人工智能新技术——联邦学习的前世今生(中)
联邦学习的前世今生(中)
- 导读
- 联邦学习的应用前景
- 应用部署难点和趋势
- 联邦学习技术实施方法
- 结语
导读
上篇内容回顾:
在《人工智能新技术:联邦学习的前世今生(上)》中,我们与大家一起揭开了联邦学习的神秘面纱,探索了联邦学习成为解决隐私数据保护和数据共享矛盾的关键技术背后的原因。
本篇为您解读:
- 联邦学习的应用前景
- 联邦学习应用部署难点和趋势
- 联邦学习的具体实施方法
联邦学习的应用前景
广播、电视、互联网的相继出现,时空距离骤然缩短,世界紧缩成一个“地球村”,“连接”促成了生产效率的提升和社会经济的发展。例如,古有丝绸之路促进了中西方的经济文化交流,海上航线促进工业革命成果的传播和发展(19世纪前后),今有超过50亿用户的互联网推动着知识传播、技术进步和人机协作。联邦学习也是一种“连接”工具,用于连接联邦成员的大数据资产,具有非常广泛的应用价值。
医学研究需要这样的连接工具,这是因为医学研究往往需要大量的案例分析才能发现相关性和因果规律。例如笔者曾经研究的药物副作用挖掘项目,旨在发现在临床试验中未暴露的药物的副作用。一方面,该项目使用了一百万患者持续六年的就诊记录,但只能发现少量常用药物的副作用,对于那些不常用的药物,这个量级的数据还远远不够;另一方面,就诊记录属于患者隐私,医疗机构之间无法实现数据共享,这种医疗机构的“数据孤岛”阻碍了药物副作用的发现,这在事实上损害了患者的权益。
联邦学习有望在不泄露患者隐私的前提下,利用各个医疗机构的数据,加快发现药物副作用,从而减少对患者的损害。此外,医学影像标记与诊断、罕见疾病治疗、过敏源分析等,均有可能通过联邦学习获得更多的数据、找到更多的相关性,从而提高医学研究水平和疾病治疗效果。
移动互联网也需要这样的连接工具,因为用户往往希望APP能够提供更便捷的服务。例如,在使用搜索引擎时,我们希望一次找到“最佳匹配”的网站,希望在购买商品时得到“最合适”的推荐,在网上聊天时快速输入“热门”词汇,在浏览信息时获得“最需要”的新闻和视频,希望在换工作时能找到“最默契”的团队和职位。这种“懂你”的贴心服务往往需要利用多个方面的数据,包括社交、娱乐、消费、出行等,而这些数据属于用户隐私,存储于不同的用户终端或者企业。联邦学习能够在不泄露用户隐私的前提下,连接不同企业的数据,为用户提供更贴心的服务。
金融是联邦学习实现产业落地的重要场景,因为金融对大数据技术和创新需求非常大,占大数据市场规模的10%以上。由于基于信用卡的消费信贷模式单一,银行无法满足消费者和小微企业多样化的金融信贷需求。为了接近和理解用户,大型银行可以通过自建并运营移动互联网APP,提供购物、缴费、理财等生活服务,然后根据用户数据的规律不断迭代,提高综合服务水平。
然而,移动互联网APP的建立和运营需要大量的投资和快速的迭代,这对中小银行来说是一个挑战。与传统银行机构依据收支流水授信的方式不同,联邦学习能够综合利用银行收支流水和互联网大数据更好地分析用户“还款意愿”和“还款能力”,有效识别信誉不佳的用户,从而降低信贷坏账造成的成本,从而为更多的优质用户提供低息贷款,促进民众消费升级和小微企业的发展,实践国家号召的普惠金融。
