tf.train
目录
一、模块、类和模块
1、模块
2、类
3、函数
二、重要的函数和类
1、tf.train.MomentumOptimizer类
1、__init__
1、apply_gradients()
2、compute_gradients()
3、compute_gradients()
4、get_name()
5、get_slot()
6、get_slot_names()
7、minimize()
8、variables()
2、tf.train.piecewise_constant函数
3、tf.train.Saver类
1、__init__
2、as_saver_def
3、build
4、export_meta_graph
5、from_proto
6、restore()
7、save
8、set_last_checkpoints
9、set_last_checkpoints_with_time
10、to_proto
4、tf.train.Coordinator类
1、使用方法
2、__init__
3、clear_stop
4、join
5、raise_requested_exception
6、register_thread
7、request_stop
8、should_stop
9、stop_on_exception
10、wait_for_stop
5、tf.train.string_input_producer函数
6、tf.train.match_filenames_once函数
7、tf.train.batch函数
8、tf.train.latest_checkpoint函数
9、tf.train.slice_input_producer函数
10、tf.train.queue_runner类
1、tf.train.queue_runner.add_queue_runner函数
2、tf.train.queue_runner.QueueRunner类
3、tf.train.queue_runner.start_queue_runners函数
11、tf.train.load_checkpoint()函数
12、tf.train.Features
13、tf.compat.v1.train.NewCheckpointReader
14、tf.train.SummarySaverHook
1、__init__
2、after_create_session
3、after_run
4、before_run
5、begin
6、end
15、tf.train.Supervisor
1、__init__
2、Loop
3、PrepareSession
4、RequestStop
5、StartQueueRunners
6、StartStandardServices
7、Stop
8、StopOnException
9、SummaryComputed
10、WaitForStop
11、loop
12、managed_session
13、prepare_or_wait_for_session
14、request_stop
15、should_stop
16、start_queue_runners
17、start_standard_services
18、stop
19、stop_on_exception
20、summary_computed
21、wait_for_stop
16、tf.train.Example
17、tf.compat.v1.train.import_meta_graph
18、tf.train.get_checkpoint_state
19、tf.compat.v1.train.start_queue_runners
20、tf.compat.v1.train.string_input_producer
21、tf.train.Example
Class Example
Properties
Methods
22、tf.train.Int64List()
Class Int64List
__init__
Properties
value
Methods
ByteSize
Clear
ClearField
DiscardUnknownFields
FindInitializationErrors
FromString
HasField
IsInitialized
ListFields
MergeFrom
MergeFromString
RegisterExtension
SerializePartialToString
SerializeToString
SetInParent
UnknownFields
WhichOneof
__eq__
23、tf.train.BytesList
Class BytesList
__init__
Properties
value
Methods
ByteSize
Clear
ClearField
DiscardUnknownFields
FindInitializationErrors
FromString
HasField
IsInitialized
ListFields
MergeFrom
MergeFromString
RegisterExtension
SerializePartialToString
SerializeToString
SetInParent
UnknownFields
WhichOneof
__eq__
22、tf.compat.v1.train.shuffle_batch_join
23、tf.train.Feature
一、模块、类和模块
1、模块
experimentalmodulequeue_runnermodule
2、类
class AdadeltaOptimizer: 实现Adadelta算法的优化器。class AdagradDAOptimizer: 稀疏线性模型的Adagrad对偶平均算法。class AdagradOptimizer: 实现Adagrad算法的优化器。class AdamOptimizer: 现Adam算法的优化器。class BytesListclass Checkpoint: 对可跟踪对象进行分组,保存和恢复它们。class CheckpointManager: 删除旧的检查点。class CheckpointSaverHook: 每N步或秒保存一个检查点。class CheckpointSaverListener: 用于在检查点保存之前或之后执行操作的侦听器的接口。class ChiefSessionCreator: 为主管创建tf.compat.v1.Session。class ClusterDefclass ClusterSpec: 将集群表示为一组“任务”,组织为“作业”。class Coordinator: 线程的协调器。class Exampleclass ExponentialMovingAverage: 通过指数衰减保持变量的移动平均。class Featureclass FeatureListclass FeatureListsclass Featuresclass FeedFnHook: 运行feed_fn并相应地设置feed_dict。class FinalOpsHook: 在会话结束时计算张量的钩子。class FloatListclass FtrlOptimizer: 实现FTRL算法的优化器。class GlobalStepWaiterHook: 延迟执行,直到全局步骤到达wait_until_step。class GradientDescentOptimizer: 实现梯度下降算法的优化器。class Int64Listclass JobDefclass LoggingTensorHook: 每N个局部步骤、每N秒或在末尾打印给定的张量。class LooperThread: 重复运行代码的线程,可选在定时器上运行。class MomentumOptimizer: 实现动量算法的优化器。class MonitoredSession: 类会话对象,用于处理初始化、恢复和挂钩。class NanLossDuringTrainingErrorclass NanTensorHook: 监控损耗张量,如果损耗为NaN,则停止训练。class Optimizer: 优化器的基类。class ProfilerHook: 每N步或每秒捕获CPU/GPU分析信息。class ProximalAdagradOptimizer: 实现近似Adagrad算法的优化器。class ProximalGradientDescentOptimizer: 实现近似梯度下降算法的优化器。class QueueRunner: 保存队列的入队列操作列表,每个操作在线程中运行。class RMSPropOptimizer: 实现RMSProp算法的优化器。class Saver: 保存和恢复变量。class SaverDefclass Scaffold: 结构,用于创建或收集训练模型通常需要的部件。class SecondOrStepTimer: 每N秒或每N步最多触发一次的计时器。class SequenceExampleclass Server: 一种进程内TensorFlow服务器,用于分布式培训。class ServerDefclass SessionCreator: tf.Session的制造厂。class SessionManager: 从检查点恢复并创建会话的训练助手。class SessionRunArgs: 表示要添加到Session.run()调用中的参数。class SessionRunContext: 提供有关正在执行的session.run()调用的信息。class SessionRunHook: 钩子来扩展对monitoredssession .run()的调用。class SessionRunValues: 包含Session.run()的结果。class SingularMonitoredSession: 类会话对象,用于处理初始化、恢复和挂钩。class StepCounterHook: 每秒钟计算步数的钩子。class StopAtStepHook: 请求在指定步骤停止的钩子。class SummarySaverHook: 保存每N个步骤的摘要。class Supervisor: 检查模型和计算摘要的培训助手。class SyncReplicasOptimizer: 类来同步、聚合渐变并将其传递给优化器。class VocabInfo: 热身词汇信息。class WorkerSessionCreator: 为工作程序创建tf.compat.v1.Session。
3、函数
MonitoredTrainingSession(...): 训练时创建一个MonitoredSession。NewCheckpointReader(...)add_queue_runner(...): 将队列运行器添加到图中的集合中(弃用)。assert_global_step(...): 断言global_step_张量是标量int变量或张量。basic_train_loop(...): 训练模型的基本循环。batch(...): 在张量中创建多个张量(弃用)。batch_join(...): 运行张量列表来填充队列,以创建批量示例(弃用)。checkpoint_exists(...): 检查是否存在具有指定前缀的V1或V2检查点(弃用)。checkpoints_iterator(...): 当新的检查点文件出现时,不断地生成它们。cosine_decay(...): 对学习率应用余弦衰减。cosine_decay_restarts(...): 应用余弦衰减与重新启动的学习率。create_global_step(...): 在图中创建全局阶跃张量。do_quantize_training_on_graphdef(...): tf.contrib.quantize正在开发一种通用的量化方案(弃用)。exponential_decay(...): 将指数衰减应用于学习速率。export_meta_graph(...): 返回MetaGraphDef原型。generate_checkpoint_state_proto(...): 生成检查点状态原型。get_checkpoint_mtimes(...): 返回检查点的mtimes(修改时间戳)(弃用)。get_checkpoint_state(...): 从“检查点”文件返回检查点状态原型。get_global_step(...): 得到全局阶跃张量。get_or_create_global_step(...): 返回并创建(必要时)全局阶跃张量。global_step(...): 小助手获取全局步骤。import_meta_graph(...): 重新创建保存在MetaGraphDef原型中的图。init_from_checkpoint(...): 替换变量初始化器,因此它们从检查点文件加载。input_producer(...): 将input_张量的行输出到输入管道的队列(弃用)。inverse_time_decay(...): 对初始学习速率应用逆时间衰减。latest_checkpoint(...): 找到最新保存的检查点文件的文件名。limit_epochs(...): 返回张量num_epochs times,然后引发一个OutOfRange错误(弃用)。linear_cosine_decay(...): 对学习率应用线性余弦衰减。list_variables(...): 返回检查点中所有变量的列表。load_checkpoint(...): 返回ckpt_dir_or_file中找到的检查点的检查点阅读器。load_variable(...): 返回检查点中给定变量的张量值。match_filenames_once(...): 保存匹配模式的文件列表,因此只计算一次。maybe_batch(...): 根据keep_input有条件地创建一批张量(弃用)。maybe_batch_join(...): 运行张量列表,有条件地填充队列以创建批(弃用)。maybe_shuffle_batch(...): 通过随机打乱条件排队的张量创建批(弃用)。maybe_shuffle_batch_join(...): 通过随机打乱条件排队的张量来创建批(弃用)。natural_exp_decay(...): 对初始学习率应用自然指数衰减。noisy_linear_cosine_decay(...): 应用噪声线性余弦衰减的学习率。piecewise_constant(...): 分段常数来自边界和区间值。piecewise_constant_decay(...): 分段常数来自边界和区间值。polynomial_decay(...): 对学习速率应用多项式衰减。range_input_producer(...): 在队列中生成从0到limit-1的整数(弃用)。remove_checkpoint(...): 删除检查点前缀提供的检查点(弃用)。replica_device_setter(...): 返回一个设备函数,用于在为副本构建图表时使用。sdca_fprint(...): 计算输入字符串的指纹。sdca_optimizer(...): 随机双坐标提升(SDCA)优化器的分布式版本。sdca_shrink_l1(...): 对参数采用L1正则化收缩步长。shuffle_batch(...): 通过随机打乱张量创建批(弃用)。shuffle_batch_join(...): 通过随机打乱张量创建批(弃用)。slice_input_producer(...): 在tensor_list中生成每个张量的切片(弃用)。start_queue_runners(...): 启动图中收集的所有队列运行器(弃用)。string_input_producer(...): 输入管道的队列的输出字符串(例如文件名)(弃用)。summary_iterator(...): 用于从事件文件中读取事件协议缓冲区的迭代器。update_checkpoint_state(...): 更新“检查点”文件的内容(弃用)。warm_start(...): 使用给定的设置预热模型。write_graph(...): 将图形原型写入文件。
二、重要的函数和类
1、tf.train.MomentumOptimizer类
实现了 MomentumOptimizer 算法的优化器,如果梯度长时间保持一个方向,则增大参数更新幅度,反之,如果频繁发生符号翻转,则说明这是要减小参数更新幅度。可以把这一过程理解成从山顶放下一个球,会滑的越来越快。实现momentum算法的优化器。计算表达式如下(如果use_nesterov = False):
accumulation = momentum * accumulation + gradient
variable -= learning_rate * accumulation注意,在这个算法的密集版本中,不管梯度值是多少,都会更新和应用累加,而在稀疏版本中(当梯度是索引切片时,通常是因为tf)。只有在前向传递中使用变量的部分时,才更新变量片和相应的累积项。
1、__init__
__init__(
learning_rate,
momentum,
use_locking=False,
name='Momentum',
use_nesterov=False
)构造一个新的momentum optimizer。
参数:
learning_rate: 张量或浮点值。学习速率。momentum: 张量或浮点值。- use_lock:如果真要使用锁进行更新操作。
- name:可选的名称前缀,用于应用渐变时创建的操作。默认为“动力”。
如果是真的,使用Nesterov动量。参见Sutskever et al., 2013。这个实现总是根据传递给优化器的变量的值计算梯度。使用Nesterov动量使变量跟踪本文中称为theta_t + *v_t的值。这个实现是对原公式的近似,适用于高动量值。它将计算NAG中的“调整梯度”,假设新的梯度将由当前的平均梯度加上动量和平均梯度变化的乘积来估计。
Eager Compatibility:
当启用了紧急执行时,learning_rate和momentum都可以是一个可调用的函数,不接受任何参数,并返回要使用的实际值。这对于跨不同的优化器函数调用更改这些值非常有用。
1、apply_gradients()
apply_gradients(
grads_and_vars,
global_step=None,
name=None
)对变量应用梯度,这是minimize()的第二部分,它返回一个应用渐变的Operation。
参数:
- grads_and_vars: compute_gradients()返回的(渐变、变量)的列表。
- global_step: 可选变量,在变量更新后递增1。
- name: 返回操作的可选名称。默认为传递给优化器构造函数的名称。
返回:
- 应用指定梯度的操作。如果global_step不是None,该操作也会递增global_step。
可能产生的异常:
TypeError: Ifgrads_and_varsis malformed.ValueError: If none of the variables have gradients.RuntimeError: If you should use_distributed_apply()instead.
