测试Istio 1.6 Service Mesh引入虚拟机Workload (笔记与感悟)
序:
五月底Istio官方发布了1.6的正式版, 简化了部署以及对其组件进行了整合. 引起我注意的是Istio正式增强了对非容器形态加入网格的支持, 并声明会做为重要的战略持续优化. 做为VMwarer对这次更新有种被照顾到了的欣喜. 一方面VMware以All in的姿态投身于Kubernetes业态, 另一方面如Istio, AWS App Mseh, Kong Kuma等一众服务网格产品都在向VM / BM延伸. 各大服务网格在布道过程中都遇到了传统服务向网格迁移的障碍, 而巨大的VM业务形态的存量市场也不是现在的服务网格能短时间内撼动的.
与其说是一种妥协, 我认为这是一种更务实的态度, 采用Universal的框架, 降低使用门槛, 才能使得推广服务网格的路更加宽广. 毕竟那些未曾使用服务网格的用户并不非不知道服务网格的益处.
想详细了解Istio 1.6的更新可以在官网Release中查看:
https://istio.io/news/releases/1.6.x/announcing-1.6/
如果想看业内人士关于本次更新的见解, 推荐两篇博文:
《Istio v1.6深度解读》
《Istio 1.6——迈向极简主义》
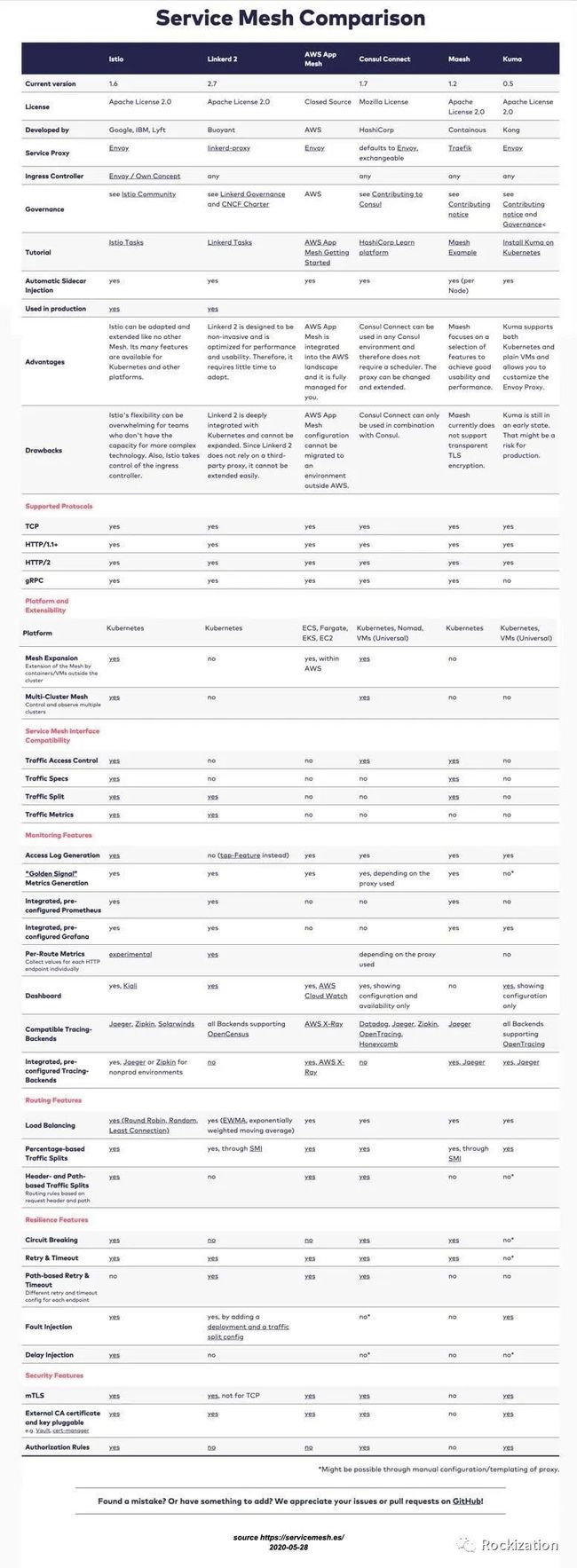
另外引用一张关注度较高的几个服务网格产品的对比,仅供参考:
本文讲什么:
使用Istio 1.6构建服务网格引入虚拟机(VM)时的注意事项.