目前,多家大型金融企业正在展开联邦学习技术的战略布局和应用,推出了具有行业影响力的行业解决方案和项目。例如,已有联邦学习开源项目吸引了大量开发者和应用者,在保险科技、信贷风控等场景下得到初步验证。这进一步加速了联邦学习的技术迭代和落地。
此外,从业务形态的角度来看,联邦学习的基础在于组建联邦,只有联邦的数据足够互补和完整才能形成规模效应,赢得市场竞争。联邦的关键在于信任,一方面,这依托于联邦学习技术本身的安全性,隐私数据不可能被恶意联邦成员破解;另一方面,这需要参与方有开放合作的态度,能够不断地宣传推广联邦学习技术以及业务价值,以便更多的人能理解和使用这项技术。就像区块链一样,用的人越多,价值就越大。如果这项技术能够得到参与者的积极宣传,“众人拾柴火焰高”将使得这项技术得以迅速推广。
应用部署难点和趋势
目前尚未出现大规模联邦学习商业化应用,原因在于以下几个方面的难点。
-
**网络带宽不足,用户终端或者企业之间的现有网络带宽难以满足联邦学习的需要。**这是因为联邦学习需要非常大量的中间结果交互,在某些场景下需要超过100Mb/s的网络带宽才能在有效的时间内完成建模。例如,我们在与客户沟通时发现,某些银行仅支持2Mb/s的网络带宽,在样本量较大的情况下,这可能导致建模时间长达数月,无法满足业务的需求。不过我们认为,随着5G技术的发展和信息高速公路的建设,网络带宽问题将会很快解决。
-
**政府和行业协会尚未发布正式的标准和法规,企业和金融机构对新技术存在顾虑。**正在立项过程中的联邦学习标准包括IEEE 3652.1, IEEE P2830,待其正式发布后将具有全球公认权威性。此外,京东等企业也在积极参与和推动中国的联邦学习相关的国家标准立项。随着技术标准的完善和实施,企业和金融机构不再有顾虑,联邦学习将如同RSA非对称加密等新技术的应用一样无处不在。
-
**技术门槛较高。虽然市面上已有联邦学习商业解决方案和开源项目,但其稳定性和准确性方面还存在不少异常问题和挑战,需要频繁的更新迭代。**常见的移动互联网服务是面向C端消费者的,以企业自身的快速迭代为特征,因此对错误的容忍性较高。然而联邦学习需涉及多个企业,对应的解决方案需面向B端企业,并且需要企业间生成集群和研发人员进行配合,这使得联邦学习合作对异常问题的容忍度非常低。此外,企业需要投入较多的人力资源对联邦学习进行安全性审核、部署、调试和优化,这导致中小企业不能快速使用联邦学习。针对这个问题,包括京东在内的大型企业在投入大量资源研发简单易用的商业解决方案,技术门槛正在逐步降低。
-
**商业模式待探索。联邦学习能够解决数据孤岛问题并提升服务质量,进而产生社会价值和业务利润。**然而,联邦学习仍处于探索中,还没有可供参考的大规模商业应用,如何评估各个成员对联邦的贡献、如何进行利润分配仍然是个开放的问题,需要联邦成员进行探索和协商。这一点将在互联网大数据业务需求的驱动下逐渐明朗。
综上所述,联邦学习当前仍面临很多难点,但是在巨大的应用前景的驱动下,正在快速化解。我们认为,联邦学习将利用互联网大数据浪潮,在不泄露用户隐私的前提下,为广大用户带来更优质的服务。
联邦学习技术实施方法
为了同时满足隐私保护和模型训练的需求,联邦学习具体是如何实施呢?