2、compute_gradients()
apply_gradients(
grads_and_vars,
global_step=None,
name=None
)对变量应用梯度,这是最小化()的第二部分,它返回一个应用渐变的操作。
参数:
- grads_and_vars: compute_gradients()返回的(渐变、变量)对列表。
- global_step:可选变量,在变量更新后递增1。
- name:返回操作的可选名称。默认为传递给优化器构造函数的名称。
返回值:
- 应用指定梯度的操作,如果global_step不是None,该操作也会递增global_step。
可能产生的异常:
TypeError: Ifgrads_and_varsis malformed.ValueError: If none of the variables have gradients.RuntimeError: If you should use_distributed_apply()instead.
3、compute_gradients()
compute_gradients(
loss,
var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
grad_loss=None
)为var_list中的变量计算损失梯度。这是最小化()的第一部分。它返回一个(梯度,变量)对列表,其中“梯度”是“变量”的梯度。注意,“梯度”可以是一个张量,一个索引切片,或者没有,如果给定变量没有梯度。
参数:
loss: 一个包含要最小化的值的张量,或者一个不带参数的可调用张量,返回要最小化的值。当启用紧急执行时,它必须是可调用的。- var_list: tf的可选列表或元组。要更新的变量,以最小化损失。默认值为key GraphKeys.TRAINABLE_VARIABLES下的图表中收集的变量列表。
- gate_gradients: 如何对梯度计算进行gate。可以是GATE_NONE、GATE_OP或GATE_GRAPH。
- aggregation_method: 指定用于合并渐变项的方法。有效值在类AggregationMethod中定义。
返回:
- (梯度,变量)对的列表。变量总是存在的,但梯度可以是零。
异常:
TypeError: Ifvar_listcontains anything else thanVariableobjects.ValueError: If some arguments are invalid.RuntimeError: If called with eager execution enabled andlossis not callable.
Eager Compatibility:
当启用了即时执行时,会忽略gate_gradients、aggregation_method和colocate_gradients_with_ops。
4、get_name()
get_name()
5、get_slot()
get_slot(
var,
name
)一些优化器子类使用额外的变量。例如动量和Adagrad使用变量来累积更新。例如动量和Adagrad使用变量来累积更新。如果出于某种原因需要这些变量对象,这个方法提供了对它们的访问。使用get_slot_names()获取优化器创建的slot列表。
参数:
- var: 传递给minimum()或apply_gradients()的变量。
name: 一个字符串。
返回值:
- 如果创建了slot的变量,则没有其他变量。
6、get_slot_names()
get_slot_names()
返回优化器创建的槽的名称列表。
返回值:
- 字符串列表。
7、minimize()
minimize(
loss,
global_step=None,
var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
name=None,
grad_loss=None
)通过更新var_list,添加操作以最小化损失。此方法简单地组合调用compute_gradients()和apply_gradients()。如果想在应用渐变之前处理渐变,可以显式地调用compute_gradients()和apply_gradients(),而不是使用这个函数。
参数:
- loss: 包含要最小化的值的张量。
- global_step: 可选变量,在变量更新后递增1。
- var_list: 可选的变量对象列表或元组,用于更新以最小化损失。默认值为key GraphKeys.TRAINABLE_VARIABLES下的图表中收集的变量列表。
- gate_gradients: 如何对梯度计算进行gate。可以是GATE_NONE、GATE_OP或GATE_GRAPH。
- aggregation_method: 指定用于合并渐变项的方法。有效值在类AggregationMethod中定义。
- colocate_gradients_with_ops: 如果为真,请尝试使用相应的op来合并渐变。
- name: 返回操作的可选名称。
- grad_loss: 可选的。一个包含梯度的张量,用来计算损耗。
返回值:
- 更新var_list中的变量的操作。如果global_step不是None,该操作也会递增global_step。
可能产生的异常:
ValueError: If some of the variables are notVariableobjects.
Eager Compatibility
当启用紧急执行时,loss应该是一个Python函数,它不接受任何参数,并计算要最小化的值。最小化(和梯度计算)是针对var_list的元素完成的,如果不是没有,则针对在执行loss函数期间创建的任何可训练变量。启用紧急执行时,gate_gradients、aggregation_method、colocate_gradients_with_ops和grad_loss将被忽略。
8、variables()
variables()编码优化器当前状态的变量列表。包括由优化器在当前默认图中创建的插槽变量和其他全局变量。
返回值:
- 变量列表。
2、tf.train.piecewise_constant函数
我们看一些论文中,常常能看到论文的的训练策略可能提到学习率是随着迭代次数变化的。在tensorflow中,在训练过程中更改学习率主要有两种方式,第一个是学习率指数衰减,第二个就是迭代次数在某一范围指定一个学习率。tf.train.piecewise_constant()就是为第二种学习率变化方式而设计的。
tf.train.piecewise_constant(
x,
boundaries,
values,
name=None
)
分段常数来自边界和区间值。示例:对前100001步使用1.0的学习率,对后10000步使用0.5的学习率,对任何其他步骤使用0.1的学习率。
global_step = tf.Variable(0, trainable=False)
boundaries = [100000, 110000]
values = [1.0, 0.5, 0.1]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)
# Later, whenever we perform an optimization step, we increment global_step.
参数:
- x: 一个0-D标量张量。必须是下列类型之一:float32、float64、uint8、int8、int16、int32、int64。
boundaries: 张量、int或浮点数的列表,其条目严格递增,且所有元素具有与x相同的类型。values: 张量、浮点数或整数的列表,指定边界定义的区间的值。它应该比边界多一个元素,并且所有元素应该具有相同的类型。name: 一个字符串。操作的可选名称。默认为“PiecewiseConstant”。
返回值:
一个0维的张量。
当x <= boundries[0],值为values[0];
当x > boundries[0] && x<= boundries[1],值为values[1];
......
当x > boundries[-1],值为values[-1]
异常:
ValueError: if types ofxandboundariesdo not match, or types of allvaluesdo not match or the number of elements in the lists does not match.
3、tf.train.Saver类
Saver类添加ops来在检查点之间保存和恢复变量,它还提供了运行这些操作的方便方法。检查点是私有格式的二进制文件,它将变量名映射到张量值。检查检查点内容的最佳方法是使用保护程序加载它。保护程序可以自动编号检查点文件名与提供的计数器。这允许你在训练模型时在不同的步骤中保持多个检查点。例如,你可以使用训练步骤编号为检查点文件名编号。为了避免磁盘被填满,保护程序自动管理检查点文件。例如,他们只能保存N个最近的文件,或者每N个小时的训练只能保存一个检查点。通过将一个值传递给可选的global_step参数以保存(),可以对检查点文件名进行编号:
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000) ==> filename: 'my-model-1000'此外,Saver()构造函数的可选参数允许你控制磁盘上检查点文件的扩散:
- max_to_keep指示要保存的最近检查点文件的最大数量。随着新文件的创建,旧文件将被删除。如果没有或0,则不会从文件系统中删除检查点,而只保留检查点文件中的最后一个检查点。默认值为5(即保存最近的5个检查点文件)。
- keep_checkpoint_every_n_hours:除了保存最近的max_to_keep检查点文件之外,你可能还想为每N小时的训练保留一个检查点文件。如果你希望稍后分析一个模型在长时间的训练过程中是如何进行的,那么这将非常有用。例如,传递keep_checkpoint_every_n_hours=2可以确保每2小时的训练中保留一个检查点文件。默认值10,000小时实际上禁用了该特性。
注意,您仍然必须调用save()方法来保存模型。将这些参数传递给构造函数不会自动为您保存变量。一个定期储蓄的训练项目是这样的:
...
# Create a saver.
saver = tf.compat.v1.train.Saver(...variables...)
# Launch the graph and train, saving the model every 1,000 steps.
sess = tf.compat.v1.Session()
for step in xrange(1000000):
sess.run(..training_op..)
if step % 1000 == 0:
# Append the step number to the checkpoint name:
saver.save(sess, 'my-model', global_step=step)
除了检查点文件之外,保存程序还在磁盘上保存一个协议缓冲区,其中包含最近检查点的列表。这用于管理编号的检查点文件和latest_checkpoint(),从而很容易发现最近检查点的路径。协议缓冲区存储在检查点文件旁边一个名为“检查点”的文件中。如果创建多个保存程序,可以在save()调用中为协议缓冲区文件指定不同的文件名。
1、__init__
__init__(
var_list=None,
reshape=False,
sharded=False,
max_to_keep=5,
keep_checkpoint_every_n_hours=10000.0,
name=None,
restore_sequentially=False,
saver_def=None,
builder=None,
defer_build=False,
allow_empty=False,
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)
创建一个储蓄者。构造函数添加ops来保存和恢复变量。var_list指定将保存和恢复的变量。它可以作为dict或列表传递:
- 变量名的dict:键是用于保存或恢复检查点文件中的变量的名称。
- 变量列表:将在检查点文件中键入变量的op名称。
例:
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# Pass the variables as a dict:
saver = tf.compat.v1.train.Saver({'v1': v1, 'v2': v2})
# Or pass them as a list.
saver = tf.compat.v1.train.Saver([v1, v2])
# Passing a list is equivalent to passing a dict with the variable op names
# as keys:
saver = tf.compat.v1.train.Saver({v.op.name: v for v in [v1, v2]})
可选的整形参数(如果为真)允许从保存文件中还原变量,其中变量具有不同的形状,但是相同数量的元素和类型。如果您已经重新构造了一个变量,并且希望从旧的检查点重新加载它,那么这是非常有用的。可选的分片参数(如果为真)指示保护程序对每个设备进行分片检查点。
参数:
- var_list:变量/SaveableObject的列表,或者将名称映射到SaveableObject的字典。如果没有,则默认为所有可保存对象的列表。
reshape:如果为真,则允许从变量具有不同形状的检查点恢复参数。sharded:如果是真的,切分检查点,每个设备一个。- max_to_keep:最近要保留的检查点的最大数量。默认为5。
- keep_checkpoint t_every_n_hours:保持检查点的频率。默认为10,000小时。
name:字符串。在添加操作时用作前缀的可选名称。- restore_sequsequence:一个Bool,如果为真,则会导致在每个设备中按顺序恢复不同的变量。这可以在恢复非常大的模型时降低内存使用量。
- saver_def:可选的SaverDef原型,用于代替运行构建器。这仅适用于希望为先前构建的具有保护程序的图重新创建保护程序对象的特殊代码。saver_def原型应该是为该图创建的保护程序的as_saver_def()调用返回的对象。
- builder:如果没有提供saver_def,则使用可选的SaverBuilder。默认为BulkSaverBuilder ()。
- defer_build:如果为真,则延迟向build()调用添加save和restore操作。在这种情况下,应该在完成图形或使用保护程序之前调用build()。
- allow_empty:如果为False(默认值),则在图中没有变量时引发错误。否则,无论如何都要构造这个保护程序,使它成为一个no-op。
- write_version:控制保存检查点时使用的格式。它还影响某些文件路径匹配逻辑。推荐使用V2格式:就所需内存和恢复期间发生的延迟而言,它比V1优化得多。不管这个标志是什么,保护程序都能够从V2和V1检查点恢复。
- pad_step_number:如果为真,则将检查点文件路径中的全局步骤数填充为某个固定宽度(默认为8)。默认情况下,这是关闭的。
- save_relative_paths:如果为真,将写入检查点状态文件的相对路径。如果用户想复制检查点目录并从复制的目录重新加载,则需要这样做。
filename:如果在图形构建时已知,则用于变量加载/保存的文件名。
可能产生的异常:
TypeError: Ifvar_listis invalid.ValueError: If any of the keys or values invar_listare not unique.RuntimeError: If eager execution is enabled andvar_listdoes not specify a list of varialbes to save.
