数据分析师必知的那些Hive-SQL

作者:宝器
来源:数据管道
大家好,我是宝器。
昨天了那篇文章「对不起,让大家失望了」之后,收到了写文章以来最多的私信和赞赏,感谢大家鼓励。
至于赞赏这个东西,了解的应该知道,我极少开,支持一个头像就可以了,真的不需要金额过大。相对于赞赏,我更希望看到大家认真对宝器的建议。
文末放了一个可以跟宝器留言互动的链接,目的是想更好的定位要推送更新的内容,从留言板和私信看很多旁友对求职实用性的内容需求更大,摘取部分读者的留言和私信:
看的出来,这些读者都很用心看过我的内容。所以按照需求,今天立马安排上。
关于数据分析岗位,首先是数据,然后才是分析,那怎么取数是基础且非常重要的一步。这里的获取数据不是指用爬虫爬取一些如评论、点赞的数据来分析。
为什么
你想如果你就职于淘宝,现在老板需要你看一下最近的活跃用户,了解一下新用户的访客特征。
怎么做
第一步当然是在公司的数据仓库获取数据,这些数据依赖哪些表,表的关系,为什么创建这张表,你是需要知道的,因为表肯定是为业务需求所设计。而分析也是为了更好的业务增长,这样才能形成一个完整的闭环。
我的观点是,以分析促进业务增长,以业务增长培养更好的分析思维、分析角度、分析高度,其一是为公司获取利益,其二是提升自己。
关于数据仓库的数据是怎么来的,可能你还要花时间了解一下关于数据埋点,这里不做过多介绍,重点讲如何取数、为什么会有Hive-SQL的概念。
那首先介绍一下为什么需要Hive这样的工具,可以思考一个问题,如果现在你使用的表是淘宝当月的月活表,我想这里面的数据量肯定是亿级别的,这面临的是大规模数据处理的问题,如果用传统的方法,可能你做个最简单的查询都需要一两天。
这当然不现实
通俗的理解Hive是一个基于Hadoop的开源的数据仓库工具,用于存(HDFS)和处理(MapReduce)海量结构化数据。使用MapReduce计算,HDFS储存。
关于HDFS、MapReduce是啥,不重要,可以理解为一个用于分布式计算,一个用于存储数据的分布式文件系统就行。
那这跟SQL又有什么关系
因为SQL简单的语法就可以帮我们进行复杂统计分析之类的活,而Hive相当于提供一层转化,让传统的数据人员不需要了解复杂MapReduce分布式计算的编写,就可以通过SQL解决大数据的计算问题,降低难度。
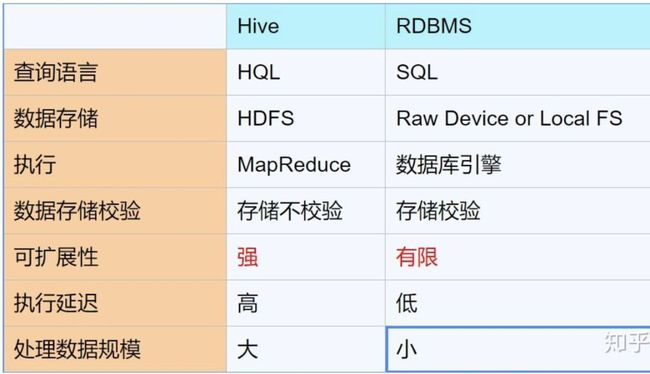
Hive和传统数据库的区别可以直接看下图。
好像听上去也很复杂?那这些都需要知道吗?
其实不用,关于Hive的设计、怎么优化性能这些是数据开发的小伙伴所需要关心的问题,分析师的话,实际上了解一下原理就可以了。
授人以鱼不如授人以渔,如果现在我直接把《Hive编程指南》的知识点复现一遍,肯定会让大家还是觉得知识太多了。
所以这部分我画了2张思维导图,注释了哪些部分的知识点了解一下就可以了,哪些需要熟练掌握甚至精通的,这样的话会节省很多时间去阅读更重要的内容,更好的应对DA岗的面试和工作。
01
需要简单了解的
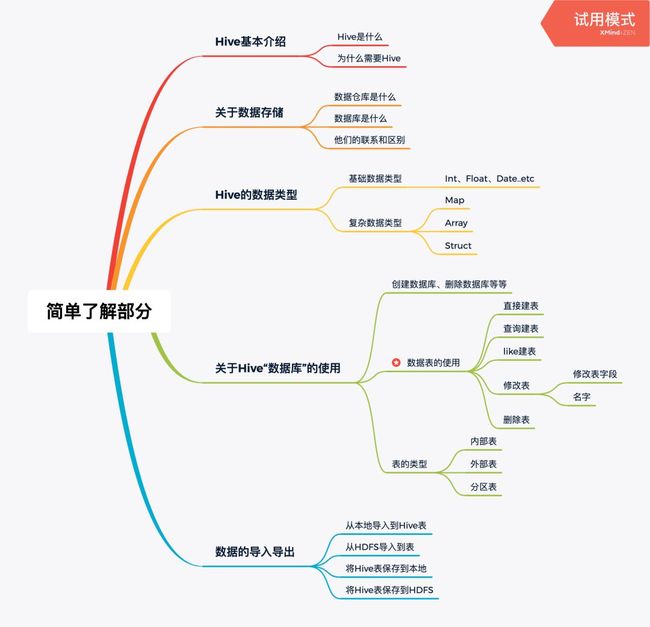
其中星标部分需要熟练
02
需要重点掌握的
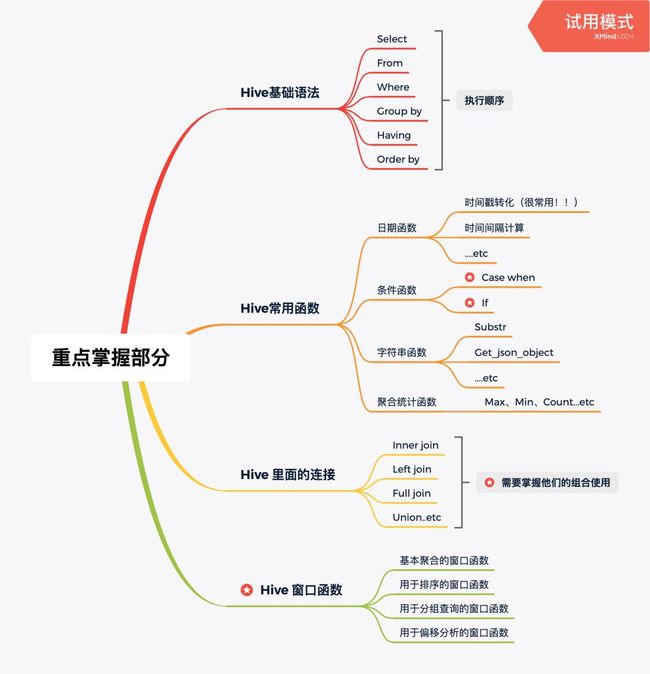
其中星标部分需要精通

◆ ◆ ◆ ◆ ◆

长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:

猜你喜欢
● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!
● 全球股市跳水大战,谁最坑爹!
● 上万条数据撕开微博热搜的真相!
● 你相信逛B站也能学编程吗