Java中正则表达式示例及元字符的记忆规律
前言:
关于正则表达式有很多博客都有写,这里在参考大量博客的基础上进行了整理,以便日后自己回过头再学习。本文不仅记录了个人对正则表达式的概念理解,同时对正则表达式中的元字符进行了分类,不仅方便了对元字符的理解,同时还便于记忆。本文力图使用通俗的语言和易懂的示例来记录正则表达式,但是有些地方不免俗套,必须使用晦涩难懂的语言来注明,以纠正通俗语言有时候带来的语义上的理解不到位的情形。
码字不易,且读且珍惜。
目录
前言:
一 正则表达式简介
1 概念
2 作用
3 使用场景4个:匹配字符串、切割字符串、替换字符串、获取字符串
二 正则表达式元字符的记忆规律
三 Java中的正则表达式类:Pattern 和Matcher 类
四 常见的需要验证的字符串格式
五 正则表达式的实例:匹配、切割、替换、获取
1 匹配 matches
2 切割 split方法
3 替换 replaceAll() (利用替换删除特定字符:替换为空)
4 获取 group( )方法
六 Java 正则表达式的一些匹配模式
七 一些坑
1 Pattern.DOTALL
2 []符号,中括号表示其中的数据都是或的关系
3 转义符号 \
4 [\s\S]
5 String.matches(regex),Pattern.matches(regex, str),Matcher.matches()
6 split的坑
7 . | / 的转义
8 判断字符串是否为空 ^$
八 参考博客
一 正则表达式简介
为了便于理解什么是正则表达式,首先来看一个小例子:
下面是6个简单的字符串,思考一个问题,怎么样用简短的中文来描述这些字符串???
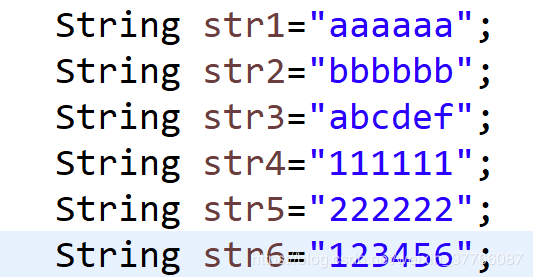
对于str1, 我们可能这样描述比较简便:6个a,或者小写字母a,这样就足以描述这样一串字符串,如果字符串的长度更长一些,你依然只需要用很简短的语言就可以代表这个字符串了,比如,400个a,想一下,这得是多长的字符串。
对于str3,显然用 “几个a” 的方式来描述“abcdef”显然不合适,你总不能向别人介绍这段字符串的时候说:1个a 1个b 1个c。。。吧。这时候就需要找规律了,找到最能代表这个字符串的规律,比如:6个字母或者6个小写字母。
对于数字字符串str4和str6同样是这种分析规律,如下图:

我们可以看到,上述用中文描述左侧字符串的方式确实很简单,这样描述字符串对于我们人类来说毫无问题,但是问题来了,计算机又不认识这样的描述方式,那怎么办???于是乎,为了让计算机也能够表示并且读得懂这样简便的描述字符串的方式,聪明的人类发明了一种标记字符串的方式,并且给这中标记方式起了一个高大上的名字,称之为:正则表达式。事实上,我们的 “6个a” 也是一种"正则表达式",只不过这种"正则表达式"计算机并不认识而已。
接下来,就来看看怎么用正则表达式来描述上述字符串:
观察上述“中文正则表达式”,可以发现,正则表达式的表达方式很简单嘛(其实可以做的很复杂,这里夸张一下),无非就是两个问题: 1 是什么字符 2字符出现了几次的问题。
以str1和str3 为例:str1 的中文正则表达式: 第一:是什么字符:a 第二:出现几次:6次
str3 的中文表达式: 1 是什么字符:小写字母 2 出现几次: 6次
那么怎么用计算机可以表示的呢???这里先透露一点点正则表达式知识:
正则表达式可以用 一对大括号 { 数字} 表示次数,如{ 6 } 表示出现了6次,字母的表示方法:[a-z],表示a到z中的任何一个。
搞清楚这个,就可以写正则表达式了,如下:
以str1和str3 为例:str1 的英文文正则表达式: 第一:是什么字符:a 第二:出现几次:6次 合起来写:a{6}
str3 的英文文表达式: 1 是什么字符:小写字母 2 出现几次: 6次 合起来写:[a-z]{6}
当计算机读到:a{6}的时候,就知道,原来你在找6个a啊,马上安排。
对于剩下的字符串也是这样分析,如下图:

理解了上述的小例子,我觉得也算是半只脚踏进了正则表达式的大门。但是正则表达式可不止是这么简单,还需要继续学下去。
1 概念
大白话的理解:正则表达式就是表达一串字符串的规则,用来描述 是什么字符以及出现了几次的问题。
高大上的概念:正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
(大白话是不是好理解很多)
2 作用
其实我在介绍上述小例子的时候,用黑体字也标注了,正则表达式的作用无非就是 描述字符串方便。
3 使用场景4个:匹配字符串、切割字符串、替换字符串、获取字符串
匹配:就是看字符串是否符合某一正则表达式描述,如上述例子: a{6} 是不是表示 “aaaaaa” , 很明显是的,匹配成功,计算机告诉你一个结果:是的,即true。(具体怎么用后面在介绍)
切割:按照某一个子字符串来把长的字符串分开,这个子字符串使用正则表达式表示的。如:String str=baaaaaac,已知字符串的切割函数:split(),现在让你用6个a把这段字符串切割一下,不用正则表达式:str.split( "aaaaaa" ) , 用正则表达式:str.split( "a{6}"); 对比一下,是不是很方便(其实aaaaaa本身就是一种正则,但是是不方便的正则)。