2、as_saver_def
as_saver_def()
生成此保护程序的SaverDef表示。
返回值:
-
SaverDef原型。
3、build
build()
4、export_meta_graph
export_meta_graph(
filename=None,
collection_list=None,
as_text=False,
export_scope=None,
clear_devices=False,
clear_extraneous_savers=False,
strip_default_attrs=False,
save_debug_info=False
)
将MetaGraphDef写入save_path/文件名。
参数:
filename:可选的meta_graph文件名,包括路径。- collection_list:要收集的字符串键的列表。
- as_text:如果为真,则将元图作为ASCII原型写入。
- export_scope:可选的字符串。名称要删除的范围。
- clear_devices:在导出期间是否清除操作或张量的设备字段。
- clear_extraneous_savers:从图中删除任何与saverer无关的信息(保存/恢复操作和SaverDefs)。
- strip_default_attrs:布尔。如果为真,则从节点defs中删除默认值属性。有关详细指南,请参见剥离默认值属性。
- save_debug_info:如果为真,将GraphDebugInfo保存到一个单独的文件中,该文件位于文件名相同的目录中,并且在文件扩展名之前添加了_debug。
返回值:
- MetaGraphDef原型。
5、from_proto
@staticmethod
from_proto(
saver_def,
import_scope=None
)
返回从saver_def创建的保护程序对象。
参数:
- saver_def:一个SaverDef协议缓冲区。
- import_scope:可选的字符串。名称要使用的范围。
返回值:
- 一个由saver_def构建的保护程序。
6、restore()
restore(
sess,
save_path
)
恢复以前保存的变量。此方法运行构造函数为恢复变量而添加的ops。它需要启动图表的会话。要还原的变量不必初始化,因为还原本身就是一种初始化变量的方法。save_path参数通常是先前从save()调用或调用latest_checkpoint()返回的值。
参数:
- sess:用于恢复参数的会话。没有处于紧急模式。
- save_path:先前保存参数的路径。
可能产生的异常:
ValueError: If save_path is None or not a valid checkpoint.
7、save
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix='meta',
write_meta_graph=True,
write_state=True,
strip_default_attrs=False,
save_debug_info=False
)
保存变量。此方法运行构造函数为保存变量而添加的ops。它需要启动图表的会话。要保存的变量也必须已初始化。该方法返回新创建的检查点文件的路径前缀。这个字符串可以直接传递给restore()调用。
参数:
- sess:用于保存变量的会话。
- save_path:字符串。为检查点创建的文件名的前缀。
- global_step:如果提供了全局步骤号,则将其附加到save_path以创建检查点文件名。可选参数可以是张量、张量名或整数。
- latest_filename:协议缓冲区文件的可选名称,该文件将包含最近的检查点列表。该文件与检查点文件保存在同一个目录中,由保护程序自动管理,以跟踪最近的检查点。默认为“关卡”。
- meta_graph_suffix: MetaGraphDef文件的后缀。默认为“元”。
- write_meta_graph:布尔值,指示是否编写元图文件。
- write_state:布尔值,指示是否编写检查点stateproto。
- strip_default_attrs:布尔。如果为真,则从节点defs中删除默认值属性。有关详细指南,请参见剥离默认值属性。
- save_debug_info:如果为真,则将GraphDebugInfo保存到一个单独的文件中,该文件位于save_path的相同目录中,并且在文件扩展名之前添加了_debug。只有当write_meta_graph为真时才启用。
返回值:
- 字符串:用于检查点文件的路径前缀。如果保护程序是分片的,这个字符串以:-??-nnnnn',其中'nnnnn'是创建的碎片数。如果保护程序是空的,返回None。
可能产生的异常:
TypeError: Ifsessis not aSession.ValueError: Iflatest_filenamecontains path components, or if it collides withsave_path.RuntimeError: If save and restore ops weren't built.
8、set_last_checkpoints
set_last_checkpoints(last_checkpoints)
弃用:set_last_checkpoints_with_time使用。设置旧检查点文件名的列表。
参数:
last_checkpoints:检查点文件名的列表。
可能产生的异常:
AssertionError: If last_checkpoints is not a list.
9、set_last_checkpoints_with_time
set_last_checkpoints_with_time(last_checkpoints_with_time)
设置旧检查点文件名和时间戳的列表。
参数:
- last_checkpoints_with_time:检查点文件名和时间戳的元组列表。
可能产生的异常:
AssertionError: If last_checkpoints_with_time is not a list.
10、to_proto
to_proto(export_scope=None)
将此保护程序转换为SaverDef协议缓冲区。
参数:
- export_scope:可选的字符串。名称要删除的范围。
返回值:
- 在SaverDef protocol缓冲区。
使用例子:
将训练好的模型参数保存起来,以便以后进行验证或测试,这是我们经常要做的事情。tf里面提供模型保存的是tf.train.Saver()模块。
模型保存,先要创建一个Saver对象:如
saver=tf.train.Saver()在创建这个Saver对象的时候,有一个参数我们经常会用到,就是 max_to_keep 参数,这个是用来设置保存模型的个数,默认为5,即 max_to_keep=5,保存最近的5个模型。如果你想每训练一代(epoch)就想保存一次模型,则可以将 max_to_keep设置为None或者0,如:
saver=tf.train.Saver(max_to_keep=0)但是这样做除了多占用硬盘,并没有实际多大的用处,因此不推荐。
当然,如果你只想保存最后一代的模型,则只需要将max_to_keep设置为1即可,即
saver=tf.train.Saver(max_to_keep=1)创建完saver对象后,就可以保存训练好的模型了,如:
saver.save(sess,'ckpt/mnist.ckpt',global_step=step)4、tf.train.Coordinator类
1、使用方法
线程的协调器。该类实现一个简单的机制来协调一组线程的终止。
使用:
# Create a coordinator.
coord = Coordinator()
# Start a number of threads, passing the coordinator to each of them.
...start thread 1...(coord, ...)
...start thread N...(coord, ...)
# Wait for all the threads to terminate.
coord.join(threads)任何线程都可以调用coord.request_stop()来请求所有线程停止。为了配合请求,每个线程必须定期检查coord .should_stop()。一旦调用了coord.request_stop(), coord.should_stop()将返回True。 一个典型的线程运行协调器会做如下事情:
while not coord.should_stop():
...do some work...异常处理:
线程可以将异常作为request_stop()调用的一部分报告给协调器。异常将从coord.join()调用中重新引发。线程代码如下:
try:
while not coord.should_stop():
...do some work...
except Exception as e:
coord.request_stop(e)主代码:
try:
...
coord = Coordinator()
# Start a number of threads, passing the coordinator to each of them.
...start thread 1...(coord, ...)
...start thread N...(coord, ...)
# Wait for all the threads to terminate.
coord.join(threads)
except Exception as e:
...exception that was passed to coord.request_stop()为了简化线程实现,协调器提供了一个上下文处理程序stop_on_exception(),如果引发异常,该上下文处理程序将自动请求停止。使用上下文处理程序,上面的线程代码可以写成:
with coord.stop_on_exception():
while not coord.should_stop():
...do some work...停止的宽限期:
当一个线程调用了coord.request_stop()后,其他线程有一个固定的停止时间,这被称为“停止宽限期”,默认为2分钟。如果任何线程在宽限期过期后仍然存活,则join()将引发一个RuntimeError报告落后者。
try:
...
coord = Coordinator()
# Start a number of threads, passing the coordinator to each of them.
...start thread 1...(coord, ...)
...start thread N...(coord, ...)
# Wait for all the threads to terminate, give them 10s grace period
coord.join(threads, stop_grace_period_secs=10)
except RuntimeError:
...one of the threads took more than 10s to stop after request_stop()
...was called.
except Exception:
...exception that was passed to coord.request_stop()2、__init__
__init__(clean_stop_exception_types=None)创建一个新的协调器。
参数:
- clean_stop_exception_types,异常类型的可选元组,它应该导致协调器的完全停止。如果将其中一种类型的异常报告给request_stop(ex),协调器的行为将与调用request_stop(None)一样。默认值为(tf.errors.OutOfRangeError,),输入队列使用它来表示输入的结束。当从Python迭代器提供训练数据时,通常将StopIteration添加到这个列表中。
3、clear_stop
clear_stop()清除停止标志。调用此函数后,对should_stop()的调用将返回False。
4、join
join(
threads=None,
stop_grace_period_secs=120,
ignore_live_threads=False
)等待线程终止。
此调用阻塞,直到一组线程终止。线程集是threads参数中传递的线程与通过调用coordinator .register_thread()向协调器注册的线程列表的联合。线程停止后,如果将exc_info传递给request_stop,则会重新引发该异常。
宽限期处理:当调用request_stop()时,将给线程“stop_grace__secs”秒来终止。如果其中任何一个在该期间结束后仍然存活,则会引发RuntimeError。注意,如果将exc_info传递给request_stop(),那么它将被引发,而不是RuntimeError。
参数:
threads: 线程列表。除了已注册的线程外,还要连接已启动的线程。- stop_grace__secs: 调用request_stop()后给线程停止的秒数。
- ignore_live_threads: 如果为False,则在stop_grace__secs之后,如果任何线程仍然存活,则引发错误。
可能发生的异常:
RuntimeError: If any thread is still alive afterrequest_stop()is called and the grace period expires.
5、raise_requested_exception
raise_requested_exception()如果将异常传递给request_stop,则会引发异常。
6、register_thread
register_thread(thread)注册要加入的线程。
参数:
- thread: 要加入的Python线程。
7、request_stop
request_stop(ex=None)请求线程停止。调用此函数后,对should_stop()的调用将返回True。
注意:如果传入异常,in必须在处理异常的上下文中(例如try:…expect expection as ex:......,例如:)和不是一个新创建的。
参数:
- ex: 可选异常,或由sys.exc_info()返回的Python exc_info元组。如果这是对request_stop()的第一个调用,则记录相应的异常并从join()重新引发异常。
8、should_stop
should_stop()检查是否要求停止。
返回:
- 如果请求停止,返回为真。
9、stop_on_exception
stop_on_exception(
*args,
**kwds
)上下文管理器,用于在引发异常时请求停止。使用协调器的代码必须捕获异常并将其传递给request_stop()方法,以停止协调器管理的其他线程。这个上下文处理程序简化了异常处理。使用方法如下:
with coord.stop_on_exception():
# Any exception raised in the body of the with
# clause is reported to the coordinator before terminating
# the execution of the body.
...body...这完全等价于稍微长一点的代码:
try:
...body...
except:
coord.request_stop(sys.exc_info())产生:
nothing.
10、wait_for_stop
wait_for_stop(timeout=None)等待协调器被告知停止。
参数:
- timeout: 浮动, 休眠最多几秒钟,等待should_stop()变为True。
返回值:
- 如果协调器被告知停止,则为True;如果超时过期,则为False。
5、tf.train.string_input_producer函数
把输入的数据进行按照要求排序成一个队列。最常见的是把一堆文件名整理成一个队列。
tf.train.string_input_producer(
string_tensor,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None,
cancel_op=None
)
输出管道的队列的输出字符串(例如文件名)。
注意:如果num_epochs不是None,这个函数将创建本地计数器epochs。使用local_variables_initializer()初始化本地变量。
参数:
- string_tensor: 一个要生成字符串的一维字符串张量。
- num_epochs: 一个整数(可选),如果指定,string_input_producer在生成OutOfRange错误之前,从string_tensor、num_epochs次生成每个字符串。如果没有指定,string_input_producer可以在string_tensor中无限次循环字符串。
- shuffle: 布尔,如果为真,则在每轮内随机打乱字符串。
- seed: 一个整数(可选),如果shuffle == True,就使用种子。
- capacity: 一个整数。设置队列容量。
- shared_name: (可选)如果设置了,此队列将在多个会话中以给定的名称共享。所有打开到具有此队列的设备的会话都可以通过shared_name访问它。在分布式设置中使用此功能意味着每个名称只能被访问此操作的会话之一看到。
- name: 操作的名称(可选)。
- cancel_op: 取消队列的op(可选)。
返回值:
- 带有输出字符串的队列。队列的QueueRunner被添加到当前图的QUEUE_RUNNER集合中。
可能产生的异常:
ValueError: If the string_tensor is a null Python list. At runtime, will fail with an assertion if string_tensor becomes a null tensor.