梳理和记录一下Istio流量控制的逻辑.
测试完后的思考与感悟.
测试目标
使用Istio 1.6 新的安装方法, 启用服务网格对VM的支持.
部署Bookinfo Demo, 使用流量策略使得该Demo中的评分服务(Rating)调用VM中的DB.
进阶Demo, 使用流量策略使得用户名为Jason的用户浏览的是特定版本的评分服务, 其余用户评分服务数据来自VM-DB.
梳理和图示Istio流量策略逻辑关系.
测试环境
测试拓扑:
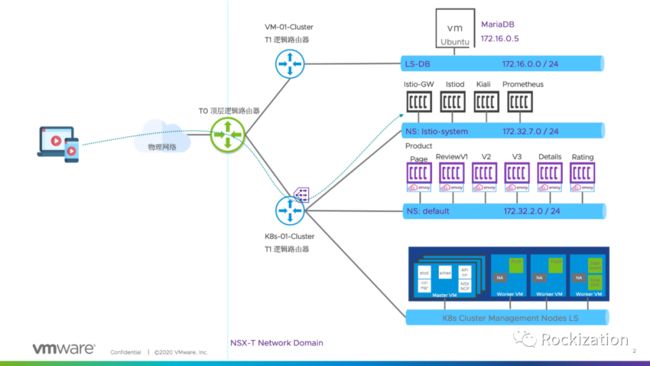
采用VMware NSX-T构建容器与虚拟机的网络. 采用叠层(Overlay)网络构建模式, 每个K8s集群共享一个租户路由器(T1), K8s集群内每个Namespace获取独立24位的子网, 子网基于Namespace的注释可选路由模式和SNAT模式. 如图所示, Bookinfo部署在Default Namespace, Istio组件部署在Istio-system Namespace. 子网分别为172.32.2.0/24和172.32.7.0/24.
虚拟机没有与K8s集群共享T1路由器, 部署在172.16.0.0/24子网中, 安装了MariaDB. 注意: Istio在非容器的安装包中只提供了.deb的版本, 本次测试使用Ubuntu 18.04.
NSX-T 内置LB为Istio Gateway提供对外可路由的VIP. Istio Gateway默认使用Service Type LB进行暴露, 如果没有NSX-T环境的朋友可以部署个Metallb或者采用Nodeport方式暴露. 官方文档特别提到VM网络要可路由到容器网络, 恰好这正是NSX-T所擅长的. 采用其他CNI的朋友就要自行想办法打通路由咯, CNI众多这里就不再给建议了.
环境部署
本文的重点不是讲Istio的安装, 官方文档有详细的说明. 可以参考该链接:
https://istio.io/docs/setup/install/virtual-machine/.
初始化安装时需要开启meshExpansion, 在官文中有说明. 同时我开启了Kiali为后续做流量视图做准备.
istioctl install --set addonComponents.kiali.enabled=true --set values.global.meshExpansion.enabled=true
稍等片刻, Istio的组件就部署到了Istio-system这个Namespace中了. 默认Istio采用的是Default的模版, 如果想把其他附加组件一并测试的话,初始化时可以改用Demo模版, 命令如下.
istioctl install --set profile=demo --set values.global.meshExpansion.enabled=true
其余步骤完全参考官方文档即可, 包括在VM中安装Istio和部署Bookinfo Demo. 可以多做一步检测, 确保VM能够Ping通Pod IP. 因为使用的是NSX-T构建的网络, 我使用了平台内置的追踪工具, 确保目标容器到达VM未来要部署MariaDB的端口3306的通达性.
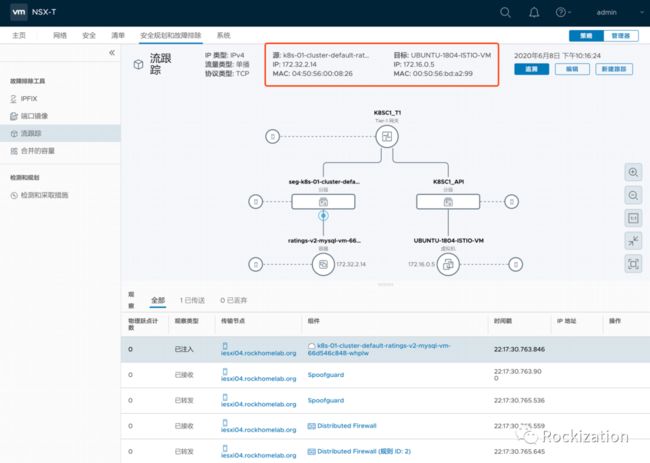
关键步骤
Rating Pod
部署评分(Rating)功能的容器时, 官方范例Yaml给出的是让Rating找注册在VM Namespace的虚拟机, 但如果你的虚拟机在注册服务时并不在VM Namespace的话要注意修改Rating Yaml参数后再部署. 举例我是将虚拟机注册在Default Namespace里, 所以注意这一项改成value: mysqldb.default.svc.cluster.local.