替换字符串:把字符串中的某一段子字符串替换成另一个字符串。如:String str=baaaaaac,已知java的字符串替换函数:repalceAll(old ,new), 现在让你把6个a替换成6个b,先看一下不用正则表达式的场景:str.replaceAll("aaaaaa","bbbbbb");(其实可以写一个str.replaceAll("a","b"),这里主要为了举例) 用正则表达式:str.replaceAll("a{6}","b{6}");(很方便)
获取字符串:把符合某一种正则表达式的字符串取出来。
二 正则表达式元字符的记忆规律
参看大量博客之后,发现基本上都是甩给你一张表格,然后在表格中罗列相关的符号是什么含义。个人觉得这种方式对于初学者太不友好了,很难理解,还不便于记忆。当然,本文也不落俗套,这样的表格是必须给出的,但是在给出表格之前,这里给出一张分类表,也就是现将正则的元字符分一下类,这样便于理解和记忆。至于内容,该记忆还是要记忆的。
前面说了,正则表达式就是解决是什么字符,字符出现了几次的问题,其实这里说的简单了点,这里还要深入考虑一下,字符串之间的组合问题(或与非)以及正则表达式的匹配位置(在当前位置之前匹配还是在当前位置匹配还是匹配当前位置)问题。因此,我将正则表达式分为四大块,如下图:

注意:
1 默认情况下,都是贪婪的匹配模式,当在表示次数的负号后面加上?时,表示勉强匹配模式。
贪婪匹配模式:匹配符合条件的最长字符串
勉强匹配模式:匹配符合条件的最短字符串。
2 解释两个好听的名词:零宽断言和负向零宽断言 (注:只能放在正则的开始或末尾,才能正确匹配)
零宽断言:用于判断一个字符串之前或之后是否存在符合某种正则的另一种字符串。
零宽断言:(?=pattern)大白话理解:就是判断符合(?=pattern)前面的正则表达式的字符串是否以指定模式pattern结尾,返回的时候不包含模式pattern的字符串。
public static void main(String[] args){
String str1="i sing you";
Pattern p=Pattern.compile("\\b\\w+(?=ng\\b)");
Matcher m=p.matcher(str1);
while(m.find()){
System.out.println(m.group(0)); //输出 si , si是以ng结尾的,不返回ng。
}
}(?<=pattern)大白话理解:就是判断符合(?<=pattern)后面的正则表达式的字符串是否以指定模式pattern开头,返回的时候不包含模式pattern的字符串
public static void main(String[] args){
String str1="i sing you";
Pattern p=Pattern.compile("(?<=si)\\w+\\b"); //判断符合\\w+\\b的字符串是否以si开头
Matcher m=p.matcher(str1);
while(m.find()){
System.out.println(m.group(0)); //输出ng
}
}负向零宽断言:用来匹配某一字符串的前面或后面不存在某个字符串。
(?!pattern):大白话理解:就是判断符合(?!pattern)前面的正则表达式的字符串是否不以指定模式pattern结尾。
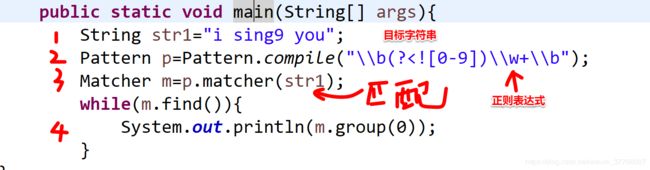
public static void main(String[] args){
String str1="i sing9 you";
Pattern p=Pattern.compile("\\b[a-z]+(?![0-9])\\b"); //匹配不以9结束的字符串
Matcher m=p.matcher(str1);
while(m.find()){
System.out.println(m.group(0)); //输出 i you ,不输出sing9
}(?<!pattern):大白话理解:就是判断符合(?!pattern)后面的正则表达式的字符串是否不以指定模式pattern开始。
public static void main(String[] args){
String str1="i sing9 you";
Pattern p=Pattern.compile("\\b(?3 上图中还有少数的正则并未写上,详细见下表。
| 元字符 |
描述 |
| \ |
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ |
匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ |
匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * |
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 |
| + |
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
| {n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
| .点 |
匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) |
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
| (?:pattern) |
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) |