例:
tf.train.string_input_producer(
string_tensor,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None,
cancel_op=None
)filenames = [os.path.join(data_dir,'data_batch%d.bin' % i ) for i in xrange(1,6)]
filename_queue = tf.train.string_input_producer(filenames)6、tf.train.match_filenames_once函数
用于获取文件列表。
tf.train.match_filenames_once(
pattern,
name=None
)
保存匹配模式的文件列表,因此只计算一次。返回文件的顺序可能是不确定的。
参数:
- pattern: 文件模式(glob),或文件模式的一维张量。
- name: 操作的名称(可选)。
返回值:
- 初始化为与模式匹配的文件列表的变量。
例:
import tensorflow as tf
files = tf.train.match_filenames_once("./path/data.tfrecord-*")7、tf.train.batch函数
tf.train.batch(
tensors,
batch_size,
num_threads=1,
capacity=32,
enqueue_many=False,
shapes=None,
dynamic_pad=False,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
TensorFlow提供了tf.train.batch和tf.train.shuffle_batch函数来将单个样例组织成batch的输出形式。参数Tensors可以是张量的列表或字典。函数返回的值与Tensors的类型相同。这个函数是使用队列实现的。队列的QueueRunner被添加到当前图的QUEUE_RUNNER集合中。如果enqueue_many为False,则假定张量表示单个示例。一个形状为[x, y, z]的输入张量将作为一个形状为[batch_size, x, y, z]的张量输出。如果enqueue_many为真,则假定张量表示一批实例,其中第一个维度由实例索引,并且张量的所有成员在第一个维度中的大小应该相同。如果一个输入张量是shape [*, x, y, z],那么输出就是shape [batch_size, x, y, z]。capacity参数控制允许预取多长时间来增长队列。
返回的操作是一个dequeue操作,如果输入队列已耗尽,则OutOfRangeError。如果该操作正在提供另一个输入队列,则其队列运行器将捕获此异常,但是,如果在主线程中使用该操作,则由您自己负责捕获此异常。
注意: 如果dynamic_pad为False,则必须确保(i)传递了shapes参数,或者(ii)张量中的所有张量必须具有完全定义的形状。如果这两个条件都不成立,将会引发ValueError。
如果dynamic_pad为真,则只要知道张量的秩就足够了,但是单个维度可能没有形状。在这种情况下,对于每个加入值为None的维度,其长度可以是可变的;在退出队列时,输出张量将填充到当前minibatch中张量的最大形状。对于数字,这个填充值为0。对于字符串,这个填充是空字符串。
如果allow_smaller_final_batch为真,那么当队列关闭且没有足够的元素来填充该批处理时,将返回比batch_size更小的批处理值,否则将丢弃挂起的元素。此外,通过shape属性访问的所有输出张量的静态形状的第一个维度值为None,依赖于固定batch_size的操作将失败。
参数:
- tensors: 要排队的张量列表或字典。
- batch_size: 从队列中提取的新批大小。
- num_threads: 进入张量队列的线程数。如果num_threads >为1,则批处理将是不确定的。
- capacity: 一个整数。队列中元素的最大数量。
- enqueue_many: 张量中的每个张量是否是一个单独的例子。
- shape: (可选)每个示例的形状。默认为张量的推断形状。
- dynamic_pad: 布尔。允许在输入形状中使用可变尺寸。在脱队列时填充给定的维度,以便批处理中的张量具有相同的形状。
- allow_smaller_final_batch: (可选)布尔。如果为真,如果队列中没有足够的项,则允许最后的批处理更小。
- shared_name: (可选)。如果设置了,此队列将在多个会话中以给定的名称共享。
- name: (可选)操作的名称。
返回值:
- 与张量类型相同的张量列表或字典(除非输入是一个由一个元素组成的列表,否则它返回一个张量,而不是一个列表)。
可能引发的异常:
ValueError: If theshapesare not specified, and cannot be inferred from the elements oftensors.
8、tf.train.latest_checkpoint函数
tf.train.latest_checkpoint(
checkpoint_dir,
latest_filename=None
)
找到最新保存的checkpoint文件的文件名。
参数:
- checkpoint_dir: 保存变量的目录。
- latest_filename: 包含最近检查点文件名列表的协议缓冲区文件的可选名称。参见Saver.save()的对应参数。
返回值:
- 指向最新检查点的完整路径,如果没有找到检查点,则为None。
9、tf.train.slice_input_producer函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。tf在内存队列之前,还设立了一个文件名队列,文件名队列存放的是参与训练的文件名,要训练N个epoch,则文件名队列中就含有N个批次的所有文件名,示例图如下:
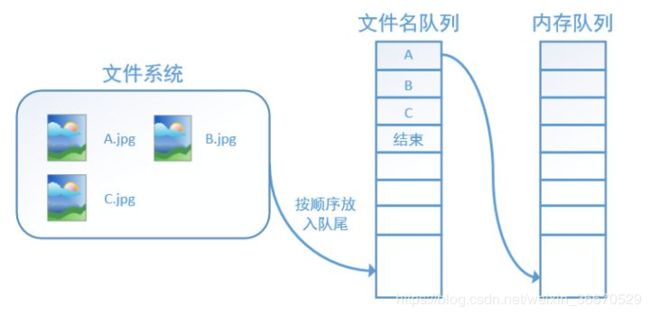
在N个epoch的文件名最后是一个结束标志,当tf读到这个结束标志的时候,会抛出一个 OutofRange 的异常,外部捕获到这个异常之后就可以结束程序了。而创建tf的文件名队列就需要使用到 tf.train.slice_input_producer 函数。 tf.train.slice_input_producer是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
tf.train.slice_input_producer(
tensor_list,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None
)
在tensor_list中生成每个张量的切片。使用队列实现——队列的QueueRunner被添加到当前图的QUEUE_RUNNER集合中。
参数:
- tensor_list: 张量对象列表。tensor_list中的每个张量在第一维中必须具有相同的大小。有多少个图像就有多少个对应的标签;
- num_epochs: 一个整数(可选)。如果指定,slice_input_producer将在生成OutOfRange错误之前生成每个片num_epochs次。如果没有指定,slice_input_producer可以无限次循环遍历片;
- suffle: bool类型,设置是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本;
- seed: 一个整数(可选)。如果shuffle == True才使用;
- capacity: 一个整数。设置队列容量;
- shared_name: (可选)。可选参数,设置生成的tensor序列在不同的Session中的共享名称;
- name: 操作的名称(可选);
返回值:
- 张量列表,每个张量对应一个tensor_list元素。如果张量在tensor_list中有形状[N, a, b, ..],则对应的输出张量的形状为[a, b,…,z]。
可能产生的异常:
ValueError: ifslice_input_producerproduces nothing fromtensor_list.
tf.train.slice_input_producer定义了样本放入文件名队列的方式,包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
例:
import tensorflow as tf
images = ['img1', 'img2', 'img3', 'img4', 'img5']
labels= [1,2,3,4,5]
epoch_num=8
f = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(epoch_num):
k = sess.run(f)
print '************************'
print (i,k)
coord.request_stop()
coord.join(threads)
Output:
--------------------------------------------------------------------------
tf.train.slice_input_producer函数中shuffle=False,不对tensor列表乱序,输出:
************************
(0, ['img1', 1])
************************
(1, ['img2', 2])
************************
(2, ['img3', 3])
************************
(3, ['img4', 4])
************************
(4, ['img5', 5])
************************
(5, ['img1', 1])
************************
(6, ['img2', 2])
************************
(7, ['img3', 3])
如果设置shuffle=True,输出乱序:
************************
(0, ['img5', 5])
************************
(1, ['img4', 4])
************************
(2, ['img1', 1])
************************
(3, ['img3', 3])
************************
(4, ['img2', 2])
************************
(5, ['img3', 3])
************************
(6, ['img2', 2])
************************
(7, ['img1', 1])
------------------------------------------------------------------------10、tf.train.queue_runner类
1、tf.train.queue_runner.add_queue_runner函数
将队列运行器添加到图中的集合中。(弃用)
tf.train.queue_runner.add_queue_runner(
qr,
collection=tf.GraphKeys.QUEUE_RUNNERS
)
在构建使用多个队列的复杂模型时,通常很难收集需要运行的所有队列运行器。此便利函数允许你将队列运行器添加到图中已知的集合中。可以使用同伴方法start_queue_runners()启动所有收集到的队列运行器的线程。
参数:
- qr: QueueRunner。
- 集合:一个GraphKey,指定要将队列运行器添加到其中的图形集合。默认为GraphKeys.QUEUE_RUNNERS。
2、tf.train.queue_runner.QueueRunner类
保存队列的入队列操作列表,每个操作在线程中运行。队列是使用多线程异步计算张量的一种方便的TensorFlow机制。例如,在规范的“输入读取器”设置中,一组线程在队列中生成文件名;第二组线程从文件中读取记录,对其进行处理,并将张量放入第二队列;第三组线程从这些输入记录中取出队列来构造批,并通过训练操作运行它们。当以这种方式运行多个线程时,存在一些微妙的问题:在输入耗尽时按顺序关闭队列、正确捕获和报告异常,等等。
(1)__init__
__init__(
queue=None,
enqueue_ops=None,
close_op=None,
cancel_op=None,
queue_closed_exception_types=None,
queue_runner_def=None,
import_scope=None
)
创建一个QueueRunner。在构造过程中,QueueRunner添加一个op来关闭队列。如果队列操作引发异常,则运行该op。稍后调用create_threads()方法时,QueueRunner将为enqueue_ops中的每个操作创建一个线程。每个线程将与其他线程并行运行它的入队列操作。入队列操作不一定都是相同的操作,但是期望它们都将张量入队列。
参数:
queue:一个队列。- enqueue_ops:以后在线程中运行的排队操作列表。
- close_op: Op关闭队列。保留挂起的排队操作。
- cancel_op: Op关闭队列并取消挂起的入队操作。
- queue_closed_exception_types:异常类型的可选元组,表示队列在enqueue操作期间被触发时已关闭。默认为(tf.errors.OutOfRangeError)。另一种常见的情况包括(tf.errors)。OutOfRangeError, tf.errors.CancelledError),当一些入队列操作可能从其他队列中退出队列时。
- queue_runner_def:可选的QueueRunnerDef协议缓冲区。如果指定,则从其内容重新创建QueueRunner。queue_runner_def和其他参数是互斥的。
- import_scope:可选的字符串。要添加的名称范围。仅在从协议缓冲区初始化时使用。
可能产生的异常:
ValueError: If bothqueue_runner_defandqueueare both specified.ValueError: Ifqueueorenqueue_opsare not provided when not restoring fromqueue_runner_def.RuntimeError: If eager execution is enabled.
(2)create_threads
create_threads(
sess,
coord=None,
daemon=False,
start=False
)
创建线程来运行给定会话的排队操作。此方法需要启动图形的会话。它创建一个线程列表,可以选择启动它们。enqueue_ops中传递的每个op都有一个线程。coord参数是一个可选的协调器,线程将使用它一起终止并报告异常。如果给定一个协调器,此方法将启动一个附加线程,以便在协调器请求停止时关闭队列。如果先前为给定会话创建的线程仍在运行,则不会创建任何新线程。
参数:
sess:一个会话。- coord:可选的协调器对象,用于报告错误和检查停止条件。
daemon:布尔。如果为真,让线程守护进程线程。start:布尔。如果为真,则启动线程。如果为False,调用者必须调用返回线程的start()方法。
返回值:
- 线程的列表。
(3)from_proto
@staticmethod
from_proto(
queue_runner_def,
import_scope=None
)返回一个queue_runner_def创建的QueueRunner对象。
(4)to_proto
to_proto(export_scope=None)
将此QueueRunner转换为QueueRunnerDef协议缓冲区。
参数:
- export_scope:可选的字符串。名称要删除的范围。
返回值:
- QueueRunnerDef协议缓冲区,如果变量不在指定的名称范围内,则为None。
3、tf.train.queue_runner.start_queue_runners函数
启动图中所有队列运行器集合。
tf.train.queue_runner.start_queue_runners(
sess=None,
coord=None,
daemon=True,
start=True,
collection=tf.GraphKeys.QUEUE_RUNNERS
)
警告:不推荐使用此函数。它将在未来的版本中被删除。更新说明:要构造输入管道,请使用tf.data模块。
这是add_queue_runner()的一个伴生方法。它只是为图中收集的所有队列运行器启动线程。它返回所有线程的列表。
参数:
- sess:用于运行队列操作的会话。默认为默认会话。
- coord:用于协调启动线程的可选协调器。
daemon:线程是否应该标记为守护进程,这意味着它们不会阻塞程序退出。- start:设置为False,只创建线程,不启动线程。
- 集合:一个GraphKey,指定要从其中获取队列运行器的图形集合。默认为GraphKeys.QUEUE_RUNNERS。
可能产生的异常:
ValueError: ifsessis None and there isn't any default session.TypeError: ifsessis not atf.compat.v1.Sessionobject.
返回值:
- 线程列表。
可能产生的异常:
RuntimeError: If called with eager execution enabled.ValueError: If called without a defaulttf.compat.v1.Sessionregistered.