cat <Istio服务注入
使用Istioctl命令向K8s目标Namespace中注入一条服务条目. 注入时也许你得不到官方文档一样的命令行提示, 但不用紧张因为没有影响.
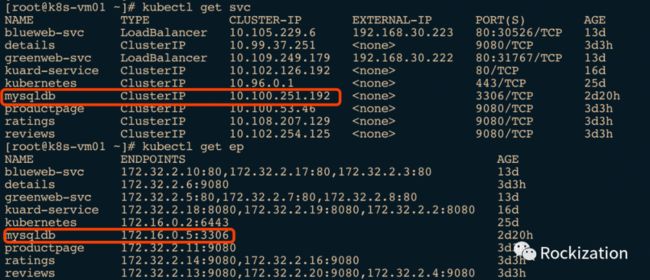
istioctl register -n default mysqldb 172.16.0.5 3306
注入完后, 可以用Kubectl确认一下:
接下来官方文档就剩下调用预制策略:virtual-service-ratings-mysql-vm.yaml. 该策略就是让Review V3调用Rating v2-mysql-vm, 然后Rating v2-mysql-vm根据之前Deployment里的参数去查询虚拟机中的MariaDB. 官方原文是这样的:

如果一切顺利的话, 通过浏览器应该看到的是红色的评分,分别是1星和4星. 做到这我心想, 这很简单嘛, 步骤很少嘛, Istio真厚道, 做得简单易用, 文档又够详尽. 然后我错了, 打开浏览器发现是这样的:
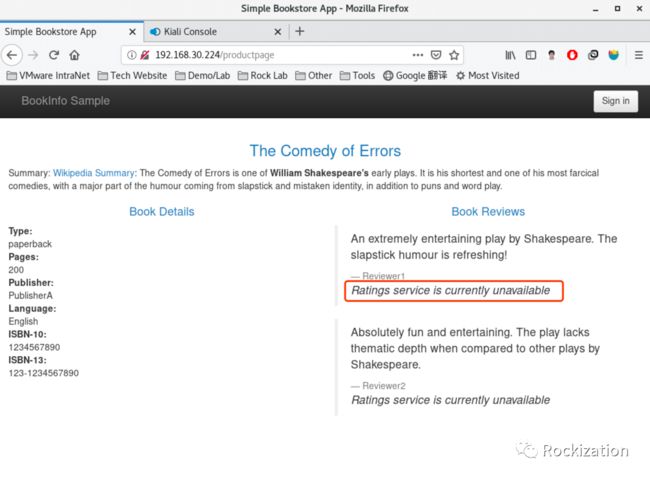
评分服务不可用?!!
排错
因为刚刚开始学习Istio, 心想一定是我哪一步没有做对, 这么详细的文档, 还有中文的, 嗯, 一定是我的不对. 这一排错就是一周过去了, 发现官方论坛里还没有人做这个测试, 油管上的视频也比较老版本的范例. 做不出效果, 沮丧得想放弃. 一度想归结为可能是新版本的Bug, 想先放放在说. 可前辈们的博文上明明写着Istio在1.6上做减法,并加强对虚拟机入网的支持啊, 不可能连这么简单的QE都不做就发布了吧.
不甘心, 做梦都在排错. 决心再整理一下思路, 不用这种捷径的方式做Demo. 大致过程如下:
在VM侧抓包, 发现确实有原地址来自Rating Pod IP访问3306, 没有明显的TCP Reject, 但获取不到数据.
在VM中使用Node_Agent命令向Istiod发起注册, 发现Node_Agent默认去找Citadel服务, 证书无法被签名.
搜索相关Node_Agent的问题, 查找Github有无类似的Issues, 无果.
