WAV2LETTER ++:最快的开源语音识别系统
WAV2LETTER++: THE FASTEST OPEN-SOURCE SPEECH RECOGNITION SYSTEM
Vineel Pratap,Awni Hannun,徐连通,Jeff Cai,Jacob Kahn,Gabriel Synnaeve,Vitaliy Liptchinsky,Ronan Collobert
Facebook人工智能研究
摘要
本文介绍了最快的开源深度学习语音识别框架wav2letter ++。 wav2letter ++完全用C ++编写,使用ArrayFire张量库来实现最高效率。 在这里,我们解释了wav2letter ++系统的架构和设计,并将其与其他主要的开源语音识别系统进行了比较。 在某些情况下,wav2letter ++比用于语音识别的端到端神经网络训练的其他优化框架快2倍以上。 我们还表明,对于具有1亿个参数的模型,wav2letter ++的训练时间线性地扩展到64个GPU,这是我们测试的最高值。 高性能框架支持快速迭代,这通常是成功研究和对新数据集和任务进行模型调整的关键因素。
索引术语 - 语音识别,开源软件,端到端
1.引言
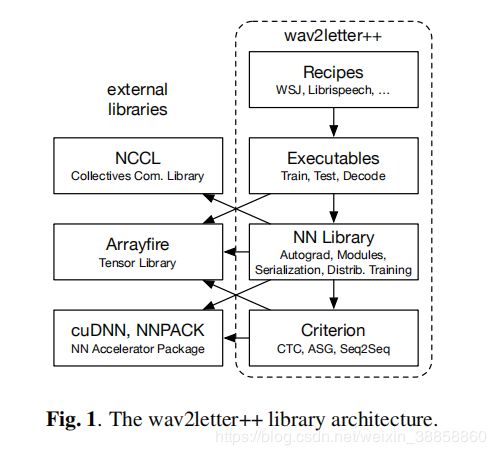
在自动语音识别(ASR)的日益增长的兴趣,开源软件生态系统已经看到ASR系统和工具包,包括Kaldi的亲liferation [1],ESPNet [2],OpenSeq2Seq [3]和Eesen [4] 。在过去的十年中,这些框架已经从基于隐马尔可夫模型(HMM)和高斯混合模型(GMM)的传统语音识别转变为基于端到端神经网络的系统。许多最近的开源ASR工具包,包括本文提供的工具包,都依赖于基于字形而不是音素的端到端声学建模。这种转变的原因有两方面:端到端模型明显更简单,HMM / GMM系统的准确性差距正在迅速缩小。 C ++是世界上第三大最受欢迎的编程语言1。它允许对高性能和关键系统进行完整的资源控制,此外,静态类型通过在编译时捕获任何合同不匹配来帮助大型项目。此外,可以从几乎任何编程语言轻松调用本机库。然而,由于主流框架中缺乏定义明确的C ++ API,机器学习社区中C ++的采用已经停滞不前,C ++主要用于性能关键组件。随着代码库变得越来越大,在脚本语言和C ++之间来回切换也变得麻烦且容易出错。此外,如果提供足够的库,在现代C ++中进行开发并不比在脚本语言中慢得多。在本文中,我们介绍了第一个完全用C ++编写的开源语音识别系统。通过使用现代C ++,我们不会牺牲编程的简易性,同时保持编写高效且可扩展的软件的能力。在这项工作中,我们专注于ASR系统的技术方面,例如训练和解码速度以及可扩展性。本文的其余部分结构如下。在第2节中,我们讨论了wav2letter ++的设计。在第3节中,我们将简要讨论其他现有的主要开源系统,并在第4节中对其性能进行基准测试。
2. DESIGN
wav2letter ++的设计受到三个要求的驱动。首先,该工具包必须能够有效地训练包含数千小时语音的数据集上的模型。其次,表达和整合新的网络架构,损失功能和其他核心操作应该是简单的。第三,从模型研究到部署的路径应该是直截了当的,需要尽可能少的新代码,同时保持研究所需的灵活性。
2.1.ArrayFire Tensor Library