例:
TensorFlow的Session对象是支持多线程的,可以在同一个会话(Session)中创建多个线程,并行执行。在Session中的所有线程都必须能被同步终止,异常必须能被正确捕获并报告,会话终止的时候, 队列必须能被正确地关闭。TensorFlow提供了两个类来实现对Session中多线程的管理:tf.Coordinator和 tf.QueueRunner,这两个类往往一起使用。Coordinator类用来管理在Session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该线程捕获到这个异常之后就会终止所有线程。使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程同时将多个tensor(训练数据)推送入文件名称队列中,具体执行函数是 tf.train.start_queue_runners , 只有调用 tf.train.start_queue_runners 之后,才会真正把tensor推入内存序列中,供计算单元调用,否则会由于内存序列为空,数据流图会处于一直等待状态。tf中的数据读取机制如下图:
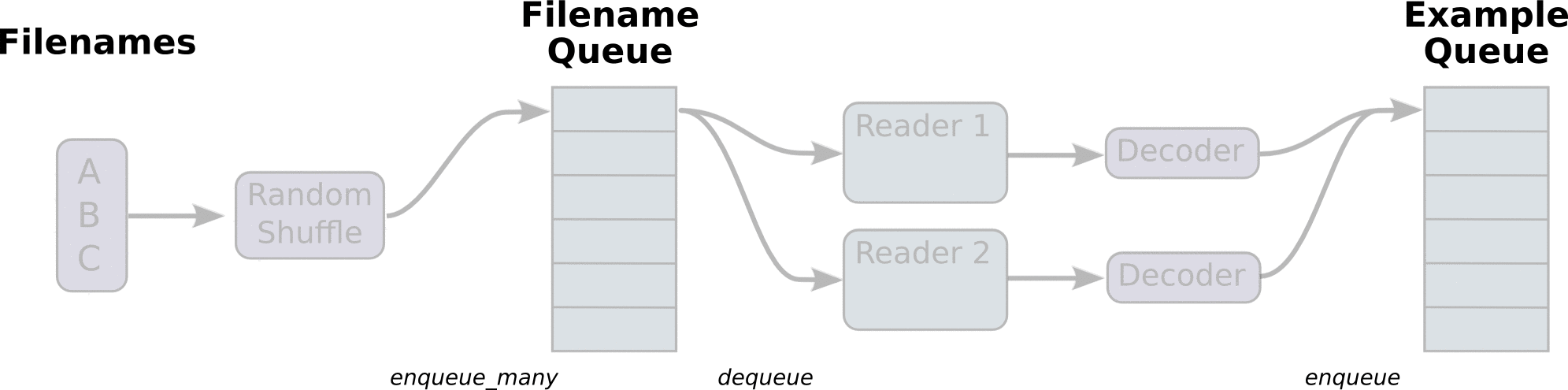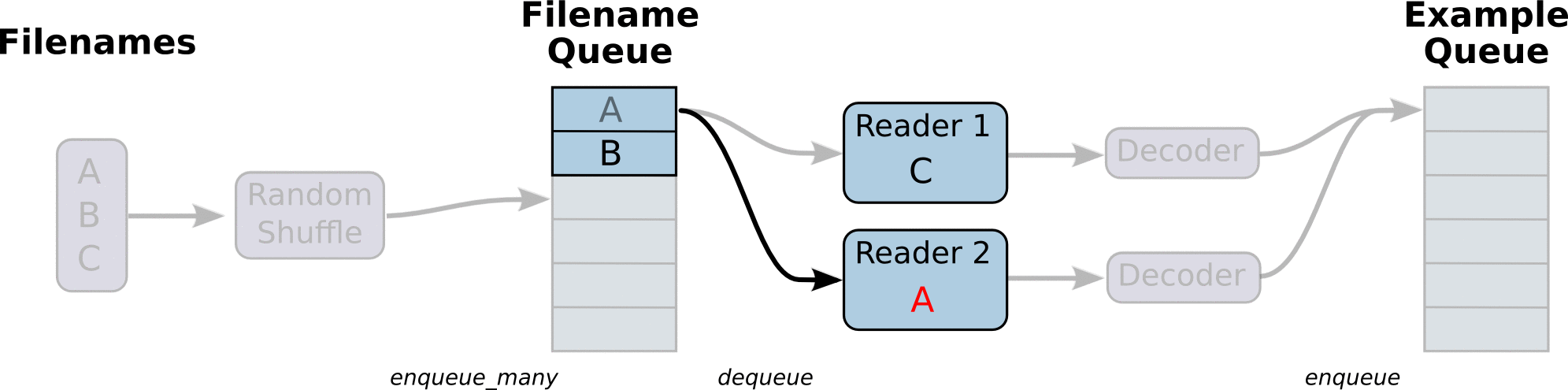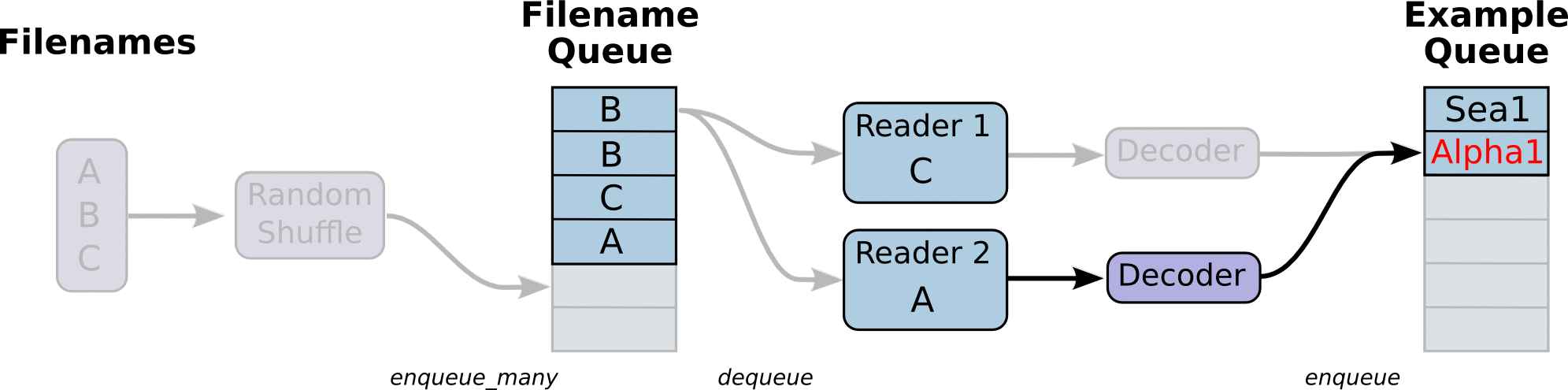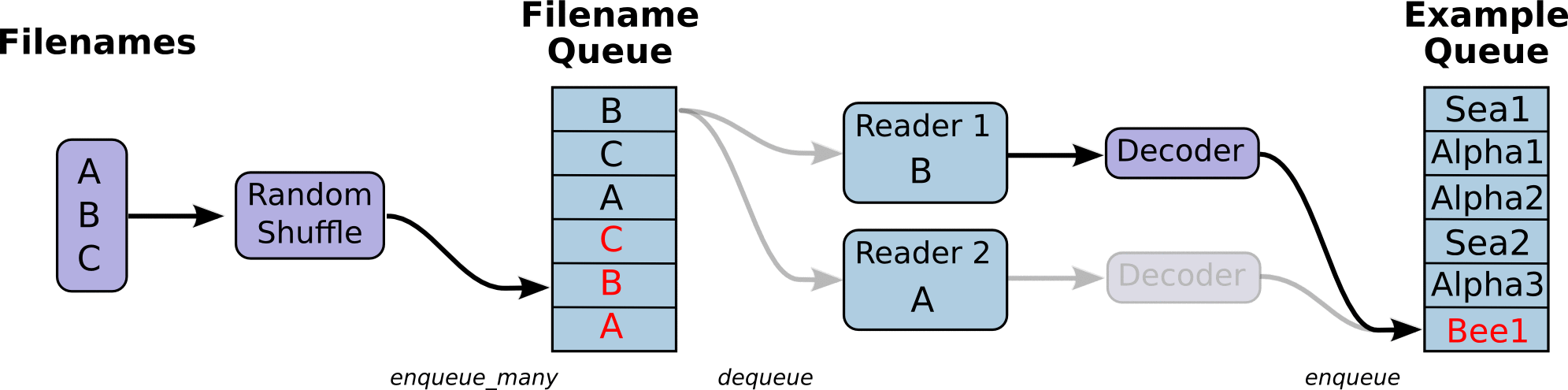
- 调用 tf.train.slice_input_producer,从 本地文件里抽取tensor,准备放入Filename Queue(文件名队列)中;
- 调用 tf.train.batch,从文件名队列中提取tensor,使用单个或多个线程,准备放入文件队列;
- 调用 tf.train.Coordinator() 来创建一个线程协调器,用来管理之后在Session中启动的所有线程;
- 调用tf.train.start_queue_runners, 启动入队线程,由多个或单个线程,按照设定规则,把文件读入Filename Queue中。函数返回线程ID的列表,一般情况下,系统有多少个核,就会启动多少个入队线程(入队具体使用多少个线程在tf.train.batch中定义);
- 文件从 Filename Queue中读入内存队列的操作不用手动执行,由tf自动完成;
- 调用sess.run 来启动数据出列和执行计算;
- 使用 coord.should_stop()来查询是否应该终止所有线程,当文件队列(queue)中的所有文件都已经读取出列的时候,会抛出一个 OutofRangeError 的异常,这时候就应该停止Sesson中的所有线程了;
- 使用coord.request_stop()来发出终止所有线程的命令,使用coord.join(threads)把线程加入主线程,等待threads结束。
以上对列(Queue)和 协调器(Coordinator)操作示例:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
# 样本个数
sample_num = 5
# 设置迭代次数
epoch_num = 2
# 设置一个批次中包含样本个数
batch_size = 3
# 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num / batch_size) + 1
# 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('imagesize{}, labelsize: {}'.format(images.shape, labels.shape))
return images, labels
def get_batch_data(batch_size=batch_size):
images, label = generate_data()
# 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32)
# 从tensor列表中按顺序或随机抽取一个tensor准备放入文件名称队列
input_queue = tf.train.slice_input_producer([images, label], num_epochs=epoch_num, shuffle=False)
# 从文件名称队列中读取文件准备放入文件队列
image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=2, capacity=64,
allow_smaller_final_batch=False)
return image_batch, label_batch
image_batch, label_batch = get_batch_data(batch_size=batch_size)
with tf.Session() as sess:
# 先执行初始化工作
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# 开启一个协调器
coord = tf.train.Coordinator()
# 使用start_queue_runners 启动队列填充
threads = tf.train.start_queue_runners(sess, coord)
try:
while not coord.should_stop():
print(' ** ** ** ** ** **')
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError: # 如果读取到文件队列末尾会抛出此异常
print("done! now lets kill all the threads……")
finally:
# 协调器coord发出所有线程终止信号
coord.request_stop()
print('all threads are asked tostop!')
coord.join(threads) # 把开启的线程加入主线程,等待threads结束
print('all threads are stopped!')
Output:
---------------------------------------------------------------------------------------------------------
imagesize(5, 224, 224, 3), labelsize: (5,)
WARNING:tensorflow:From D:\anaconda\envs\tensorflow\lib\site-packages\tensorflow\python\training\input.py:187: QueueRunner.__init__ (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.
Instructions for updating:
To construct input pipelines, use the `tf.data` module.
WARNING:tensorflow:From D:\anaconda\envs\tensorflow\lib\site-packages\tensorflow\python\training\input.py:187: add_queue_runner (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.
Instructions for updating:
To construct input pipelines, use the `tf.data` module.
2019-08-14 10:46:20.968000: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2019-08-14 10:46:20.971000: I tensorflow/core/common_runtime/process_util.cc:69] Creating new thread pool with default inter op setting: 8. Tune using inter_op_parallelism_threads for best performance.
WARNING:tensorflow:From D:/tensorflow_learning/test.py:48: start_queue_runners (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.
Instructions for updating:
To construct input pipelines, use the `tf.data` module.
** ** ** ** ** **
(3, 224, 224, 3) [0 1 2]
** ** ** ** ** **
(3, 224, 224, 3) [3 4 0]
** ** ** ** ** **
(3, 224, 224, 3) [1 2 3]
** ** ** ** ** **
done! now lets kill all the threads……
all threads are asked tostop!
all threads are stopped!
---------------------------------------------------------------------------------------------------------11、tf.train.load_checkpoint()函数
返回ckpt_dir_or_file中找到的检查点的检查点阅读器。
tf.train.load_checkpoint(ckpt_dir_or_file)
如果ckpt_dir_or_file解析到具有多个检查点的目录,则返回最新检查点的reader。
参数:
- ckpt_dir_or_file:包含检查点文件或检查点文件路径的目录。
返回值:
- CheckpointReader对象。
可能产生的异常:
ValueError: Ifckpt_dir_or_fileresolves to a directory with no checkpoints.