对比中英文文档寻找步骤差异, 无果
才做了测试没几天, Istio竟然发布1.6.1了, 咋一看Fix了一页的Bug. 我心想八成把我现在遇到的问题给Fix了吧. 无果.
正式阅读Istio 1.6 Release Note, 发现在1.6版本中正式针对虚拟机/物理机引入了新的对象类型:WorkloadEntry
通读WorkloadEntry设计目标以及用法, 发现WorkloadEntry需要与ServiceEntry嵌套使用.
在测试环境中增补了WorkloadEntry和ServiceEntry的配置, 无果.
再阅读ServiceEntry的设计目标和用法, 发现其需要嵌套Destination Rule使用.
配置正确的Destination Rule后实验达到预期效果, 泪目.
与友人探讨, 整理逻辑, 完善测试场景. 喜悦.
Istio流量控制模型
通过这次的测试与排错, 加上与友人的探讨, 对Istio流量控制模型有了一种“多么痛的领悟”. 使用图示总结出来供大家参考, 当然若有写得不对的, 还请看官不吝指正.
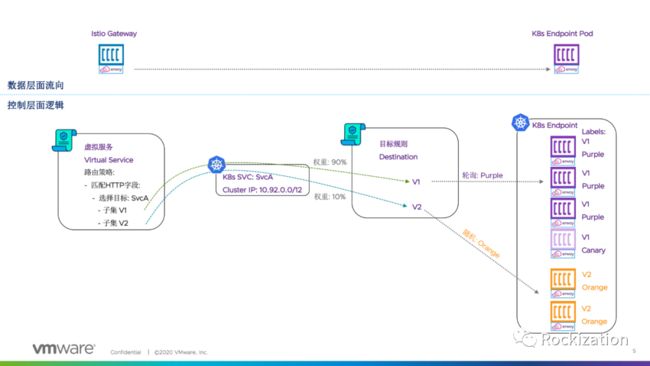
图示中没有包含Gateway以及网络弹性与测试部分, 有兴趣可以查阅:
https://istio.io/docs/concepts/traffic-management/.
流连管理模型贯彻了K8s一切皆对象的概念. 虚拟服务(VirtualService)将K8s 的SVC拆分成若干个子集, 通过配置匹配HTTP报文或gRPC报文指定子集路径, 多个子集时可以采用蓝绿发布或金丝雀发布(基于权重).
逻辑到达目标子集后, 目标规则(Destination Rule)可以更下一层逻辑, 控制子集内的负载均衡方式, 为相同子集内的Endpoint(Pod or VM)做滚动升级, 蓝绿, 金丝雀留下可控方式. 服务网络要做到对业务代码不入侵, 采用了Sidecar的模式旁挂, 服务发现与策略匹配全靠Endpoint标签的设计. 但服务网格要做到超出HTTP以外的报文匹配 / 遥测 / 注入, 则需要改造或拓展Sidecar功能, 典型案例如蚂蚁金服的MOSN支持阿里的Dubbo RPC框架. 但这除了需要专业的团队对冲技术债务以外, 更重要的是企业整体开发团队改造决心与认可. 当然了Google当然是希望你直接用gRPC就好了.