我们使用ArrayFire [5]作为张量操作的主要库。我们选择ArrayFire有几个原因。 ArrayFire是一个高度优化的张量库,可以在多个后端执行,包括CUDA GPU后端和CPU后端。 ArrayFire还使用即时代码生成将一系列简单操作组合到单个内核调用中。这样可以更快地执行内存带宽绑定操作,并可以减少峰值内存使用。 ArrayFire的另一个重要特性是在阵列上构建和操作的简单接口。与同样支持CUDA的其他C ++张量库相比,ArrayFire接口不那么冗长,并且依赖于更少的C ++特性。
2.2数据准备和特征提取
我们的特征提取支持多种音频文件格式(例如wav,flac ... / mono,stereo / int,float)和几种特征类型,包括原始音频,线性缩放功率谱,log-Mels(MFSC)和MFCC。 我们使用FFTW库来计算离散傅立叶变换[6]。 wav2letter ++中的数据加载在每次网络评估之前即时计算功能。 这使得探索替代功能更简单,允许动态数据扩充并使得部署模型更加容易,因为完整的端到端管道可以从单个二进制文件运行。 为了在训练模型时提高效率,我们加载和解码音频并异步并行地计算功能。 对于我们测试的模型和批量大小,数据加载所花费的时间可以忽略不计。
2.3.Models
我们支持几种端到端序列模型。每个模型都分为网络和标准。网络仅是输入的函数,而标准是输入和目标转录的函数。虽然网络始终具有参数,但标准的参数是可选的。这种抽象允许我们使用相同的训练管道轻松训练不同的模型。支持的标准包括连接主义时间分类(CTC)[7],原始的wav2letter AutoSegCriterion(ASG)[8],以及关注的序列到序列模型(S2S)[9,10]。 CTC标准没有参数,而ASG和S2S标准都有可以学习的参数。此外,我们注意到添加新的序列标准特别容易,因为ASG和CTC等损失函数可以在C ++中高效实现。我们支持广泛的网络架构和激活函数 - 这里列出的内容太多了。对于某些操作,我们使用更高效的cuDNN操作扩展核心ArrayFire CUDA后端[11]。我们使用1D和2D概念以及cuDNN提供的RNN例程等。由于我们使用的网络库提供动态图形构造和自动区分,因此构建新图层或其他原始操作需要很少的努力。我们举例说明如何构建和训练具有二进制交叉熵损失的单层MLP(图2),以演示C ++接口的简单性。

图2.示例:使用自动微分,使用二元交叉熵和SGD训练的一个隐藏层MLP。
2.4培训和规模
我们的培训管道为用户提供了最大的灵活性,可以尝试不同的功能,架构和优化参数。培训可以以三种模式运行 - 训练(平坦训练),继续(继续检查点状态)和分叉(例如转学习)。我们支持标准优化算法,包括SGD和其他常用的基于一阶梯度的优化器。我们将wav2letter ++扩展为具有数据并行,同步SGD的更大数据集。对于进程间通信,我们使用NVIDIA集体通信库(NCCL2)2。为了最大限度地减少进程之间的等待时间并提高单个进程的效率,我们在构建用于训练的批处理之前对输入长度的数据集进行排序[12]。
2.5.Decoding
wav2letter ++解码器是一种波束搜索解码器,具有多种优化功能以提高效率[13]。我们使用与[13]相同的解码目标,其中包括语言模型和单词插入术语的约束。
