ( ϕ 1 − ϕ ) 反 解 得 到 ϕ = e η 1 + e η \eta = log(\frac{\phi}{1-\phi}) 反解得到 \phi = \frac{e^\eta}{1+e^\eta} η=log(1−ϕϕ)反解得到ϕ=1+eηeη],然后解得 a a a。得证。
6.2 推导逻辑回归模型的梯度下降算法
上述2.1求得逻辑回归的最大似然函数为: L ( w ) = ∑ i = 1 N [ y i ( w ⋅ x i ) − l o g ( 1 + e x p ( w ⋅ x i ) ) ] L(w)=\sum_{i=1}^N[y_i(w{\cdot}x_i)-log(1+exp(w{\cdot}x_i))] L(w)=∑i=1N[yi(w⋅xi)−log(1+exp(w⋅xi))]
对w求导得 ∂ L ( w ) ∂ w = ∑ i = 1 N [ x i ⋅ y i − e x p ( w ⋅ x i ) ⋅ x i 1 + e x p ( w ⋅ x i ) ] \frac{ {\partial}L(w)}{ {\partial}w}=\sum_{i=1}^N[x_i{\cdot}y_i-\frac{exp(w{\cdot}x_i){\cdot}x_i}{1+exp(w{\cdot}x_i)}] ∂w∂L(w)=∑i=1N[xi⋅yi−1+exp(w⋅xi)exp(w⋅xi)⋅xi],w是个n维向量,n表示特征个数, ∇ L ( w ) = [ ∂ L ( w ) ∂ w ( 0 ) , . . . , ∂ L ( w ) ∂ w ( m ) ] {\nabla}L(w)=[\frac{ {\partial}L(w)}{ {\partial}w^{(0)}},...,\frac{ {\partial}L(w)}{ {\partial}w^{(m)}}] ∇L(w)=[∂w(0)∂L(w),...,∂w(m)∂L(w)]
根据梯度下降算法(针对求最大值做了修改):
(1)取初始值 w 0 ∈ R n w_0\in R^n w0∈Rn,置k=0
(2)计算 L ( w k ) L(w_k) L(wk)
(3)计算梯度 p k = ∇ L ( w k ) p_k = {\nabla}L(w_k) pk=∇L(wk),当 ∣ ∣ p k ∣ ∣ < ϵ ||p_k||<\epsilon ∣∣pk∣∣<ϵ时,停止迭代,令 w ∗ = w k w^*=w_k w∗=wk;否则 ,求 λ k \lambda_k λk ,使 L ( w k + λ k p k ) = max λ ≥ 0 L ( w k + λ p k ) L(w_k+\lambda_kp_k)=\max_{\lambda\ge0}L(w_k+{\lambda}p_k) L(wk+λkpk)=maxλ≥0L(wk+λpk)
(4)置 w ( k + 1 ) = w ( k ) + λ k p k w_{(k+1)}=w_{(k)}+\lambda_k p_k w(k+1)=w(k)+λkpk,计算 L ( w k + 1 ) L(w_{k+1}) L(wk+1)
当 ∥ L ( w ( k + 1 ) ) − L ( w ( k ) ) ∥ < ϵ % <![CDATA[ \|L(w_{(k+1)})-L(w_{(k)})\|<\epsilon %]]> ∥L(w(k+1))−L(w(k))∥<ϵ或 ∥ w ( k + 1 ) − w ( k ) ∥ < ϵ % <![CDATA[ \|w_{(k+1)}-w_{(k)}\|<\epsilon %]]> ∥w(k+1)−w(k)∥<ϵ时,停止迭代,令 w ∗ = w k + 1 w^*=w_{k+1} w∗=wk+1
(5)否则,置 k=k+1,转(3)。
6.3 最大熵模型的DFP算法
上述2.2可知最后需要求得 w ∗ = a r g m a x w ϕ ( w ) w* = argmax_w\phi(w) w∗=argmaxwϕ(w),其中 ϕ ( w ) = m i n P ∈ C L ( P , w ) = m i n P ∈ C [ − H ( P ) + w 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n w i ( E p ( f i ) − E P ~ ( f i ) ) ] = ∑ x , y P ~ ( x ) P ( y ∣ x ) l o g P ( y ∣ x ) + w 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n w i [ ∑ x , y P ~ ( x , y ) f i ( x , y ) − ∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) ] \phi(w) = min{P\in C}L(P,w) \\ = min{P\in C} [-H(P) + w_0(1-\sum_yP(y|x))+\sum_{i=1}^nw_i(E_p(f_i) - E_{\widetilde{P}}(f_i) )] \\ = \sum_{x,y}\widetilde{P}(x)P(y|x)logP(y|x)+w_0(1-\sum_yP(y|x)) \\ +\sum_{i=1}^nw_i[\sum_{x,y}\widetilde{P}(x,y)f_i(x,y)-\sum_{x,y}\widetilde{P}(x)P(y|x)f_i(x,y)] ϕ(w)=minP∈CL(P,w)=minP∈C[−H(P)+w0(1−y∑P(y∣x))+i=1∑nwi(Ep(fi)−EP (fi))]=x,y∑P (x)P(y∣x)logP(y∣x)+w0(1−y∑P(y∣x))+i=1∑nwi[x,y∑P (x,y)fi(x,y)−x,y∑P (x)P(y∣x)fi(x,y)]最后的似然函数为:
L ( w ) = ϕ ( w ) = ∑ x , y P ~ ( x , y ) ∑ i = 1 n w i f i ( x , y ) − ∑ x P ~ ( x ) log Z w ( x ) L(w) = \phi(w)=\sum_{x,y}\widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y)-\sum_x\widetilde{P}(x)\log{Z_w(x)} L(w)=ϕ(w)=∑x,yP (x,y)∑i=1nwifi(x,y)−∑xP (x)logZw(x)
g ( w ) = ( ∂ L ( w ) ∂ w 1 , ∂ L ( w ) ∂ w 2 , ⋯ , ∂ L ( w ) ∂ w n ) T ∂ L ( w ) ∂ w i = ∑ x , y P ~ ( x , y ) f i ( x , y ) − ∑ x , y P ~ ( x ) P w ( y ∣ x ) f i ( x , y ) , i = 1 , 2 , ⋯ , n g(w)=(\frac{ {\partial}L(w)}{ {\partial}w_1},\frac{ {\partial}L(w)}{ {\partial}w_2},\cdots,\frac{ {\partial}L(w)}{ {\partial}w_n})^T\\\frac{ {\partial}L(w)}{ {\partial}w_i}=\sum_{x,y}\widetilde{P}(x,y)f_i(x,y)-\sum_{x,y}\widetilde{P}(x)P_w(y|x)f_i(x,y),\,i=1,2,\cdots,n g(w)=(∂w1∂L(w),∂w2∂L(w),⋯,∂wn∂L(w))T∂wi∂L(w)=∑x,yP (x,y)fi(x,y)−∑x,yP (x)Pw(y∣x)fi(x,y),i=1,2,⋯,n
有关于DFP算法对搜索方向的更新,主要是对上述梯度函数的一个变化,参考习题笔记。