1.6 引入WorkloadEntry的流控模型
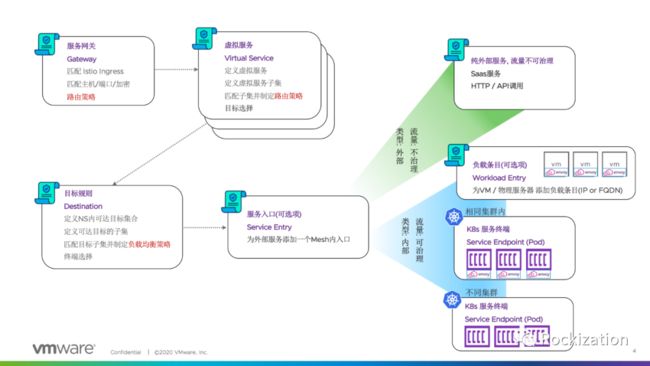
在Destination Rule下层对象调用ServiceEntry, ServiceEntry可将一个服务子集通过标签的匹配同时指向Pod和定义了VM Endpoint的WorkloadEntry. 上图如果觉得不够好理解可以看看官方的拆解示图:
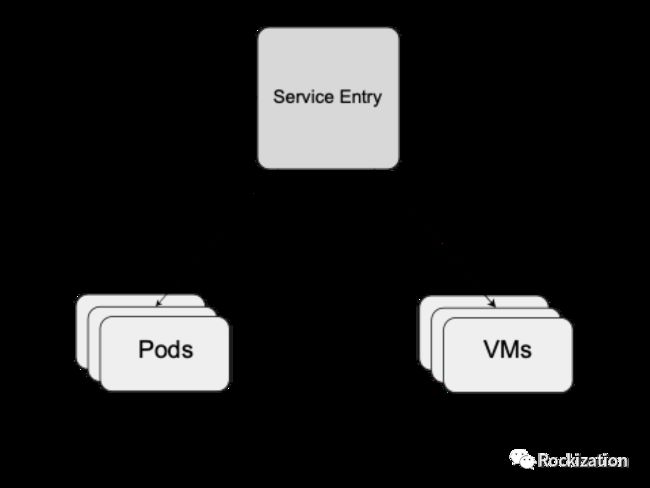
通过在Destination Rule后面再加一层对象的方法, 就可以实现一个子集服务同时由Pod和VM来承担. 由此就可以实现VM业务向Pod形态的平滑迁移. 当然不你迁移也可以直接在VM和Pod混合形态中做蓝绿或金丝雀.上图对应的Yaml范例如下, 你细品, 是不是想到了我们未完的实验该怎么做了.
apiVersion: networking.istio.io/v1alpha3
kind: WorkloadEntry
metadata:
name: vm1
namespace: ns1
spec:
address: 1.1.1.1
labels:
app: foo
instance-id: vm-78ad2
class: vm
---
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: svc1
namespace: ns1
spec:
hosts:
- svc1.internal.com
ports:
- number: 80
name: http
protocol: HTTP
resolution: STATIC
workloadSelector:
labels:
app: foo
最终配置
前面的步骤完全参考官方文档做就可以了, 下面安顺序贴出来增补Destination Rule / ServiceEntry / WorkloadEntry
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: mtls-mysqldb-vm
spec:
host: mysqldb.default.svc.cluster.local
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: mysqldb-vm
spec:
hosts:
- mysqldb.default.svc.cluster.local
location: MESH_INTERNAL
ports:
- number: 3306
name: mysql
protocol: mysql
resolution: STATIC
workloadSelector:
labels:
app: mysqldb-vm
apiVersion: networking.istio.io/v1alpha3
kind: WorkloadEntry
metadata:
name: mysqldb-vm
spec:
address: 172.16.0.5
labels:
app: mysqldb-vm