解码器接口接受来自声学模型的发射和(如果相关)转换作为输入。 我们还给解码器一个包含单词字典和语言模型的Trie。 我们支持任何类型的语言模型,它公开我们的解码器所需的接口,包括n-gram LM和任何其他无状态参数LM。 我们在KenLM之上为n-gram语言模型提供了一个瘦包装器[14]。

3.相关工作
我们简要概述了其他常用的开源语音识别系统,包括Kaldi [1],ES-PNet [2]和OpenSeq2Seq [3]。 Kaldi语音识别工具包[1]是迄今为止最早的一种,它由一组独立的命令行工具组成。 Kaldi支持HMM / GMM和基于混合HMM / NN的声学建模,并包括基于电话的配方。端到端语音处理工具包(ESPNet)[2]与Kaldi紧密集成,并将其用于特征提取和数据预处理。 ESPNet使用Chainer [15]或PyTorch [16]作为训练声学模型的后端。它主要是用Python编写的,但是,遵循Kaldi的风格,高级工作流以bash脚本表示。在鼓励系统组件分离的同时,这种方法缺乏静态类型的面向对象编程语言在表达类型安全,可读和直观的接口方面的优势。 ESPNet以基于CTC的[7]和基于注意力的编码器 - 解码器[10]实现以及结合两种标准的混合模型为特色。类似于ESPNet,OpenSeq2Seq [3]具有基于CTC和编码器 - 解码器模型的特征,并且使用Tensor-Flow [17]而不是PyTorch作为后端,用Python编写。对于高级工作流,OpenSeq2Seq还依赖于调用Perl和Python脚本的bash脚本。 OpenSeq2Seq系统的一个显着特点是它支持混合精度训练。此外,ESPNet和OpenSeq2Seq都支持文本转语音(TTS)模型。表1描述了这些开源语音处理系统的分类。如表所示,wav2letter ++是唯一完全用C ++编写的框架,它(i)可以轻松集成到以任何编程语言虚拟实现的现有应用程序中;(ii)通过静态类型和面向对象编程更好地支持大规模开发; (iii)允许最高效率,如第4节所述。相比之下,动态类型语言(如Python)促进快速原型设计,但缺乏强制静态类型通常会阻碍大规模开发。
4.EXPERIMENTS
在本节中,我们将在比较研究中讨论ESPNet,Kaldi,OpenSeq2Seq和wav2letter ++的性能。 ASR系统是根据华尔街日报(WSJ)数据集[18]的大词汇量任务进行评估的。我们测量训练期间WSJ的平均纪元时间和平均话语解码延迟。我们用于实验的机器具有以下硬件配置:每台机器在NVIDIA SXM2模块上配备8个NVIDIA Tesla V100 Tensor Core GPU,内存为16GB。每个计算节点都有2个Intel Xeon E5-2698 v4 CPU,支持40(2 20)个内核,80个硬件线程(“内核”),2.20GHz。所有机器都通过100Gbps的In-finiBand网络连接。
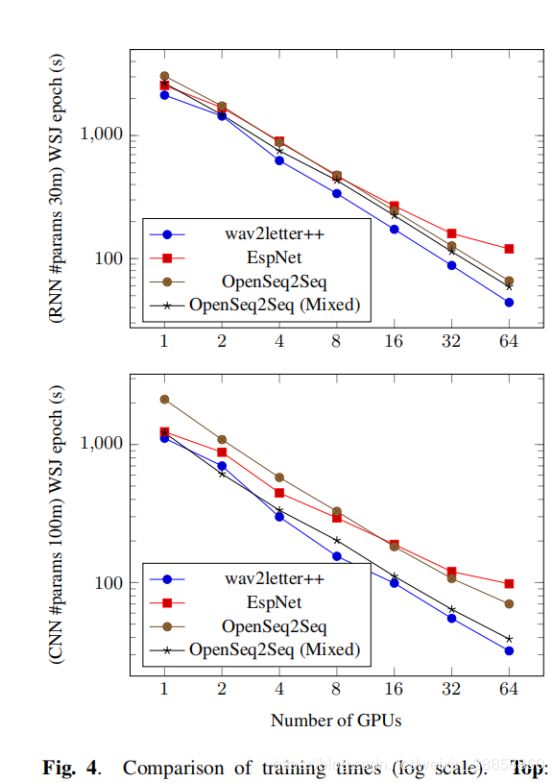
4.1.Training
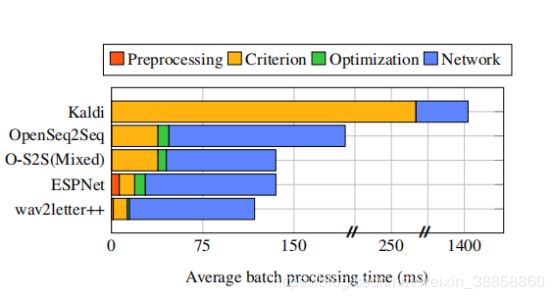
