darknet版YOLOv4训练自己的数据(详尽版)
YOLOv4最近几乎刷屏了CV界,要说有多牛批,就一句话:同样的效果,速度吊打一切;同样的速度,效果吊打一切。
当然,是否真的有描述的那么厉害,还得检验它的通用性,也就是能不能为我们的数据所用。
废话不多说,直接上教程。
1.源码与论文下载:
YOLO v4 论文:https://arxiv.org/abs/2004.10934
YOLO v4 开源代码:https://github.com/AlexeyAB/darknet
大家可以直接在github上下载AB版本的YOLOv4代码,有余力的童鞋可以看看论文。简单来说,YOLOv4的创新点就在于各种数据增强的方式以及新的网络结构。
2.数据集的准备:
本文的目的就是为了教大家如何使用YOLOv4训练自己的模型,因此数据集的重要性不言而喻。
在这里为了实验方便,本文使用了pascalVOC2007的数据集作为样例,大家可以按照方法更换成自己的数据集。
数据集的下载路径我会放在网盘中供大家下载使用。
打开我们的数据集文件夹VOC2007_Ori可以看到:

在这里我们只需要用到JPEGImages和Annotations这两个文件夹。前者是图片,jpg格式的。后者是每张图片对应的标签信息,xml格式的。标签信息中最主要的内容就是相对应的图片中包含的物体类别以及它们的坐标位置信息。
这里需要注意的是,pascalVOC2007提供的是尺寸大小不一的图片,没有办法直接在统一的分辨率下获取Anchor。因此,我们必须预先处理成训练所需的分辨率,也就是yolov4.cfg模型中的608x608。
VOC2007_608_608即为resize之后的图片与标签文件夹。
接下来我们需要对数据集进行处理。
我们需要在VOC2007_608_608的同级目录中创建maketxt.py和voc_label.py两个脚本文件,如下所示:

(1)生成文件名maketxt.py:
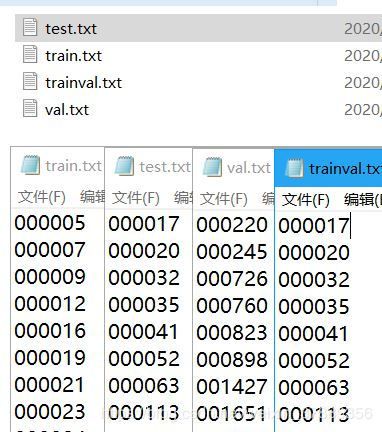
该脚本会在VOC2007_608_608/ImageSets文件夹下生成:trainval.txt, test.txt, train.txt, val.txt,内容如下图所示,将图片分成了训练集,验证集和测试集,并将文件名(不带扩展名)汇总在txt文件中。
生成的文件结构以及文件内容如下图所示:
代码如下:
#-*- coding:utf-8 -*
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'VOC2007_608_608/Annotations'
txtsavepath = 'VOC2007_608_608/ImageSets'
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOC2007_608_608/ImageSets/trainval.txt', 'w')
ftest = open('VOC2007_608_608/ImageSets/test.txt', 'w')
ftrain = open('VOC2007_608_608/ImageSets/train.txt', 'w')
fval = open('VOC2007_608_608/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
(2)生成训练路径voc_label.py
此脚本将在VOC2007_608_608文件夹下生成images和labels两个文件夹用于训练。images文件夹下储存训练图片,labels文件夹下储存相应的标签文件。这里的标签文件全部是由原xml文件转化而来的txt文件,且将坐标位置信息全部归一化处理,代码如下。
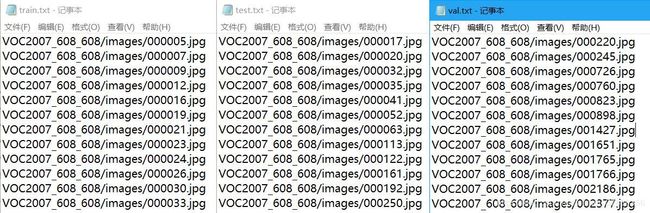
与此同时,还会生成test.txt, train.txt, val.txt,分别储存了测试集图片路径,训练集图片路径,评估集图片路径(与(1)中生成的不同,请注意)
需要注意的是,代码中第9行的classes对应的是训练集中的标签,如果你使用本文中的训练集,那就无需改动;如果你使用自己的训练集,这里需要修改成你自己的标签。
生成的训练路径如下:
代码如下:
#-*- coding:utf-8 -*
import xml.etree.ElementTree as ET
import pickle
import os
import shutil
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['person','bird','cat','cow','dog','horse','sheep','aeroplane','bicycle','boat','bus','car','motorbike','train','bottle','chair','diningtable','pottedplant','sofa','tvmonitor']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOC2007_608_608/Annotations/%s.xml' % (image_id))
out_file = open('VOC2007_608_608/labels/%s.txt' % (image_id), 'w')
print(in_file)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('VOC2007_608_608/labels/'):
os.makedirs('VOC2007_608_608/labels/')
image_ids = open('VOC2007_608_608/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('VOC2007_608_608/%s.txt' % (image_set), 'w')
for image_id in image_ids:
if not os.path.exists('VOC2007_608_608/images/'):
os.makedirs('VOC2007_608_608/images/')
shutil.copy('VOC2007_608_608/JPEGImages/%s.jpg' % (image_id),'VOC2007_608_608/images/%s.jpg' % (image_id))
convert_annotation(image_id)
list_file.close()至此,我们的数据集就处理完毕了!
3.YOLOv4训练
本次训练是在Linux上完成的。
3.1 Makefile配置信息修改
首先将文件解压在Linux系统上,并进入该文件夹,执行make命令进行编译,在Makefile文件夹中需要有几处进行修改,如下:
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=1
AVX=1
OPENMP=1
LIBSO=1
ZED_CAMERA=0 # ZED SDK 3.0 and above
ZED_CAMERA_v2_8=0 # ZED SDK 2.X原始Makefile文件中第1行 GPU=0, 第2行 CUDNN = 0,这会导致GPU无法启用而使用CPU进行训练,将这两项改为1即可启用GPU训练。
原始原始Makefile文件中第4行 OPENCV = 0,这会导致不编译OPENCV,那就会使得YOLOv4中诸多数据增强方法无法使用(如Mosaic),所以改为1来启用OPENCV。
始原始Makefile文件中第7行LIBSO = 0,这会导致编译完成以后不生成libdarknet.so,那么在运行darknet.py进行推理时会报错“OSError: /libdarknet.so: cannot open shared object file: No such file or directory”,改为1将解决这个问题。
有部分同学出现了error:/usr/bin/ld: 找不到 -lippicv 或 /usr/bin/ld -lippicv not found 类似的问题,这是因为你的opencv配置的地址没有让Makefile在编译的时候搜索到。需要将第90行和第91行配置成你自己opencv的地址即可解决。
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv4 2> /dev/null || pkg-config --libs opencv`
COMMON+= `pkg-config --cflags opencv4 2> /dev/null || pkg-config --cflags opencv`
endif至此,Makefile配置完毕,直接make即可~
3.2 训练文件准备:
训练需要三个文件,分别是yolo.names, yolo.data, yolov4.cfg,下面逐一说明如何制作:
yolo.names
其中储存了所有样本的目标类别,pascalVOC2007数据集总共有20类,如下:
person,bird,cat,cow,dog,horse,bicycle,boat,bus,car,motorbike,train,bottle,chair,diningtable,pottedplant,sofa,tvmonitor