12、tf.train.Features
用于生成协议消息。
__init__
__init__(**kwargs)
Child Classes
class FeatureEntry
Properties
feature
repeated FeatureEntry feature
Methods
ByteSize
ByteSize()
Clear
Clear()
ClearField
ClearField(field_name)
DiscardUnknownFields
DiscardUnknownFields()
FindInitializationErrors
FindInitializationErrors()
查找未初始化的必需字段。
返回值:
- 字符串列表。每个字符串是从顶级消息到未初始化字段的路径,例如。“foo.bar [5] .baz”。
FromString
@staticmethod
FromString(s)
HasField
HasField(field_name)
IsInitialized
IsInitialized(errors=None)
检查是否设置了消息的所有必需字段。
参数:
- 错误:如果提供了一个列表,它将填充所有缺少的必需字段的字段路径。
返回值:
- 如果指定的消息已设置所有必需字段,则为True。
ListFields
ListFields()
MergeFrom
MergeFrom(msg)
MergeFromString
MergeFromString(serialized)
RegisterExtension
@staticmethod
RegisterExtension(extension_handle)
SerializePartialToString
SerializePartialToString(**kwargs)
SerializeToString
SerializeToString(**kwargs)
SetInParent
SetInParent()
将_cached_byte_size_dirty位设置为true,并将其传播给侦听器(如果这是状态更改)。
UnknownFields
UnknownFields()
WhichOneof
WhichOneof(oneof_name)
返回其中一个或None中当前设置字段的名称。
__eq__
__eq__(other)
13、tf.compat.v1.train.NewCheckpointReader
tf.compat.v1.train.NewCheckpointReader(filepattern)
一个标准的模型文件有一下文件, model_dir就是MyModel(没有后缀)
checkpoint
Model.meta
Model.data-00000-of-00001
Model.index
import tensorflow as tf
import pprint # 使用pprint 提高打印的可读性
NewCheck =tf.train.NewCheckpointReader("model")
打印模型中的所有变量
print("debug_string:\n")
pprint.pprint(NewCheck.debug_string().decode("utf-8"))

其中有3个字段, 分别是名字, 数据类型, shape。获取变量中的值。
print("get_tensor:\n")
pprint.pprint(NewCheck.get_tensor("D/conv2d/bias")) 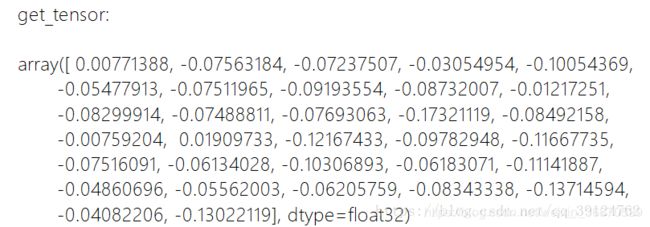
在这里插入图片描述
print("get_variable_to_dtype_map\n")
pprint.pprint(NewCheck.get_variable_to_dtype_map())
print("get_variable_to_shape_map\n")
pprint.pprint(NewCheck.get_variable_to_shape_map())


14、tf.train.SummarySaverHook
保存每N个步骤的摘要。
1、__init__
__init__(
save_steps=None,
save_secs=None,
output_dir=None,
summary_writer=None,
scaffold=None,
summary_op=None
)
初始化一个SummarySaverHook。
参数:
save_steps:int,保存每N个步骤的摘要。应该设置一个save_secs和save_steps。- save_secs: int,每N秒保存一次摘要。
- output_dir: string,保存摘要到的目录。仅在不提供summary_writer时使用。
- summary_writer: SummaryWriter。如果传递了None和output_dir,那么将相应地创建一个。
- scaffold:如果没有提供summary_op,则脚手架获取它。
summary_op:类型为string的张量,包含序列化的摘要协议缓冲区或张量列表。它们很可能是TF摘要方法(如TF .compat.v1.summary.scalar或TF .compat.v1.summary.merge_all)的输出。它可以作为一个张量传递进来;如果超过一个,则必须作为列表传递。
可能产生的异常:
ValueError: Exactly one of scaffold or summary_op should be set.
2、after_create_session
after_create_session(
session,
coord
)
在创建新的TensorFlow会话时调用。调用此函数是为了向钩子发出创建新会话的信号。这与begin调用的情况有两个本质区别:
- 当调用此函数时,图就完成了,ops不再可以添加到图中。
- 此方法还将作为恢复已包装会话的结果调用,而不仅仅是在整个会话开始时调用。
参数:
- session:已创建的TensorFlow会话。
- coord:跟踪所有线程的协调器对象。
3、after_run
after_run(
run_context,
run_values
)
4、before_run
before_run(run_context)
5、begin
begin()
6、end
end(session=None)
15、tf.train.Supervisor
不推荐使用该类。请使用tf.compat.v1.train.MonitoredTrainingSession。管理器是一个围绕协调器、保护程序和SessionManager的小包装器,负责处理TensorFlow培训程序的常见需求。
用于单个程序
with tf.Graph().as_default():
...add operations to the graph...
# Create a Supervisor that will checkpoint the model in '/tmp/mydir'.
sv = Supervisor(logdir='/tmp/mydir')
# Get a TensorFlow session managed by the supervisor.
with sv.managed_session(FLAGS.master) as sess:
# Use the session to train the graph.
while not sv.should_stop():
sess.run()
在with svm.managed_session()块中,图中的所有变量都已初始化。此外,已经启动了一些服务来检查模型并向事件日志添加摘要。如果程序崩溃并重新启动,托管会话将从最近的检查点自动重新初始化变量。任何服务引发的异常都会通知主管。在引发异常之后,should_stop()返回True。在这种情况下,训练循环也应该停止。这就是为什么训练循环必须检查svm .should_stop()。例外情况,表明培训投入已用尽,tf.错误。OutOfRangeError还会导致sv.should_stop()返回True,但不会从with块中重新引发:它们表示正常终止。
Use for multiple replicas
要使用副本进行培训,需要在集群中部署相同的程序。必须将其中一个任务标识为主要任务:处理初始化、检查点、摘要和恢复的任务。其他任务取决于这些事务的负责人。对单个程序代码所要做的惟一更改是指示程序是否作为主程序运行。
# Choose a task as the chief. This could be based on server_def.task_index,
# or job_def.name, or job_def.tasks. It's entirely up to the end user.
# But there can be only one *chief*.
is_chief = (server_def.task_index == 0)
server = tf.distribute.Server(server_def)
with tf.Graph().as_default():
...add operations to the graph...
# Create a Supervisor that uses log directory on a shared file system.
# Indicate if you are the 'chief'
sv = Supervisor(logdir='/shared_directory/...', is_chief=is_chief)
# Get a Session in a TensorFlow server on the cluster.
with sv.managed_session(server.target) as sess:
# Use the session to train the graph.
while not sv.should_stop():
sess.run()
在主任务中,主管的工作方式与上面的第一个示例完全相同。在其他任务中,sv.managed_session()在将会话返回给训练代码之前,等待初始化模型。非主要任务依赖于初始化模型的主要任务。如果其中一个任务崩溃并重新启动,managed_session()检查模型是否初始化。如果是,它只创建一个会话并将其返回到正常运行的培训代码。如果需要初始化模型,则主要任务负责重新初始化模型;其他任务只是等待模型被初始化。注意:这个修改后的程序作为一个单独的程序仍然可以正常工作。单个程序将自己标记为chief。
使用什么主字符串
无论您是在您的机器上运行,还是在集群中运行,您都可以使用以下值作为——master标志:
- 指定“请求不使用RPC的进程内会话”。
- 指定“本地”请求使用基于rpc的“主接口”运行TensorFlow程序的会话。看到tf.train.Server。create_local_server详情。
- 指定“grpc://hostname:port”请求一个会话,该会话使用RPC接口到特定的主机,并且允许进程内的主进程访问远程tensorflow worker。通常,传递服务器是合适的。目标(对于一些tf. distribution。服务器命名的服务器)。
Advanced use
推出额外的服务
managed_session()启动检查点和摘要服务(线程)。如果需要运行更多的服务,可以在managed_session()控制的块中启动它们。示例:启动一个线程来打印损失。我们希望这个线程每60秒运行一次,因此我们使用svg .loop()启动它。
...
sv = Supervisor(logdir='/tmp/mydir')
with sv.managed_session(FLAGS.master) as sess:
sv.loop(60, print_loss, (sess, ))
while not sv.should_stop():
sess.run(my_train_op)
Launching fewer services:
managed_session()启动“摘要”和“检查点”线程,这些线程可以使用传递给构造函数的可选摘要_op和保护程序,也可以使用由监控器自动创建的默认摘要和保护程序。如果希望运行自己的摘要和检查点逻辑,可以通过不向summary_op和保护程序参数传递任何服务来禁用这些服务。示例:在chief中每100步手动创建摘要。
# Create a Supervisor with no automatic summaries.
sv = Supervisor(logdir='/tmp/mydir', is_chief=is_chief, summary_op=None)
# As summary_op was None, managed_session() does not start the
# summary thread.
with sv.managed_session(FLAGS.master) as sess:
for step in xrange(1000000):
if sv.should_stop():
break
if is_chief and step % 100 == 0:
# Create the summary every 100 chief steps.
sv.summary_computed(sess, sess.run(my_summary_op))
else:
# Train normally
sess.run(my_train_op)
Custom model initialization
managed_session()只支持通过运行init_op或从最新检查点恢复来初始化模型。如果您有特殊的初始化需求,请参见如何在创建管理器时指定local_init_op。您还可以直接使用SessionManager创建会话,并检查它是否可以自动初始化。
1、__init__
__init__(
graph=None,
ready_op=USE_DEFAULT,
ready_for_local_init_op=USE_DEFAULT,
is_chief=True,
init_op=USE_DEFAULT,
init_feed_dict=None,
local_init_op=USE_DEFAULT,
logdir=None,
summary_op=USE_DEFAULT,
saver=USE_DEFAULT,
global_step=USE_DEFAULT,
save_summaries_secs=120,
save_model_secs=600,
recovery_wait_secs=30,
stop_grace_secs=120,
checkpoint_basename='model.ckpt',
session_manager=None,
summary_writer=USE_DEFAULT,
init_fn=None,
local_init_run_options=None
)
创建一个监督器。(弃用)
参数:
graph:一个图。模型将使用的图。默认为默认图形。管理器可以在创建会话之前向图形添加操作,但是调用者不应该在将图形传递给管理器之后修改图形。- ready_op:一维弦张量。这个张量由prepare_or_wait_for_session()中的管理人员评估,以检查模型是否可以使用。如果模型返回一个空数组,则认为该模型已经就绪。默认为tf.compat.v1.report_uninitialized_variables()返回的张量。
- ready_for_local_init_op:一维字符串张量。这个张量由prepare_or_wait_for_session()中的管理器计算,以检查模型是否准备好运行local_init_op。如果模型返回一个空数组,则认为该模型已经就绪。默认为没有。如果没有,则在运行local_init_op之前不检查模型是否准备就绪。
- is_chief:如果为真,创建一个主管,负责初始化和恢复模型。如果为False,则创建一个依赖于总监控器进行inits和还原的监控器。
- init_op:操作。当无法恢复模型时,主监控器用于初始化该模型。默认为初始化所有全局变量的操作。如果没有,则不会自动执行初始化,除非传递init_fn的值,如下所示。
- init_feed_dict:映射张量对象以提供值的字典。当计算init_op时,将使用此提要字典。
- local_init_op:操作。所有管理器用于为每个新管理器实例运行应该运行的初始化。默认情况下,这些是表初始化器和局部变量的初始化器。如果没有,则不会自动执行每个管理器实例的进一步初始化。
- logdir:一个字符串。到目录的可选路径,在该目录中对模型进行检查点,并记录可视化程序的事件。供主管人员使用。如果目录不存在,将创建该目录。
- summary_op:返回事件日志摘要的操作。如果指定了logdir,则由主管使用。默认为summary.merge_all()返回的操作。如果没有,则不会自动计算摘要。
- 保护程序:一个保护程序对象。如果指定了logdir,则由主管使用。默认为Saver()返回的已保存值。如果没有,则不会自动保存模型。
- global_step:一个大小为1的整数张量,用于计算步长。来自'global_step'的值用于摘要和检查点文件名。如果存在图形中名为'global_step'的op,则默认为rank 1, size 1,类型为tf.int32或tf.int64。如果没有,则在摘要和检查点文件中不记录全局步骤。如果指定了logdir,则由主管使用。
- save_summaries_secs:事件日志摘要计算之间的秒数。默认为120秒。通过0禁用摘要。
- save_model_secs:创建模型检查点之间的秒数。默认为600秒。通过0禁用检查点。
- recovery_wait_secs:检查模型是否准备好之间的秒数。当主管等待主管初始化或还原模型时使用。默认为30秒。
- stop_grace_secs:宽限期(以秒为单位),用于在调用stop()时停止正在运行的线程。默认为120秒。
- checkpoint_basename:用于保存检查点的basename。
- session_manager: SessionManager,它管理会话创建和恢复。如果没有,将创建一个默认的SessionManager,并为向后兼容性传入一组参数。
- 使用或使用默认值。可以是None,表示不应该编写摘要。
- init_fn:可选的可调用函数,用于初始化模型。在调用可选的init_op之后调用。可调用项必须接受一个参数,即正在初始化的会话。
- local_init_run_options:作为SessionManager local_init_run_options参数传递的runo。
返回值:
- 监督器。
可能产生的异常:
RuntimeError: If called with eager execution enabled.
