Flink原理,实战与性能优化读书笔记(一)
面试官如果问道,为什么使用Flink?
1.Flink 使用有状态流式计算模型实现了高吞吐,低延迟,高性能兼具实时流式计算框架。
什么是有状态计算?
流式计算中算子的中间结果数据保存在内存或者文件系统当中,等下一个事件进入算子的时候,可以从之前的状态中获取中间结果来计算当前结果。从而无须每次都基于全部的原始数据来统计结果。这种方法降低了数据计算过程中的资源消耗。
也就是能够直接在数据产生的过程中进行计算并且产生统计结果。简而言之,无须通过调度和协调各种批量计算工具,从数据仓库中获取数据统计结果,然后再落地存储,这些操作全部都可以基于流式计算完成,可以极大地减轻系统对其他框架的依赖,减少数据计算过程中的时间损耗以及硬件存储。

2.分布式快照技术checkpoints
支持高度容错的状态管理,防止状态在计算过程中因为系统异常发生丢失。核心是使用分布式快照技术checkpoints实现状态的持久化维护,将执行过程中的状态信息进行持久化存储,一旦任务出现停止,flink就能够从checkpoints进行的任务的自动恢复。
3.支持事件时间(Event-TIme)概念
多数框架窗口计算采用的都是系统时间(Process Time),也是事件传输到计算框架处理时,系统主机的当前时间。Flink能够支持基于事件时间(Event Time)语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
4.window操作很灵活。
流处理应用中,窗口的作用是对流数据进行一定范围的聚合计算。
例如统计在过去的1分钟内有多少用户点击某一网页,在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行再计算
,用户可以定义不同的窗口触发机制来满足不同的需求。
5.基于JVM实现独立的内存管理。
计算框架一般都要考虑内存管理机制。
flink实现了自身管理内存机制,尽可能减少JVM GC对系统的影响。另外,flink通过序列化/反序列化方法把数据对象转换为二进制在内存管理。降低了数据存储大小,降低GC带来的性能下降或任务异常风险。
6.存储介质上的save points
对于7*24小时运行的流式应用,数据源源不断地接入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确,例如进行集群版本的升级、停机运维操作等操作。值得一提的是,Flink通过Save Points技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的Save Points恢复原有的计算状态,使得任务继续按照停机之前的状态运行,Save Points技术可以让用户更好地管理和运维实时流式应用
应用场景
推荐系统,智能推荐
复杂事件处理
实时欺诈检测
实时数据仓库与ETL
流数据分析
实时报表分析
Flink基本架构
分层架构设计理念。
分为三层:
API&Libraries
作为分布式数据处理框架,Flink同时提供了支撑流计算和批计算的接口,同时在此基础之上抽象出不同的应用类型的组件库,如基于流处理的CEP(复杂事件处理库)、SQL&Table库和基于批处理的FlinkML(机器学习库)等、Gelly(图处理库)等。API层包括构建流计算应用的DataStream API和批计算应用的DataSet API,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,同时也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据。
Runtime核心层
支持stream作业的执行,jobGraph到ExecutionGraph的映射转换与任务调度。
把dataStream(流处理)与dataSet (批处理)转换成统一的可以执行的task operator
物理部署层
涉及到
本地/集群
云
Kubenetes
基本架构
Flink架构遵循Master-slave架构
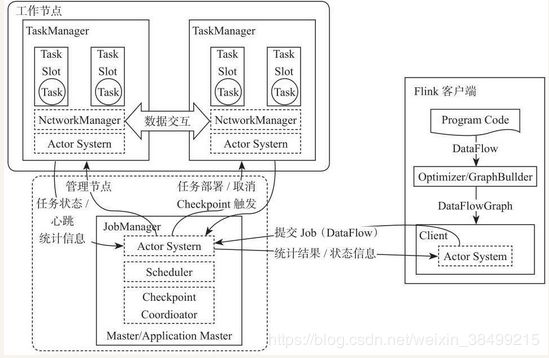
flink整个系统由两个部分组成:
JobManager 为master节点 与 TaskManager 为slave节点
所有组件的通信都是借助于Akka FrameWork.