yolo.data
储存了类别数,训练集路径,验证集路径,yolo.names路径,以及权重保存路径。

yolov4.cfg
官方提供的YOLOv4网络结构,也是核心所在,存放于cfg文件夹下,其中有几处需要更改
即三个yolo层的前一层滤波器个数,原始yolov4的filters = 255,是因为原始数据集为80类,而 (80+5)*3 = 255。这里需要换成20类的pascalVOC2007数据集,所以滤波器个数是 (20+5)*3 = 75
每个yolo层的anchors和classes也需要修改。
至此,三个训练文件已经准备完毕!
3.3 模型训练
训练命令与yolov3没有差别。
首先进入到源码的目录下
如果同学们想从头开始训练,那么执行以下命令:
./darknet detetor train pascalVOC2007/yolo.data pascalVOC2007/yolov4.cfg如果同学们有预训练模型,那么执行以下命令:
./darknet detetor train pascalVOC2007/yolo.data pascalVOC2007/yolov4.cfg yolov4.conv.137训练开始!
yolov4支持loss可视化,每个batch的loss都会输出在图表上,如下:
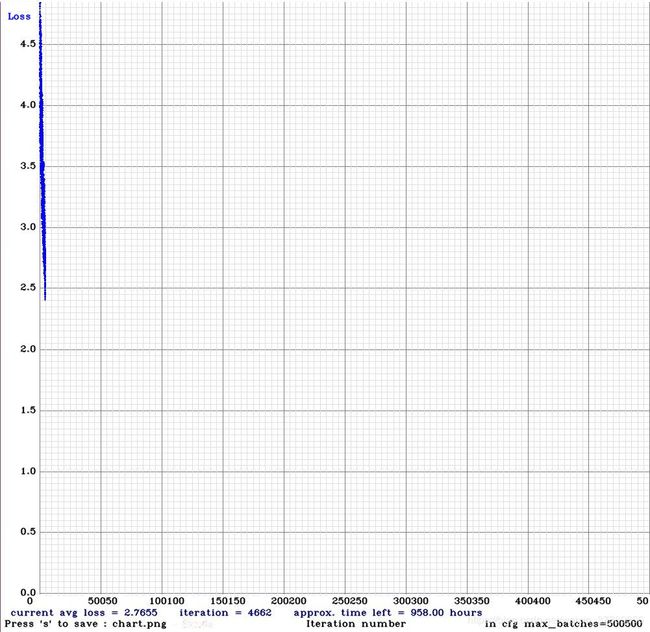
博主是从头开始训练的,可以看出训练速度非常快,4000多个batch时loss已经降到2.7了!
4.效果测试
./darknet detect cfg/yolov4.cfg yolov4.weights data/bus.jpg
效果还是很不错的!
总之,整个过程还是非常简单的,如果同学们有自己的数据集,可以大胆尝试一下!