非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) |
非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) |
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 “(?<=95|98|NT|2000)Windows”目前在python3.6中re模块测试会报错,用“|”连接的字符串长度必须一样,这里“95|98|NT”的长度都是2,“2000”的长度是4,会报错。 |
| (? |
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(? 此处用或任意一项都不能超过2位,如“(? 同上,这里在python3.6中re模块中字符串长度要一致,并不是一定为2,比如“(? |
| x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] |
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b |
匹配一个只能是 \w (也就是字母数字下划线)的单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx |
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d |
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D |
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f |
匹配一个换页符。等价于\x0c和\cL。 |
| \n |
匹配一个换行符。等价于\x0a和\cJ。 |
| \r |
匹配一个回车符。等价于\x0d和\cM。 |
| \s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S |
匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t |
匹配一个制表符。等价于\x09和\cI。 |
| \v |
匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W |
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn |
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
| \num |
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n |
标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm |
标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml |
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un |
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
| \p{P} |
小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。 其他六个属性: L:字母; M:标记符号(一般不会单独出现); Z:分隔符(比如空格、换行等); S:符号(比如数学符号、货币符号等); N:数字(比如阿拉伯数字、罗马数字等); C:其他字符。 *注:此语法部分语言不支持,例:javascript。 |
| \< \> |
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\ |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
三 Java中的正则表达式类:Pattern 和Matcher 类
Java中的正则表达式类就是Pattern 和Matcher类,使用模式是固定的,代码 如下:
在Java的String 类中,有三个方法也可以进行正则表达式判断: split 、 replaceAll() 以及 matches () ,这三个函数可以简化字符串的匹配替换,但是功能远远没有Patter和Mathcer类多,实际上,这三种方法都能在Patter和Matcher中找到。
四 常见的需要验证的字符串格式
-
字符串仅能是中文 :^[\\u4e00-\\u9fa5]{0,}$
-
非零的正整数:^[1-9]\d*$
-
非正浮点数:^(-\d+(\.\d+)?)$
-
邮箱::^\w+([-+.]\w+)*@(\w+-?\w+)(\.\w+-?\w+)+$
-
国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
-
身份证号(15位、18位数字)^\d{15}|\d{18}$
-
过滤出中文的正则表达式 [^(\\u4e00-\\u9fa5)]
-
过滤出字母、数字和中文的正则表达式 [^(a-zA-Z0-9\\u4e00-\\u9fa5)]
五 正则表达式的实例:匹配、切割、替换、获取
1 匹配 matches
public void test(){