Flink编程模型
数据集类型
- 有界数据集
处理方式是批计算。把数据从RDBMS或者文件系统等系统中读取出来,然后在分布式系统内处理,最后再将处理结果写入存储介质中,整个过程被称为批处理过程。
 * 无界数据集
* 无界数据集
处理方式是流式数据处理
需要考虑处理过程中数据的顺序错乱,系统容错问题。
程序结构:
package com.realtime.flink.streaming
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecution
Environment, _}
object WordCount {
def main(args: Array[String]) {
// 第一步:设定执行环境设定
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 第二步:指定数据源地址, 读取输入数据
val text = env.readTextFile("file:///path/file")
// 第三步:对数据集指定转换操作逻辑
val counts: DataStream[(String, Int)] = text
.flatMap(_.toLowerCase.split(" "))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
// 第四步:指定计算结果输出位置
if (params.has("output")) {
counts.writeAsText(params.get("output"))
} else {
println("Printing result to stdout. Use --output to specify output path.")
counts.print()
}
// 第五步:指定名称并触发流式任务
env.execute("Streaming WordCount")
}
}
基本上有五个步骤:
1.Execution Environment
获得相应的执行环境。执行环境决定了程序运行的环境。
StreamExecutionEnvironment用来做流式数据处理
ExecutionEnvironment 批量数据处理环境
//设定Flink运行环境, 如果在本地启动则创建本地环境, 如果是在集群上启动, 则创建集群环境
StreamExecutionEnvironment.getExecutionEnvironment
//指定并行度创建本地执行环境
StreamExecutionEnvironment.createLocalEnvironment(5)
//指定远程JobManagerIP和RPC端口以及运行程序所在jar包及其依赖包
StreamExecutionEnvironment.createRemoteEnvironment("JobManagerHost",6021,5,"/user/application.jar")
2.初始化数据
通过读取文件并转换为DataStream[String]数据集,这样就完成了从本地文件到分布式数据集的转换,同时在Flink中提供了多种从外部读取数据的连接器,包括批量和实时的数据连接器,能够将Flink系统和其他第三方系统连接,直接获取外部数据。
3.转换操作
算子内传入Lambda表达式即可
或者自定义函数接口
dataStream.map(new MymapFunction)
class MymapFunction extends MapFunction[String, String] {
override def map(t: String): String = {
t.toUpperCase()
}
}
dataStream.map(new MapFunction[String, String] {
override def map(t: String): String = {
t.toUpperCase()
}
})
两种定义Function的方法
一种是创建class实现,另外一个是创建匿名类实现
4.分区Key指定
-
根据字段位置指定
把dataStream或者dataset数据集转换成相对应的KeyedStream与GroupedDataset -
按照字段名称指定
-
通过Key选择器指定
定义key selector,然后override getKey方法
case class Person(name: String, age: Int)
val person= env.fromElements(Person("hello",1), Person("flink",4))
//定义KeySelector,实现getKey方法从case class中获取Key
val keyed: KeyedStream[WC]= person.keyBy(new KeySelector[Person, String]() {
override def getKey(person: Person): String = person.word
})
1.writeasText() 基于文件输出
2.控制台输出print()
3.addSInk()自定义算子
dataStream最后要显式声明execute
dataset则不用
一些API 应用
这里直接介绍一些不常见得,像filter,map,flatMap,就不说了
- connect 只能够链接两条流,两条的数据类型可以不同
- coMap,coFlatMap
package DataStream;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import javax.xml.crypto.Data;
public class unionDemo {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource text1 = env.addSource(new MyNoParalleSource()).setParallelism(1);//注意:针对此source,并行度只能设置为1
DataStreamSource text2 = env.addSource(new MyNoParalleSource()).setParallelism(1);
SingleOutputStreamOperator text2_str = text2.map(new MapFunction() {
@Override
public String map(Long aLong) throws Exception {
return "str_"+aLong;
}
});
//只能够链接2条流,但是能够分别对两条流作处理
ConnectedStreams coStream = text1.connect(text2_str);
SingleOutputStreamOperator - split: 一个数据流切分为多个流
- select: 和split配合使用
package DataStream;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
public class splitDemo {
public static void main(String [] args)throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource text = env.addSource(new MyNoParalleSource());
//划分奇偶两条流
SplitStream splitStream = text.split(new OutputSelector() {
@Override
public Iterable select(Long aLong) {
ArrayList list = new ArrayList<>();
if(aLong%2==0){
list.add("even");
}else{
list.add("odd");
}
return list;
}
});
DataStream evenSource = splitStream.select("even");
DataStream oddSource = splitStream.select("odd");
DataStream moreStream = splitStream.select("even","odd");
oddSource.print().setParallelism(1);
String jobName = splitDemo.class.getSimpleName();
env.execute(jobName);
}
}
Flink数据类型
数据类型管理机制:TypeInformation
数据类型的描述信息由TypeInformation定义。
主要作用是为了在flink系统内有效地对数据结构类型进行管理。能够在数据处理之前就把数据类型推断出来。
当使用scala API的时候,需要先引入
import org.apache.flink.api.scala._
把TypeInformation类隐式参数引入当前程序环境。
摘自:《Flink原理、实战与性能优化》 — 张利兵
在豆瓣阅读书店查看:https://read.douban.com/ebook/114289022/
本作品由华章数媒授权豆瓣阅读全球范围内电子版制作与发行。
© 版权所有,侵权必究。