instance-id: ubuntu-vm-mariadb
打开浏览器再次测试, 看到了Rating读取了VM数据库中test表, 将红色的评分置为1星与4星, 泪目.
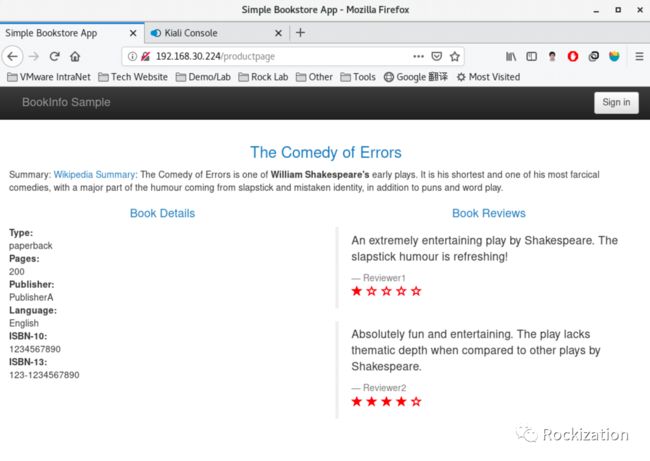
然后我们再同时结合一个匹配HTTP报文头, 识别用户为Jason时, 将其路由到Reviews V2去. 也就是Jason登陆后应该看到的是黑色的评分栏以及5星和4星的打分.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v3
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: ratings
subset: v1
- route:
- destination:
host: ratings
subset: v2-mysql-vm
测试效果:
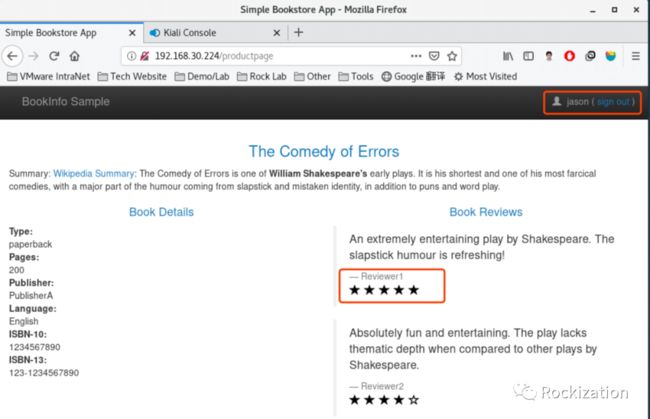
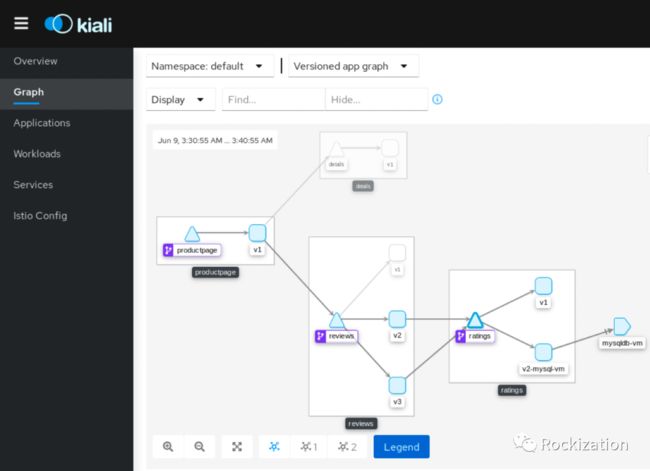
测试成功又想与人分享我的喜悦, 大晚上把正在追剧的老婆叫过来, 一顿Demo. 再结合即将到来的618, 电商如果通过服务网格给不同的买家定向推销. 平时对你购物行为, 数据画像转换成的标签有什么用.
老婆恍然大悟: “618要了! 可以囤明年的厕纸了.”
我愕然:“你就想到了个这, 再说厕纸不还有吗.”
老婆:“换个牌子试试, 蓝绿厕纸, 金丝雀用法了解一下.”
我 ...很欣慰, 也算是听懂了.
...很欣慰, 也算是听懂了.
结语与猜想
在当下这个时间节点来构建服务网格(Service Mesh), 大多组网会出现下图我们总结的场景. 层层抽象, 各层构建独立的管理层面与逻辑. 叠加在一起的数据层面, 很容易让人先想到转发开销的问题. 各层学习成本高, 易用性差, 互操作性弱. 显然不是我们所期望的, 可目前却只能如此.
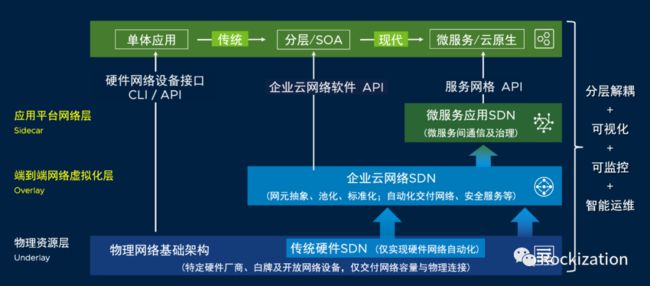
前不久读到了赵化冰先生的一篇博文《Service Mesh是下一代SDN吗?》, 博文非常值得一读, 对服务网格的定位, 借鉴SDN经验等部分都做出分析与推理. 他的结论是Service Mesh不是下一代SDN. 但本人作为常年的网络从业人员却有不同的看法. 我认为二者终将融为一体, 至于叫什么名字不敢瞎起, 但融合后会是我认为的下一代SDN(该不会就叫NGSDN吧).
我的推理取材于生态中的几个环节发展趋势, 再结合一些VMware已实现的技术在一起. 在VMware Blog中也有类似的分析与猜想, 原文:
https://blogs.vmware.com/networkvirtualization/2019/04/how-istio-nsx-service-mesh-and-nsx-data-center-fit-together.html/
其中用到一图展示了NSX-T作为SDN与Istio作为Service Mesh, 在OSI 7层模型的功能交叠.
