UML类图笔记
UML类图是描述类之间的关系
概念
-
类(Class):使用三层矩形框表示。
第一层显示类的名称,如果是抽象类,则就用斜体显示。
第二层是字段和属性。
第三层是类的方法。
注意前面的符号,‘+’表示public,‘-’表示private,‘#’表示protected。 -
接口:使用两层矩形框表示,与类图的区别主要是顶端有<>显示 。
第一行是接口名称。
第二行是接口方法。 -
继承类(extends):用空心三角形+实线来表示。
-
实现接口(implements):用空心三角形+虚线来表示
-
关联(Association):用实线箭头来表示,例如:燕子与气候
-
聚合(Aggregation):用空心的菱形+实线箭头来表示
聚合:表示一种弱的‘拥有’关系,体现的是A对象可以包含B对象,但B对象不是A对象的一部分,例如:公司和员工
组合(Composition):用实心的菱形+实线箭头来表示
组合:部分和整体的关系,并且生命周期是相同的。例如:人与手
-
依赖(Dependency) :用虚线箭头来表示,例如:动物与氧气
-
基数 :连线两端的数字表明这一端的类可以有几个实例,比如:一个鸟应该有两只翅膀。如果一个类可能有无数个实例,则就用‘n’来表示。关联、聚合、组合是有基数的。
重复度:
- 单重复度,只存在一对一的关系。
- 多重复度,用列表、vector或其它的数据结构维护一对多,多对多的关系
这里再说一下重复度,其实看完了上面的描述之后,我们应该清楚了各个关系间的关系以及具体对应到代码是怎么样的,所谓的重复度,也只不过是上面的扩展,例如A和B有着“1对多”的重复度,那在A中就有一个列表,保存着B对象的N个引用,就是这样而已。
形式:依赖/关联, 组合/聚合,继承/实现
Dependency /Association,Composition/ Aggregation,Generalization/Realization
关联-属性指针-associate
- 双向关联-相互关联,
** 相互把对方作为自己的指针**

C1-C2:指双方都知道对方的存在,都可以调用对方的公共属性和方法。
在GOF的设计模式书上是这样描述的:虽然在分析阶段这种关系是适用的,但我们觉得它对于描述设计模式内的类关系来说显得太抽象了,因为在设计阶段关联关 系必须被映射为对象引用或指针。对象引用本身就是有向的,更适合表达我们所讨论的那种关系。所以这种关系在设计的时候比较少用到,关联一般都是有向的。
使用ROSE 生成的代码是这样的:
class C1{
public C2 theC2;
}
class C2 {
public C1 theC1;
}双向关联在代码的表现为双方都拥有对方的一个指针,当然也可以是引用或者是值。
- 单向关联-关联到它就把它当做自己的属性指针

C3->C4:表示相识关系,指C3知道C4,C3可以调用C4的公共属性和方法。
没有生命期的依赖。一般是表示为一种引用
生成代码如下:
class C3{
public C4 theC4;
}
class C4{
}单向关联的代码就表现为C3有C4的指针,而C4对C3一无所知。
- 自身关联(反身关联)-关联到自己,就是把自己当做属性指针
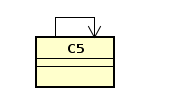
自己引用自己,带着一个自己的引用
代码如下:
class C5{
public C5 theC5;
}就是在自己的内部有着一个自身的引用。
2.依赖-依赖
就把它的指针或引用,作为自己的函数形参-dependency
(1)单向依赖