2、Loop
Loop(
timer_interval_secs,
target,
args=None,
kwargs=None
)
启动一个定期调用函数的LooperThread。如果timer_interval_secs为None,则线程将重复调用target(*args, **kwargs)。否则,它每隔timer_interval_secs秒调用一次。线程在请求停止时终止。启动的线程被添加到管理器管理的线程列表中,因此不需要将其传递给stop()方法。
参数:
- timer_interval_secs:号码。调用目标的时间界限。
target:一个可调用的对象。- args:可选参数,调用时传递给目标。
- kwargs:可选的关键字参数,在调用时传递给目标。
返回值:
- 启动线程。
3、PrepareSession
PrepareSession(
master='',
config=None,
wait_for_checkpoint=False,
max_wait_secs=7200,
start_standard_services=True
)
确保模型已经准备好可以使用。在“master”上创建一个会话,根据需要恢复或初始化模型,或者等待会话就绪。如果将以chief和start_standard_service的身份运行设置为True,还可以调用会话管理器来启动标准服务。
参数:
- master:要使用的TensorFlow master的名称。有关如何解释这一点,请参阅tf.compat.v1.Session构造函数。
config:可选的ConfigProto proto用于配置会话,它按原样传递以创建会话。- wait_for_checkpoint:我们是否应该在创建会话之前等待检查点的可用性。默认值为False。
- max_wait_secs:等待会话可用的最大时间。
- start_standard_services:是否启动标准服务和队列运行器。
返回值:
- 可用于驱动模型的会话对象。
4、RequestStop
ShouldStop()
检查协调器是否被告知停止。
返回值:
- 如果协调器被告知停止,则为True,否则为False。
5、StartQueueRunners
StartQueueRunners(
sess,
queue_runners=None
)
启动队列运行器的线程。注意,当您与管理器创建会话时,graph key queue_runner中收集的队列运行器已经自动启动,因此,除非您启动了非收集的队列运行器,否则不需要显式地调用它。
参数:
sess:一个会话。- queue_runners:一个队列运行器列表。如果没有指定,我们将使用图中键graphkeys . queue_runner下收集的队列运行器列表。
返回值:
- 队列运行器启动的线程列表。
可能产生的异常:
RuntimeError: If called with eager execution enabled.
6、StartStandardServices
StartStandardServices(sess)
启动“sess”的标准服务。这将在后台启动服务。启动的服务取决于构造函数的参数,可能包括:
- 一个总结线程计算总结每个save_summaries_secs。
- 每个save_model_secs保存模型的检查点线程。
- StepCounter线程测量步骤时间。
参数:
sess:一个会话。
返回值:
- 运行标准服务的线程列表。您可以使用主管的协调器将这些线程连接到:svg.co.join ()
可能产生的异常:
RuntimeError: If called with a non-chief Supervisor.ValueError: If notlogdirwas passed to the constructor as the services need a log directory.
7、Stop
Stop(
threads=None,
close_summary_writer=True,
ignore_live_threads=False
)
停止服务和协调器。这不会关闭会话。
参数:
threads:可选的与协调器连接的线程列表。如果没有,则默认为运行标准服务的线程、队列运行器启动的线程和loop()方法启动的线程。若要等待其他线程,请在此参数中传递列表。- close_summary_writer:是否关闭summary_writer。如果摘要编写器是由主管创建的,则默认为True,否则为False。
- ignore_live_threads:如果True忽略通过协调器连接线程时在一段宽限期之后仍然运行的线程,而不是引发RuntimeError。
8、StopOnException
StopOnException()
上下文处理程序,以在引发异常时停止管理程序。
返回值:
- 一个上下文处理程序。
9、SummaryComputed
SummaryComputed(
sess,
summary,
global_step=None
)
指示已计算摘要。
参数:
- sess:会话对象。
summary:摘要原型,或包含序列化摘要原型的字符串。- global_step: Int. global step这个摘要与之关联。如果没有,它将尝试获取当前步骤。
可能产生的异常:
TypeError: if 'summary' is not a Summary proto or a string.RuntimeError: if the Supervisor was created without alogdir.
10、WaitForStop
WaitForStop()
阻塞,等待协调器停止。
11、loop
loop(
timer_interval_secs,
target,
args=None,
kwargs=None
)
启动一个定期调用函数的LooperThread。如果timer_interval_secs为None,则线程将重复调用target(*args, **kwargs)。否则,它每隔timer_interval_secs秒调用一次。线程在请求停止时终止。启动的线程被添加到管理器管理的线程列表中,因此不需要将其传递给stop()方法。
参数:
- timer_interval_secs:号码。调用目标的时间界限。
target:一个可调用的对象。- args:可选参数,调用时传递给目标。
- kwargs:可选的关键字参数,在调用时传递给目标。
返回值:
- 启动线程。
12、managed_session
managed_session(
*args,
**kwds
)
返回托管会话的上下文管理器。此上下文管理器创建并自动恢复会话。它可以选择启动处理检查点和摘要的标准服务。它监视从with块或服务中引发的异常,并根据需要停止管理器。上下文管理器通常使用如下:
def train():
sv = tf.compat.v1.train.Supervisor(...)
with sv.managed_session() as sess:
for step in xrange(..):
if sv.should_stop():
break
sess.run()
...do other things needed at each training step...
当块退出时,从with块或服务线程之一引发异常。这是在停止所有线程并关闭会话之后完成的。例如,当块退出时,会再次引发一个AbortedError异常(在分布式模型中抢占一个worker时抛出)。如果你想在抢占的情况下重试训练循环,你可以这样做:
def main(...):
while True
try:
train()
except tf.errors.Aborted:
pass
作为一种特殊情况,用于控制流的异常(例如报告输入队列已耗尽的OutOfRangeError)不会从with块中再次引发:它们指示训练循环的干净终止,并被视为正常终止。
参数:
- master:要使用的TensorFlow master的名称。有关如何解释这一点,请参阅tf.compat.v1.Session构造函数。
config:可选的ConfigProto proto用于配置会话。按原样传递以创建会话。- start_standard_services:是否启动标准服务,如检查点、摘要和步骤计数器。
- close_summary_writer:是否在关闭会话时关闭摘要编写器。默认值为True。
返回值:
- 上下文管理器,它生成从最新检查点恢复的会话,如果不存在检查点,则从头初始化会话。当with块退出时,会话将关闭。
13、prepare_or_wait_for_session
prepare_or_wait_for_session(
master='',
config=None,
wait_for_checkpoint=False,
max_wait_secs=7200,
start_standard_services=True
)
确保模型已经准备好可以使用。在“master”上创建一个会话,根据需要恢复或初始化模型,或者等待会话就绪。如果将以chief和start_standard_service的身份运行设置为True,还可以调用会话管理器来启动标准服务。
参数:
- master:要使用的TensorFlow master的名称。有关如何解释这一点,请参阅tf.compat.v1.Session构造函数。
config:可选的ConfigProto proto用于配置会话,它按原样传递以创建会话。- wait_for_checkpoint:我们是否应该在创建会话之前等待检查点的可用性。默认值为False。
- max_wait_secs:等待会话可用的最大时间。
- start_standard_services:是否启动标准服务和队列运行器。
返回值:
- 可用于驱动模型的会话对象。
14、request_stop
request_stop(ex=None)
请求协调器停止线程。
参数:
- ex:可选异常,或由sys.exc_info()返回的Python exc_info元组。如果这是对request_stop()的第一个调用,则记录相应的异常并从join()重新引发异常。
15、should_stop
should_stop()
检查协调器是否被告知停止。
返回值:
- 如果协调器被告知停止,则为True,否则为False。
16、start_queue_runners
start_queue_runners(
sess,
queue_runners=None
)
启动队列运行器的线程。注意,当您与管理器创建会话时,graph key queue_runner中收集的队列运行器已经自动启动,因此,除非您启动了非收集的队列运行器,否则不需要显式地调用它。
参数:
sess:一个会话。- queue_runners:一个队列运行器列表。如果没有指定,我们将使用图中键graphkeys . queue_runner下收集的队列运行器列表。
返回值:
- 队列运行器启动的线程列表。
可能产生的异常:
RuntimeError: If called with eager execution enabled.
17、start_standard_services
启动“sess”的标准服务。这将在后台启动服务。启动的服务取决于构造函数的参数,可能包括:
- 一个总结线程计算总结每个save_summaries_secs。
- 每个save_model_secs保存模型的检查点线程。
- StepCounter线程测量步骤时间。
参数:
sess:一个会话。
返回值:
- 运行标准服务的线程列表。您可以使用主管的协调器将这些线程连接到:svg.co.join ()
可能产生的异常:
RuntimeError: If called with a non-chief Supervisor.ValueError: If notlogdirwas passed to the constructor as the services need a log directory.
18、stop
stop(
threads=None,
close_summary_writer=True,
ignore_live_threads=False
)
停止服务和协调器。这不会关闭会话。
参数:
threads:可选的与协调器连接的线程列表。如果没有,则默认为运行标准服务的线程、队列运行器启动的线程和loop()方法启动的线程。若要等待其他线程,请在此参数中传递列表。- close_summary_writer:是否关闭summary_writer。如果摘要编写器是由主管创建的,则默认为True,否则为False。
- ignore_live_threads:如果True忽略通过协调器连接线程时在一段宽限期之后仍然运行的线程,而不是引发RuntimeError。
19、stop_on_exception
stop_on_exception()
上下文处理程序,以在引发异常时停止管理程序。
返回值:
- 一个上下文处理程序。
20、summary_computed
summary_computed(
sess,
summary,
global_step=None
)
指示已计算摘要。
参数:
- sess:会话对象。
summary:摘要原型,或包含序列化摘要原型的字符串。- global_step: Int. global step这个摘要与之关联。如果没有,它将尝试获取当前步骤。
可能产生的异常:
TypeError: if 'summary' is not a Summary proto or a string.RuntimeError: if the Supervisor was created without alogdir.
21、wait_for_stop
wait_for_stop()
阻塞,等待协调器停止。
16、tf.train.Example
一个ProtocolMessage
性质:
Features features
17、tf.compat.v1.train.import_meta_graph
Recreates a Graph saved in a MetaGraphDef proto.
tf.compat.v1.train.import_meta_graph(
meta_graph_or_file,
clear_devices=False,
import_scope=None,
**kwargs
)
This function takes a MetaGraphDef protocol buffer as input. If the argument is a file containing a MetaGraphDef protocol buffer , it constructs a protocol buffer from the file content. The function then adds all the nodes from the graph_def field to the current graph, recreates all the collections, and returns a saver constructed from the saver_def field.
In combination with export_meta_graph(), this function can be used to
-
Serialize a graph along with other Python objects such as
QueueRunner,Variableinto aMetaGraphDef. -
Restart training from a saved graph and checkpoints.
-
Run inference from a saved graph and checkpoints.
...
# Create a saver.
saver = tf.compat.v1.train.Saver(...variables...)
# Remember the training_op we want to run by adding it to a collection.
tf.compat.v1.add_to_collection('train_op', train_op)
sess = tf.compat.v1.Session()
for step in xrange(1000000):
sess.run(train_op)
if step % 1000 == 0:
# Saves checkpoint, which by default also exports a meta_graph
# named 'my-model-global_step.meta'.
saver.save(sess, 'my-model', global_step=step)
Later we can continue training from this saved meta_graph without building the model from scratch.
with tf.Session() as sess:
new_saver =
tf.train.import_meta_graph('my-save-dir/my-model-10000.meta')
new_saver.restore(sess, 'my-save-dir/my-model-10000')
# tf.get_collection() returns a list. In this example we only want
# the first one.
train_op = tf.get_collection('train_op')[0]
for step in xrange(1000000):
sess.run(train_op)
NOTE: Restarting training from saved meta_graph only works if the device assignments have not changed.
Example:
Variables, placeholders, and independent operations can also be stored, as shown in the following example.
# Saving contents and operations.
v1 = tf.placeholder(tf.float32, name="v1")
v2 = tf.placeholder(tf.float32, name="v2")
v3 = tf.math.multiply(v1, v2)
vx = tf.Variable(10.0, name="vx")
v4 = tf.add(v3, vx, name="v4")
saver = tf.train.Saver([vx])
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(vx.assign(tf.add(vx, vx)))
result = sess.run(v4, feed_dict={v1:12.0, v2:3.3})
print(result)
saver.save(sess, "./model_ex1")
Later this model can be restored and contents loaded.