//匹配整个字符串
String str = "asfsdaf14434dDFSFD";
String reg = "\\w*";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(str);
System.out.println(matcher.matches());
}直接用字符串的matches方法:
public void test(){
//匹配整个字符串
String str = "asfsdaf14434dDFSFD";
System.out.println(str.matches("\\w*"));
}2 切割 split方法
String regEx=":";
Pattern pat = Pattern.compile(regEx);
String[] rs = pat.split("aa:bb:cc");
//或者
String str="fssf";
str.split("ss");叠词的分割示例:(.)\\1+
public static void main(String[] args)throws CloneNotSupportedException {
String str="我@@@爱ddd中sss国";
System.out.println(Arrays.toString(str.split("(.)\\1+")));
或者
System.out.println(Arrays.toString(str.split("@+|d+|s+")));
}
3 替换 replaceAll() (利用替换删除特定字符:替换为空)
String regEx="@+"; //表示一个或多个@
Pattern pat=Pattern.compile(regEx);
Matcher mat=pat.matcher("@@aa@b cc@@");
String s=mat.replaceAll("#");
4 获取 group( )方法
String regEx = ".+\(.+)$";
String s = "c:\test.txt";
Pattern pat = Pattern.compile(regEx);
Matcher mat = pat.matcher(s);
boolean rs = mat.find();
for(int i=1;i<=mat.groupCount();i++){
System.out.println(mat.group(i));
}
group ()函数示例:将字符串中的邮箱提取出来:
从下列字符串中提取出邮箱,并打印
字符串:String str="[email protected]";
方法一:切割替换法(定与不定):通过字符串本身的split方法和replaceAll方法进行提取,用定的部分切割,不定的部分替换
public static void main(String[]args) throws Exception{
String str="[email protected]";
String [] str1=str.split("[0-9]{2,9}(@163\\.com)"); // 固定部分分割
System.out.println(Arrays.toString(str1));
for(int i=0;i方法二:索引子串法:通过matcher 类对象的find()方法找到符合该正则的子串的索引起始,再利用字符串的substring()打印。
代码如下:
public class SocketTest{
public static void main(String[]args) throws Exception{
//查找是否包含了某字符串
String str="[email protected]@[email protected]@163.comewdf";
String pattern="[0-9]*(@163.com)";
Pattern p=Pattern.compile(pattern);
Matcher m=p.matcher(str);
int count=0;
while(m.find()){
//统计符合条件的字符串出现了几次
count++;
System.out.println("第次数:"+count);
//输出符合条件的字符串的开始索引
System.out.println("start():"+m.start());
System.out.println("end():"+m.end());
//输出子串
System.out.println(str.substring(m.start(), m.end()));
}
}
}六 Java 正则表达式的一些匹配模式
参考博客:http://developer.51cto.com/art/201710/555214.htm
先尝试执行下面的代码:
println("play \n scala".matches(".*")) 你没看错,打印结果是false。正如键盘布局一样,这是由于一个历史问题导致的。早期的正则表达式工具是基于行处理文本的,所以.匹配的是除换行符以外的任意字符。大多数编程语言在设计正则表达式时沿用了这个传统,但是提供一个选项用于开启"点号匹配换行符"模式。
Java提供了两种方式开启"点号匹配换行符"模式,第一种方式是在构建Pattern对象时指定匹配模式:
val p = Pattern.compile(".*", Pattern.DOTALL)