回顾联邦学习的概念,它是一种隐私保护的分布式机器学习。根据分布形式的不同,联邦学习可分为两种常见的应用类型:横向联邦学习和纵向联邦学习。横向联邦学习是指当样本分布在不同位置时,通过约束各个位置使用相同特征,分别建立同质模型并进行融合的建模方式;纵向联邦学习是指当特征分布在不同位置时,通过约束各个位置使用相同的样本,从而实现多个视角联合建模的方式。
例如,典型的纵向联邦学习技术的实施方法如下图所示。
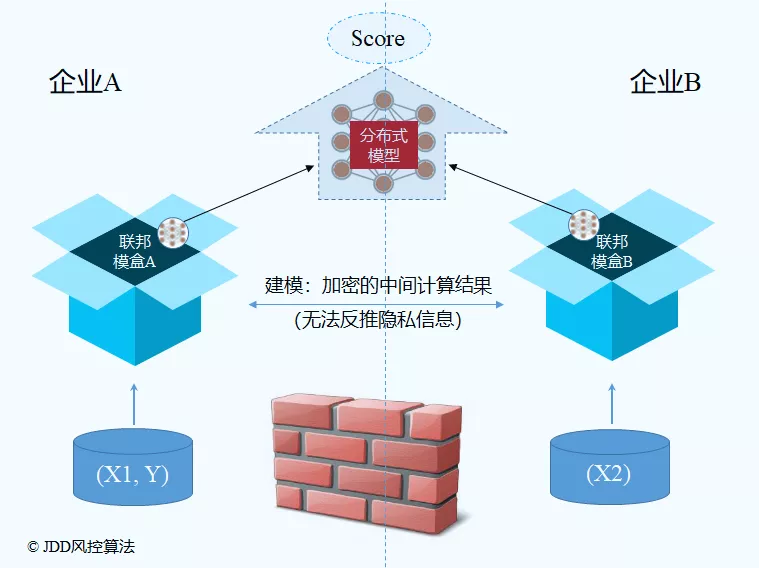
这个联邦包括两个成员:企业A(左侧)和企业B(右侧)。从下往上看,对于每个共有用户,企业A提供某个视角的特征X1和标签Y,企业B提供补充视角的特征X2。为了利用双方特征建立模型,传统机器学习要求将双方将每个用户的特征拼接为(X1, X2, Y),但是这种方法能够见到对方用户的具体特征,从而造成用户隐私信息泄露。与传统机器学习不同,纵向联邦学习分别在企业A和企业B部署两个容器(此处简称为联邦模盒),双方分别将数据存放于联邦模盒之中,如上图中部所示。
在训练阶段,由包含标签Y的一方发起模型训练请求,通过基于同态加密中间计算结果的梯度下降算法实现建模。值得注意的是,这里传输的并非原始隐私信息,而是经过加权计算的中间结果,并使用同态加密技术进行双重保护,因此具有非常好的安全性。建模产生的模型被分布式地存储在两个联邦模盒之中,其中与企业A的特征相关的部分模型存储于联邦模盒A中,与企业B的特征相关的部分模型存储于联邦模盒B中。
在推理阶段(上图的上部所示),由包含标签Y的一方发起打分请求,双方依据各自的特征和部分模型计算某种形式的中间状态,并在企业A汇总形成最终得分。尽管模型分布式地存储在不同位置,但从结果上看,这与整合模型打分的准确性是一致的。同时由于打分过程中看不到对方的原始隐私信息,因此推理阶段也是安全的。
参考文献
[1] Andrew Hard et., al. Federated Learning for Mobile Keyboard Prediction, https://arxiv.org/abs/1811.03604
[2] Qiang Yang et., al. Federated Machine Learning: Concept and Applications. ACM TIST2019. https://arxiv.org/abs/1902.04885
[3] Federated Learning: Collaborative Machine Learning without Centralized Training. https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[4] Kewei Cheng, Qiang Yang et., al. SecureBoost: A Lossless Federated Learning Framework. https://arxiv.org/abs/1901.08755
[5] 刘洋, 范涛. 联邦学习的研究与应用. https://img.fedai.org.cn/fedweb/1553845987342.pdf
[6] Tian Li et., al. Federated Learning: Challenges, Methods, and Future Directions. https://arxiv.org/abs/1908.07873
[7] 飞向未来的埃舍尔. 联邦学习/联盟学习的发展现状及前景如何?https://www.zhihu.com/question/329518273/answer/717840293
结语
如果说大数据是互联网时代的燃料,那么联邦学习就是互联网时代的多缸发动机,促进互联网应用提供更优质的服务。本篇主要介绍了联邦学习前景、难点和实施方式。下篇将围绕隐私保护的算法原理进行更详细的介绍。关于联邦学习的应用场景,你又有什么看法呢?欢迎在评论区里给小编留言。
未完待续,敬请关注。点击链接阅读原文
想要获取更多资讯,请扫码关注 JDD风控算法。