依赖:
指C5可能要用到C6的一些方法,也可以这样说,要完成C5里的所有功能,一定要有C6的方法协助才行。C5依赖于C6的定义,一般是在C5类的头文件中包含了C6的头文件。ROSE对依赖关系不产生属性。
注意,要避免双向依赖。一般来说,不应该存在双向依赖。
ROSE生成的代码如下:
class C6
{
public void Func(C7 *pC7Obj);
}
class C7
{
}(2)双向依赖
双向依赖关系图没有看到标准的画法,知道时候补上。
那依赖和聚合\组合、关联等有什么不同呢?
- 关联是类之间的一种关系,例如老师教学生,老公和老婆,水壶装水等就是一种关系。这种关系是非常明显的,在问题领域中通过分析直接就能得出。
- 依赖是一种弱关联,只要一个类用到另一个类,但是和另一个类的关系不是太明显的时候(可以说是“uses”了那个类),就可以把这种关系看成是依赖,依赖 也可说是一种偶然的关系,而不是必然的关系,就是“我在某个方法中偶然用到了它,但在现实中我和它并没多大关系”。例如我和锤子,我和锤子本来是没关系 的,但在有一次要钉钉子的时候,我用到了它,这就是一种依赖,依赖锤子完成钉钉子这件事情。
组合是一种整体-部分的关系,在问题域中这种关系很明显,直接分析就可以得出的。例如轮胎是车的一部分,树叶是树的一部分,手脚是身体的一部分这种的关系,非常明显的整体-部分关系。
上述的几种关系(关联、聚合/组合、依赖)在代码中可能以指针、引用、值等的方式在另一个类中出现,不拘于形式,但在逻辑上他们就有以上的区别。
这里还要说明一下,所谓的这些关系只是在某个问题域才有效,离开了这个问题域,可能这些关系就不成立了,例如可能在某个问题域中,我是一个木匠,需要拿着 锤子去干活,可能整个问题的描述就是我拿着锤子怎么钉桌子,钉椅子,钉柜子;既然整个问题就是描述这个,我和锤子就不仅是偶然的依赖关系了,我和锤子的关 系变得非常的紧密,可能就上升为组合关系(让我突然想起武侠小说的剑不离身,剑亡人亡...)。这个例子可能有点荒谬,但也是为了说明一个道理,就是关系 和类一样,它们都是在一个问题领域中才成立的,离开了这个问题域,他们可能就不复存在了
3.组合/聚合-属性对象-composite/aggreate
(1)组合-自己是实心的,去组合它,把它当做自己的属性对象,只是被组合的类不会单独存在(自己构造函数中使用)
组合(也有人称为包容):一般是实心菱形加实线箭头表示,如上图所示,表示的是C8被C7包容,而且C8不能离开C7而独立存在。但这是视问题域而定的, 例如在关心汽车的领域里,轮胎是一定要组合在汽车类中的,因为它离开了汽车就没有意义了。但是在卖轮胎的店铺业务里,就算轮胎离开了汽车,它也是有意义 的,这就可以用聚合了。
在《敏捷开发》中还说到,A组合B,则A需要知道B的生存周期,即可能A负责生成或者释放B,或者A通过某种途径知道B的生成和释放。
他们的代码如下:
class C8
{
public C9 theC9;
}
class C9
{
}可以看到,代码和聚合是一样的。具体如何区别,可能就只能用语义来区分了。
(2)聚合-自己空心的,去聚合它,把它当做自己的属性对象,被聚合的类可以单独存在(自己构造函数中不使用)
当类之间有整体-部分关系的时候,我们就可以使用组合或者聚合。
聚合:表示C9聚合C10,但是C10可以离开C9而独立存在(独立存在的意思是在某个应用的问题域中这个类的存在有意义。这句话怎么解,请看下面组合里的解释)。
代码如下:
class C10
{
public C11 theC11;
}
class C11
{
}总结聚合和组合:
问题域的语义上:组合中被组合类单独存在没有意义; 聚合中被聚合类在可以有单独存在的意义。
生命期上:组合中必须要负责被组合类的生命期; 聚合中可不负责被聚合类的声明期,可以由外部程序来创建和消亡(可用赋值)。
4.泛化和实现 derived/implement
(1)继承(Derived)-子对象指向父对象

泛化关系:如果两个类存在泛化的关系时就使用,例如父和子,动物和老虎,植物和花等。
ROSE生成的代码很简单,如下:
class C12 extends C13
{
}(2)接口实现(implement)

实现关系指定两个实体之间的一个合约。换言之,一个实体定义一个 合约 ,而另一个实体保证履行该合约 。
(转https://www.cnblogs.com/vincent0928/p/6568070.html)