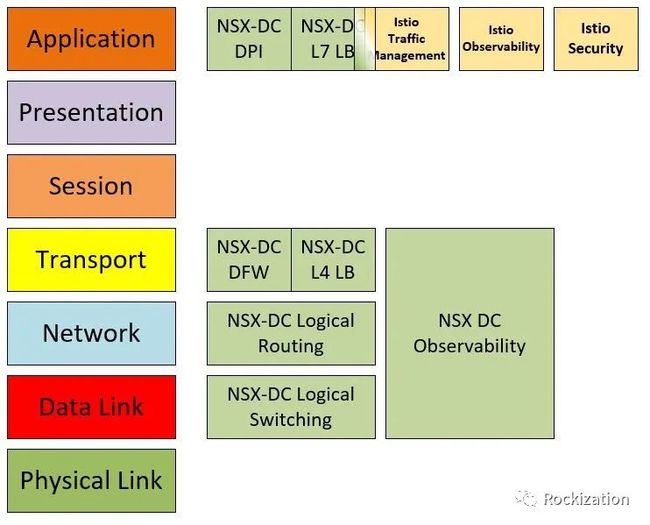
就上图来看的似乎就是大家各司其职, 各有所长, 相互借鉴一下经验教训就好了. 但这样做还是无法根本上解决上一段我提到的多层构建管理平面, 数据平面交叠的问题. 它所带来的技术债务就劝退了很多尝试者. 但如果我们从与网络相关的其他技术来看, 也许会有新的想法, 比如微型虚拟机的容器运行时(PodVM)和智能网卡(SmartNIC). 结合这几项技术的发展我们大胆推测一下这个架构:
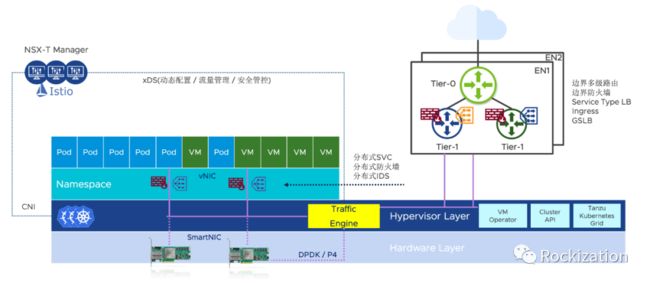
现在微型虚拟机, PodVM目前发展趋势迅猛, 很多大厂都积极的参与其中. VMware就在vSphere 7中采用了自主研发的PodVM: CRX引擎作为容器运行时. 管理层面上更是启用3台K8s Master来接管vSphere, 真正的把Pod和VM拉到同一管理平面. 每个PodVM有自己独立的vNIC, 享有NSX-T夹持后的分布式负载均衡和分布式防火墙和IDS. 目前vSphere 7对K8s SVC的处理就是把SVC条目作为流表下发到PodVM的vNIC上,既分布式负载均衡.
NSX-T一直以来就是典型Host Overlay SDN的代表, 而近年来Host Overlay结合可编程智能网卡门槛逐渐下降, 众多智能网卡厂家加入战局, 这两者的结合已成必然趋势. 说到这个值得提一下Nick McKeown这位大神, SDN奠基人, OpenFlow协议的制定者, Nicira公司的联合创始人(2012被VMware以12亿美金收购,有了今天的NSX), 2013联合创办Barefoot Networks, 做交换机芯片以及开创网络数据层编程语言P4, 去年被Intel收购了. 还没算上Nicira之前他买掉的公司, 早就上岸了. 纵观这位大神的职业生涯和研究方向, 只有软硬件技术交替领衔,相互加持的网络才是服务于应用的好网络.
回到我猜想的话题上来, 正如VMware使用K8s来拓展自己的vSphere一样, NSX-T也可以采用类Istio架构来拓展网络控制层面,改造一个通用流量引擎, 结合智能网卡的加持, 在vNIC层面上实现OSI7层服务覆盖. 没有了Sidecar就不仅仅是对业务代码不入侵了, 连操作系统都不入侵. 再加上VMware多年来做产品的理念就是简单易用,结合这些元素便能打造出一个我心目中的下一代SDN. 我的观点是SDN应该吸收Service Mesh的框架, 从而升级成下一代的SDN. SDN与Service Mesh的当下应该是相互依存的关系, 如同要成就帝业的君士坦丁与基督教一样.
上述纯属个人的猜想, 不是VMware的Roadmap, 如有雷同那我牛B坏了. 另希望各位看官不吝赐教, 祝好.