println(p.matcher("play\nscala").matches()) // true 另一种方式是在正则表达式开始位置指定嵌入模式修饰符(embedded mode modifier),这也是一种比较通用的方式:
println("play\nscala".matches("(?s).*")) // true Pattern.DOTALL和(?s)是等价的。
Java常用的匹配模式有以下几种:
1) Pattern.DOTALL
启用dotall模式。在dotall模式下,模式中的.匹配任意字符,包括换行符。在默认情况下(即未启用dotall模式),.不匹配换行符。等价于修饰符(?s)。
val p = Pattern.compile(".*", Pattern.DOTALL)
val m = p.matcher("play\nscala")
println(m.matches())
// 输出
true 2)Pattern.MULTILINE
启用多行匹配模式。在多行匹配模式下,模式中的^和$将逐次匹配每一行的行首和行尾。在默认情况下(即未启用多行匹配模式),^和$将匹配整个字符串的首部和尾部。等价于修饰符(?m)。
val p = Pattern.compile("^.*$", Pattern.MULTILINE)
val m = p.matcher("play\nscala")
while (m.find()) {
println("find: " + m.group(0))
}
// 输出
find: play
find: scala 3) Pattern.UNIX_LINES
启用Unix换行模式,使用"\n"标识每一行的末尾,等价于修饰符(?d)。
val p = Pattern.compile("^.*$", Pattern.UNIX_LINES | Pattern.MULTILINE)
val m = p.matcher("play\r\nscala")
while (m.find()) {
println("find: " + m.group(0).length)
}
// 输出
find: 5
find: 5 输出的两个结果长度都为5,原因是play末尾还有一个字符\r。
4)Pattern.CASE_INSENSITIVE
启用大小写不敏感匹配,等价于修饰符(?i)。
val p = Pattern.compile("^S.*A$", Pattern.CASE_INSENSITIVE)
val m = p.matcher("scala")
println(m.matches())
// 输出
true 5)Pattern.LITERAL
启用字面(literal)模式解析,模式中的元字符和转义字符将按照普通字符解析。
val p = Pattern.compile(".*", Pattern.LITERAL)
val m = p.matcher("scala")
println(m.matches())
// 输出
false 6)Pattern.COMMENTS
正则表达式中允许出现空白符(whitespace)和注解(comments),空白符会被忽略,以#开头的注解行也将被忽略,等价于修饰符(?x);
val p = Pattern.compile(" .* ", Pattern.COMMENTS)
val m = p.matcher("scala")
println(m.matches())
// 输出
true 注:有些编程语言(例如JavaScript)不支持嵌入模式修饰符(embedded mode modifier),这时可以使用另一种解决方案:[\s\S]*
[\s]会匹配任意空白字符,[\S]而则会匹配[\s]不能匹配的任意字符。把这二者组合起来构成[\s\S],这样就会得到一个包含所有字符的字符组,其中也包含了换行符。
七 一些坑
1 Pattern.DOTALL
Pattern.DOTALL,启用 dotall 模式。在 dotall 模式中,表达式 . 可以匹配任何字符,包括行结束符。默认情况下,此表达式不匹配行结束符。
2 []符号,中括号表示其中的数据都是或的关系
如果[\\w+]是匹配条件 abc是否可以匹配的到呢?
首先\\w表示a-z A-Z 0-9 _多个字符组合,显然abc任意一个在里面的,后又有+号,表示有多个字符,所以abc可以匹配\\w+ 。 但是[\\w+]表示的意思是多个字符的或,注意是或,所以[\\w+]等同于[a-z|A-Z|0-9|_],这里面的或只有单个字符
所以a或者b或者c都可以匹配[\\w+],但是abc不可以,如何让abc可以匹配呢很简单只需要将条件外面加上+号标识多个字符就可以了。
3 转义符号 \
java中\是没有意义的,在字符串中你出现一个\,编译器会告诉你是错误的,不能这样
所以java中\\表示一个\。在正则表达式匹配中如匹配数字写的是\\d其实是\\表示一个\最后的效果是\d.
这个时候有人要问了,我只要匹配\d这个字符而不是匹配数字怎么办,这个时候需要在加一个转义符,告诉大家这个字符不是\d表示的数字,而是具体字符串\d,具体的结果是很蛋疼的在加上一个转义字符\\,所以会出现\\\\d,java会解析成\\d,表示对\d在做转义,就是单纯的\d。
再比如[\\]这个简单的表达式,如果你去调用则会报错,为什么?
因为java会认为你只传了一个转义符,而单独的转义符是没有意义的,如果你要匹配\号,需要的表达式是\\\\前面的\\表示转义符号,后面的\\表示真正匹配的\号。- -!