我们评估了扩展网络参数和增加GPU使用数量的培训时间。我们考虑了两种类型的神经网络架构:循环,具有3000万个参数,以及纯卷积,具有1亿个参数,分别如图4的顶部和底部图表所示。对于OpenSeq2Seq,我们考虑float32以及混合精度float16训练。对于两个网络,我们使用40维log-mel滤波器组作为输入,并使用CTC [7]作为标准(基于CPU的实现)。对于Kaldi,我们使用LF-MMI [19]标准,因为标准Kaldi配方中没有CTC培训。所有车型均采用SGD进行动力训练。我们使用每GPU 4个批量大小的批量。每次运行仅限于为每个GPU使用5个CPU内核。图3更详细地介绍了培训管道的主要组成部分;使用单个GPU在整个纪元上平均处理时间。对于这两种型号,wav2letter ++具有明显的优势,随着我们扩展计算而增加。对于具有3000万个参数的小型号,wav2letter ++比下一个最佳系统快15%以上,即使在单个GPU上也是如此。请注意,由于我们使用8台GPU机器,因此对16,32和64 GPU的实验涉及多节点通信。 ESPNet不支持开箱即用的多节点培训。我们通过将PyTorch DistributedDataParallel模块与NCCL2后端一起使用来扩展它。 ESPNet依赖于预先计算的输入功能,而wav2letter ++和OpenSeq2Seq为了灵活性而动态地计算功能。在某些情况下,混合精确训练会使OpenSeq2Seq的纪元时间减少1.5倍以上。这是wav2letter ++可以在未来受益的优化。 LF-MMI的Kaldi配方不会同步每个SGD更新的梯度; perepoch时间仍然慢20倍以上。我们在图4中没有包括Kaldi,因为标准(LF-MMI)和优化算法不容易比较。
- 训练时间的比较(对数标度)。 上图:具有30米参数的RNN,受DeepSpeech 2 [12]的启发:2个空间卷积层,接着是5个双向LSTM层,接着是2个线性层。 底部:具有100m参数的CNN,类似于[13]:18个时间卷积层,后面是1个线性层。
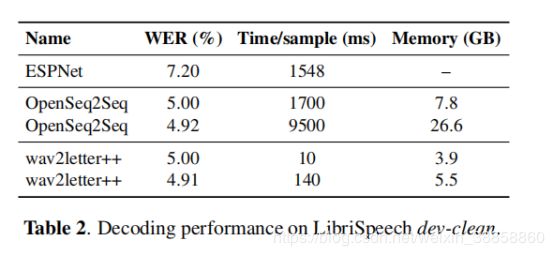
4.2解码
wav2letter ++包括一个用C ++编写的单程波束搜索解码器(参见第2.5节)。我们将其与OpenSeq2Seq和ES-PNet中提供的其他光束搜索解码器进行对比。 Kaldi不包括在内,因为它不支持CTC解码,并且实现了基于WFST的解码器。我们为每个解码器提供相同的预先计算的发射,这些发射是由在LibriSpeech上训练的完全卷积的OpenSeq2Seq模型Wave2Letter + 3生成的。这样可以在相同模型下独立测量性能。 4-gram LibriSpeech语言模型用于OpenSeq2Seq和wav2letter ++,因为ESPNet不支持n-gram LM解码。在表2中,我们报告解码时间和峰值内存使用情况,单线程解码,LibriSpeech dev-clean达到5.0%的WER,以及每个框架的最佳可用WER。对超参数进行了大量调整,以便报告的结果反映了报告的WER的最佳速度。 wav2letter ++不仅比同类解码器的性能高出一个数量级,而且使用的内存也少得多。
5.结论
在本文中,我们介绍了wav2letter ++:一种用于开发端到端语音识别器的快速而简单的系统。该框架完全用C ++编写,这使得它能够有效地训练模型并执行实时解码。与其他语音框架相比,我们的初始实现显示了有希望的结果;虽然wav2letter ++可以继续从进一步优化中受益。由于其简单易用的界面,wav2letter ++非常适合作为端到端语音识别快速研究的平台。与此同时,我们保留了使用基于Python的ASR系统进行某些优化以缩小与wav2letter ++的差距的可能性。