# Restoring variables and running operations.
saver = tf.train.import_meta_graph("./model_ex1.meta")
sess = tf.Session()
saver.restore(sess, "./model_ex1")
result = sess.run("v4:0", feed_dict={"v1:0": 12.0, "v2:0": 3.3})
print(result)
Args:
meta_graph_or_file:MetaGraphDefprotocol buffer or filename (including the path) containing aMetaGraphDef.clear_devices: Whether or not to clear the device field for anOperationorTensorduring import.import_scope: Optionalstring. Name scope to add. Only used when initializing from protocol buffer.**kwargs: Optional keyed arguments.
Returns:
A saver constructed from saver_def in MetaGraphDef or None.
A None value is returned if no variables exist in the MetaGraphDef (i.e., there are no variables to restore).
Raises:
RuntimeError: If called with eager execution enabled.
Eager Compatibility
Exporting/importing meta graphs is not supported. No graph exists when eager execution is enabled.
18、tf.train.get_checkpoint_state
Returns CheckpointState proto from the "checkpoint" file.
Aliases:
tf.compat.v1.train.get_checkpoint_statetf.compat.v2.train.get_checkpoint_state
tf.train.get_checkpoint_state(
checkpoint_dir,
latest_filename=None
)
If the "checkpoint" file contains a valid CheckpointState proto, returns it.
Args:
checkpoint_dir: The directory of checkpoints.latest_filename: Optional name of the checkpoint file. Default to 'checkpoint'.
Returns:
A CheckpointState if the state was available, None otherwise.
Raises:
ValueError: if the checkpoint read doesn't have model_checkpoint_path set.
19、tf.compat.v1.train.start_queue_runners
Starts all queue runners collected in the graph. (deprecated)
Aliases:
tf.compat.v1.train.queue_runner.start_queue_runners
tf.compat.v1.train.start_queue_runners(
sess=None,
coord=None,
daemon=True,
start=True,
collection=tf.GraphKeys.QUEUE_RUNNERS
)
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version. Instructions for updating: To construct input pipelines, use the tf.data module.
This is a companion method to add_queue_runner(). It just starts threads for all queue runners collected in the graph. It returns the list of all threads.
Args:
sess:Sessionused to run the queue ops. Defaults to the default session.coord: OptionalCoordinatorfor coordinating the started threads.daemon: Whether the threads should be marked asdaemons, meaning they don't block program exit.start: Set toFalseto only create the threads, not start them.collection: AGraphKeyspecifying the graph collection to get the queue runners from. Defaults toGraphKeys.QUEUE_RUNNERS.
Raises:
ValueError: ifsessis None and there isn't any default session.TypeError: ifsessis not atf.compat.v1.Sessionobject.
Returns:
- A list of threads.
Raises:
RuntimeError: If called with eager execution enabled.ValueError: If called without a defaulttf.compat.v1.Sessionregistered.
Eager Compatibility
Not compatible with eager execution. To ingest data under eager execution, use the tf.data API instead.
20、tf.compat.v1.train.string_input_producer
Output strings (e.g. filenames) to a queue for an input pipeline. (deprecated)
tf.compat.v1.train.string_input_producer(
string_tensor,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None,
cancel_op=None
)
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version. Instructions for updating: Queue-based input pipelines have been replaced by tf.data. Use tf.data.Dataset.from_tensor_slices(string_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs). If shuffle=False, omit the .shuffle(...).
Note: if num_epochs is not None, this function creates local counter epochs. Use local_variables_initializer() to initialize local variables.
Args:
string_tensor: A 1-D string tensor with the strings to produce.num_epochs: An integer (optional). If specified,string_input_producerproduces each string fromstring_tensornum_epochstimes before generating anOutOfRangeerror. If not specified,string_input_producercan cycle through the strings instring_tensoran unlimited number of times.shuffle: Boolean. If true, the strings are randomly shuffled within each epoch.seed: An integer (optional). Seed used if shuffle == True.capacity: An integer. Sets the queue capacity.shared_name: (optional). If set, this queue will be shared under the given name across multiple sessions. All sessions open to the device which has this queue will be able to access it via the shared_name. Using this in a distributed setting means each name will only be seen by one of the sessions which has access to this operation.name: A name for the operations (optional).cancel_op: Cancel op for the queue (optional).
Returns:
- A queue with the output strings. A
QueueRunnerfor the Queue is added to the currentGraph'sQUEUE_RUNNERcollection.
Raises:
ValueError: If the string_tensor is a null Python list. At runtime, will fail with an assertion if string_tensor becomes a null tensor.
Eager Compatibility
Input pipelines based on Queues are not supported when eager execution is enabled. Please use the tf.data API to ingest data under eager execution.
21、tf.train.Example
Class Example
Aliases:
- Class
tf.compat.v1.train.Example - Class
tf.compat.v2.train.Example
__init__
__init__(**kwargs)
Properties
features
Features features
Methods
ByteSize
ByteSize()
Clear
Clear()
ClearField
ClearField(field_name)
DiscardUnknownFields
DiscardUnknownFields()
FindInitializationErrors
FindInitializationErrors()
Finds required fields which are not initialized.
Returns:
- A list of strings. Each string is a path to an uninitialized field from the top-level message, e.g. "foo.bar[5].baz".
FromString
@staticmethod
FromString(s)
HasField
HasField(field_name)
IsInitialized
IsInitialized(errors=None)
Checks if all required fields of a message are set.
Args:
errors: A list which, if provided, will be populated with the field paths of all missing required fields.
Returns:
- True iff the specified message has all required fields set.
ListFields
ListFields()
MergeFrom
MergeFrom(msg)
MergeFromString
MergeFromString(serialized)
RegisterExtension
@staticmethod
RegisterExtension(extension_handle)
SerializePartialToString
SerializePartialToString(**kwargs)
SerializeToString
SerializeToString(**kwargs)
SetInParent
SetInParent()
Sets the _cached_byte_size_dirty bit to true, and propagates this to our listener iff this was a state change.
UnknownFields
UnknownFields()
WhichOneof
WhichOneof(oneof_name)
Returns the name of the currently set field inside a oneof, or None.
__eq__
__eq__(other)
22、tf.train.Int64List()
Class Int64List
Aliases:
- Class
tf.compat.v1.train.Int64List - Class
tf.compat.v2.train.Int64List
__init__
__init__(**kwargs)
Properties
value
repeated int64 value
Methods
ByteSize
ByteSize()
Clear
Clear()
ClearField
ClearField(field_name)
DiscardUnknownFields
DiscardUnknownFields()
FindInitializationErrors
FindInitializationErrors()
Finds required fields which are not initialized.
Returns:
- A list of strings. Each string is a path to an uninitialized field from the top-level message, e.g. "foo.bar[5].baz".
FromString
@staticmethod
FromString(s)
HasField
HasField(field_name)
IsInitialized
IsInitialized(errors=None)
Checks if all required fields of a message are set.
Args:
errors: A list which, if provided, will be populated with the field paths of all missing required fields.
Returns:
- True iff the specified message has all required fields set.
ListFields
ListFields()
MergeFrom
MergeFrom(msg)
MergeFromString
MergeFromString(serialized)
RegisterExtension
@staticmethod
RegisterExtension(extension_handle)
SerializePartialToString
SerializePartialToString(**kwargs)
SerializeToString
SerializeToString(**kwargs)
SetInParent
SetInParent()
Sets the _cached_byte_size_dirty bit to true, and propagates this to our listener iff this was a state change.
UnknownFields
UnknownFields()
WhichOneof
WhichOneof(oneof_name)
Returns the name of the currently set field inside a oneof, or None.
__eq__
__eq__(other)
23、tf.train.BytesList
Class BytesList
Aliases:
- Class
tf.compat.v1.train.BytesList - Class
tf.compat.v2.train.BytesList
__init__
__init__(**kwargs)
Properties
value
repeated bytes value
Methods
ByteSize
ByteSize()
Clear
Clear()
ClearField
ClearField(field_name)
DiscardUnknownFields
DiscardUnknownFields()
FindInitializationErrors
FindInitializationErrors()
Finds required fields which are not initialized.
Returns:
- A list of strings. Each string is a path to an uninitialized field from the top-level message, e.g. "foo.bar[5].baz".
FromString
@staticmethod
FromString(s)
HasField
HasField(field_name)
IsInitialized
IsInitialized(errors=None)
Checks if all required fields of a message are set.
Args:
errors: A list which, if provided, will be populated with the field paths of all missing required fields.
Returns:
- True iff the specified message has all required fields set.
ListFields
ListFields()
MergeFrom
MergeFrom(msg)
MergeFromString
MergeFromString(serialized)
RegisterExtension
@staticmethod
RegisterExtension(extension_handle)
SerializePartialToString
SerializePartialToString(**kwargs)
SerializeToString
SerializeToString(**kwargs)
SetInParent
SetInParent()
Sets the _cached_byte_size_dirty bit to true, and propagates this to our listener iff this was a state change.
UnknownFields
UnknownFields()
WhichOneof
WhichOneof(oneof_name)
Returns the name of the currently set field inside a oneof, or None.
__eq__
__eq__(other)
22、tf.compat.v1.train.shuffle_batch_join
Create batches by randomly shuffling tensors. (deprecated)
tf.compat.v1.train.shuffle_batch_join(
tensors_list,
batch_size,
capacity,
min_after_dequeue,
seed=None,
enqueue_many=False,
shapes=None,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version. Instructions for updating: Queue-based input pipelines have been replaced by tf.data. Use tf.data.Dataset.interleave(...).shuffle(min_after_dequeue).batch(batch_size).
The tensors_list argument is a list of tuples of tensors, or a list of dictionaries of tensors. Each element in the list is treated similarly to the tensors argument of tf.compat.v1.train.shuffle_batch().
This version enqueues a different list of tensors in different threads. It adds the following to the current Graph:
- A shuffling queue into which tensors from
tensors_listare enqueued. - A
dequeue_manyoperation to create batches from the queue. - A
QueueRunnertoQUEUE_RUNNERcollection, to enqueue the tensors fromtensors_list.
len(tensors_list) threads will be started, with thread i enqueuing the tensors from tensors_list[i]. tensors_list[i1][j] must match tensors_list[i2][j] in type and shape, except in the first dimension if enqueue_many is true.
If enqueue_many is False, each tensors_list[i] is assumed to represent a single example. An input tensor with shape [x, y, z] will be output as a tensor with shape [batch_size, x, y, z].
If enqueue_many is True, tensors_list[i] is assumed to represent a batch of examples, where the first dimension is indexed by example, and all members of tensors_list[i] should have the same size in the first dimension. If an input tensor has shape [*, x, y, z], the output will have shape [batch_size, x, y, z].
The capacity argument controls the how long the prefetching is allowed to grow the queues.
The returned operation is a dequeue operation and will throw tf.errors.OutOfRangeError if the input queue is exhausted. If this operation is feeding another input queue, its queue runner will catch this exception, however, if this operation is used in your main thread you are responsible for catching this yourself.
If allow_smaller_final_batch is True, a smaller batch value than batch_size is returned when the queue is closed and there are not enough elements to fill the batch, otherwise the pending elements are discarded. In addition, all output tensors' static shapes, as accessed via the shape property will have a first Dimension value of None, and operations that depend on fixed batch_size would fail.
Args:
tensors_list: A list of tuples or dictionaries of tensors to enqueue.batch_size: An integer. The new batch size pulled from the queue.capacity: An integer. The maximum number of elements in the queue.min_after_dequeue: Minimum number elements in the queue after a dequeue, used to ensure a level of mixing of elements.seed: Seed for the random shuffling within the queue.enqueue_many: Whether each tensor intensor_list_listis a single example.shapes: (Optional) The shapes for each example. Defaults to the inferred shapes fortensors_list[i].allow_smaller_final_batch: (Optional) Boolean. IfTrue, allow the final batch to be smaller if there are insufficient items left in the queue.shared_name: (optional). If set, this queue will be shared under the given name across multiple sessions.name: (Optional) A name for the operations.
Returns:
- A list or dictionary of tensors with the same number and types as
tensors_list[i].
Raises:
ValueError: If theshapesare not specified, and cannot be inferred from the elements oftensors_list.
Eager Compatibility
Input pipelines based on Queues are not supported when eager execution is enabled. Please use the tf.data API to ingest data under eager execution.
23、tf.train.Feature
Class Feature
A ProtocolMessage
Used in the tutorials:
- TFRecord and tf.Example
Properties
bytes_list
BytesList bytes_list
float_list
FloatList float_list
int64_list
Int64List int64_list
Compat aliases
tf.compat.v1.train.Featuretf.compat.v2.train.Feature