java转义字符关键是两个\\表示一个\,会让人费解,需要注意。
4 [\s\S]
[\s]会匹配任意空白字符,[\S]而则会匹配[\s]不能匹配的任意字符。把这二者组合起来构成[\s\S],这样就会得到一个包含所有字符的字符组,其中也包含了换行符。
5 String.matches(regex),Pattern.matches(regex, str),Matcher.matches()
String.matches(regex),Pattern.matches(regex, str),Matcher.matches()都是全局匹配的,相当于"^regex$"的正则匹配结果。如果不想使用全局匹配则可以使用Matcher.find()方法进行部分查找。
分析:String.matches(regex)方法本质调用了Pattern.matches(regex, str),而该方法调Pattern.compile(regex).matcher(input).matches()方法,而Matcher.matches()方法试图将整个区域与模式匹配,如果匹配成功,则可以通过开始、结束和组方法获得更多信息。
6 split的坑
原文:https://blog.csdn.net/simon_it/article/details/80184769
Java的split默认是根据指定的字符去截取,然后末尾如果都是空字符串,那么全部舍去,除非你限定长度。
String ids = "1,2,3,";
String[] idArr = ids.split(",");
String idA = idArr[0];
String idB = idArr[1];
String idC = idArr[2];
String idD = idArr[3];// 抛出数组下标越界了。
// 新手,或者不常用split的人总是会认为idArr的长度应该是4,实际上他只有3。是的这就是java中的split,因为你在别的地方用过的split不是这样的,比如javascript中的split,如果是这个例子的话,那么毫无疑问他的长度是4,最后一个为""空字符串。
// 实际上java的split有一个重载方法,是两个参数的,第二个参数就是你期望数组的长度,当然如果你写100,那么你也不可能得到长度为100的数组在本例当中,他是个limit的概念。
String[] idArr = ids.split(",",4); // 这有写长度是4
String[] idArr = ids.split(",",100); // 这有写长度也是4
String[] idArr = ids.split(",",3); // 这有写长度是3
String[] idArr = ids.split(",",2); // 这有写长度是2
// ok看到这里大家应该明白了,所以java的split默认是根据指定的字符去截取,然后末尾如果都是空字符串,那么全部舍去,除非你限定长度。
// 而javascript确实默认没有去处理空字符串的问题。7 . | / 的转义
(1)如果用“.”作为分隔的话,必须是如下写法:String.split("\\."),这样才能正确的分隔开,不能用String.split(".");
(2)如果用“|”作为分隔的话,必须是如下写法:String.split("\\|"),这样才能正确的分隔开,不能用String.split("|"); “.”和“|”都是转义字符,必须得加"\\"; 这里也很容易写成:String.split("\|"),这里错的原因是:正则表达式中 \ 也是转义字符,所以还要加上一个 反斜线,即:String.split("\\|")。
(3)如果在一个字符串中有多个分隔符,可以用“|”作为连字符,比如:“a=1 and b =2 or c=3”,把三个都分隔出来,可以用String.split("and|or");
8 判断字符串是否为空 ^$
public static void main(String[] args){
String str1="";
System.out.println(str1.matches("^$")); //true
}9 对组的引用 \\1 至 \\9
\\1 表示对第一个出现的组的引用,并且第一个组表示什么字符,后面是表示完全一样的字符,类似替换,主要是少写代码。 同理:\\2 是对第二个出现的组的引用
如:示例1:叠词的分割中:
public static void main(String[] args)throws CloneNotSupportedException {
String str="我@@@爱ddd中sss国";
System.out.println(Arrays.toString(str.split("(.)\\1+")));
}示例2:这个示例演示了第一个组表示什么字符,在引用\\1出就表示完全一样的字符,看代码就一目了然了。
public static void main(String[] args)throws CloneNotSupportedException {
String str="高sdfd统sfsa";
System.out.println((str.matches("高(\\w{4})统\\1"))); //false,\\1是对第一次出现的字符的引用,第一次是sdfd, 那么在这个位置只有出现sdfd才能返回true, 如下所示:
}
public static void main(String[] args)throws CloneNotSupportedException {
String str="高sdfd统sdfd";
System.out.println((str.matches("高(\\w{4})统\\1"))); //true
}八 参考博客
1 https://www.cnblogs.com/yuxiaole/p/9380104.html(概念贴)
2 https://www.jb51.net/article/110237.htm
3 https://www.easck.com/cos/2019/0613/302737_3.shtml (实例贴)
4 https://www.cnblogs.com/xyou/p/7427779.html (超级详细,有耐心的看)
5 https://www.cnblogs.com/zheting/p/7745506.html (对每个符号有详细的介绍)
6 https://www.cnblogs.com/xuemaxiongfeng/archive/2013/08/04/3236420.html
7http://developer.51cto.com/art/201710/555214.htm (java的匹配模式)
8 https://blog.csdn.net/moakun/article/details/83187067