基于文档的存储
MongoDB的数据是基于文档的存储,可以将文档理解为json对象。这个概念非常的简单,我们来看看一个例子。
一年级有好几个班,每个班有一个班主任,这些班主任带着几十个学生。在SQL中,有如下的关系:
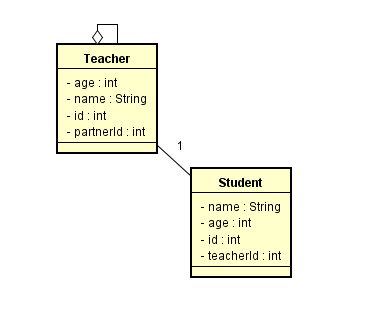
在MongoDB里,可以这样表示,名为“teacher”的collection里有如下的数据:
[
{
"_id": {
"$oid": "58cf85fcc5d27e4448cf4d13"
},
"age": 40,
"name": "罗永浩",
"students": [
{
"age": 18,
"name": "小明"
},
{
"age": 19,
"name": "小红"
}
],
"partner": {
"age": 30,
"name": "王自如"
}
}
]
teacher这个collection里存储的是多个文档,每个文档表示一个班主任,嵌套了一个文档的集合,students。我们看到,和SQL不同的是,teacher的字段可以是另一个文档。
标准
对于习惯了SQL的语法的开发人员来说,一开始接触MongoDB会觉得不太适应,在执行命令的时候,我们提供的参数是一个json对象,例如:
//查询年龄大于18岁,不包含18岁
db.collection.find({age: {$gt: 18}})
SELECT * FROM Collection WHERE age > 18
我们认为SQL的语句是很自然的,它是命令式的,就好像让数据库帮我们“选出集合中的对象,条件是年龄大于18岁”。
而MongoDB不是命令式的,而是描述式的,就好像是说,帮我们“选出集合中的对象,它有以下的特征: 年龄大于18岁”。
这两种方式各自有着优缺点,举个例子,我们想让一个同事帮忙去拿桌上的一个红色文件夹,那么我们会和他说,“请去我桌上拿一个文件夹给我,红色的那个”,或者我们指着一件红色的衣服说,“请去我桌上拿一个文件夹给我,是这种颜色的”。前者简单明了,前提是双方都知道红色是什么颜色; 后者是用另一个对象作为标准,来描述某种特征,那么双方并不需要知道红色是什么颜色,只需要到你的座位上,和标准颜色进行比较,如果匹配,就是想要的对象。
那么问题来了,如果你的桌子上有两个红色的文件夹,一个是桃红色,另一个是粉红色,那么当你说“红色的那个”的时候,你的同事怎么知道是哪一个呢?即使你说“桃红色的那个”,一个直男程序员也很有可能会搞错。


所以这种情况下,拿着一个桃红色的物体作为标准,可以消除歧义。MongoDB所谓的标准(Criteria),就是这样的思路。基于文档的存储,对于“查询”的理解,是指寻找和标准匹配的文档。
如何描述一个作为标准的对象
描述一个作为标准的对象(下文称之为标准),有下面的原则:
-
标准包含目标对象的一个或多个属性,例如
{"age": 40} { "age": 40, "name": "罗永浩" } -
标准的属性可以是嵌套属性,例如:
{ "partner.name": "王自如" } -
目标属性是一个对象的时候,可以提供一个对象作为标准值,将执行全文匹配,而且字段顺序是重要的,例如:
{ "partner": { "age": 30, "name": "王自如"} } { "partner": {"name": "王自如", "age": 30} } //匹配失败 { "partner": { "age": 30} } //匹配失败 -
目标属性是一个数组的时候,可以提供一个数组作为标准值,将执行全文匹配,而且元素顺序是重要的,或者提供一个元素的值,只要数组包含该元素就可以匹配成功,例如:
"students": [{"age": 18, "name": "小明"}, {"age": 19,"name": "小红"}] //全文匹配 "students": {"age": 18, "name": "小明"} //单元素匹配 -
目标属性是一个数组的时候,可以使用数组下标进行匹配,例如:
{"students.0.age": 18} -
可以使用包含操作符的对象作为对字面值的扩展,这加强了标准值的描述能力,。例如:
{"students.age": { "$gt": 18 } } {"students": {"$all": [{"age": 18, "name": "小明"}, {"age": 19,"name": "小红"}]}} //使用$all操作符来消除标准值中的顺序要求 {"students": {"$size": 2}} //使用$size操作符来描述标准值的额外属性
MongoDB的JavaScript引擎
接下来我们讨论的是,MongoDB的JavaScript引擎。在数据库中,提供JavaScript的运行环境,看上去是一件很怪的事情。但是我们将会了解到,为什么MongoDB这样做。
MongoDB的脚本文件也是用JavaScript编写,我们可以编写出强大灵活而且易读的脚本。
db = connect("localhost:27017/test");
var id = ObjectId();
db.teacher.insertMany([
{
_id: id,
age: 40,
name: "罗永浩",
students: [
{
age: 20,
name: "小玉"
}
]
}
]);
let cursor = db.teacher.find({ "students.0.name": "小玉" });
while (cursor.hasNext()) {
printjson(cursor.next());
}
在插入数据之前,我们可以通过ObjectId()获取一个新的id,而不需要由MongoDB来自动生成。
Aggregation Pipeline
MongoDB提供的数据聚合分析的方式,称之为Aggregation Pipeline(聚合管道)。管道是一个隐喻,揭示了对数据的处理是流式的(熟悉LingQ的朋友对流式不陌生)。假设有一个工厂负责处理数据,那么不同的工艺会有独立的车间,可能不同的车间会使用相同的工艺,但是使用的参数不同。数据在流水线上运输,经过不同的车间,会用不同的工艺来处理,最后会产生我们想要的数据。在MongoDB里,一种工艺称之为Stage,而一个车间称之为Pipeline,对数据的处理是由多个Pipeline串联起来达到目的。
我们将介绍4种最基本的Stage:筛选,分组,排序和投影。
$match,也就是筛选,是指过滤出想要的数据。
db.teacher.aggregate({
"$match": {"name": "罗永浩"}
})
$group,也就是分组,是指将数据分组,通常分组的目的是为了进行分组内的数据计算。_id是必须的,指示分组依据的属性的值,后面跟着一个或多个计算属性。
db.teacher.aggregate({
"$group": {
"_id": "$name",
"studentCount": {"$sum": {"$size": "$students"}}
}})
//结果
/* 1 */
{
"_id" : "比尔 盖茨",
"studentCount" : 2
}
/* 2 */
{
"_id" : "罗永浩",
"studentCount" : 2
}
注意,"_id": "$name"的写法,而不是"_id": "name",这里的$表示的意思类似于Linux Shell命令行中的变量,当你在MongoDB的语句的值,引用某个属性名的时候,应该使用$前缀,否则会被视为字面值。我们把这个单独拎出来强调一下:
MongoDB的语句的值,引用某个属性名的时候,需要加前缀$
特别的,如果我们想要统计所有学生的数量,那么应该将所有老师都视为一个分组,我们可以使用"_id": null来达到这个目的。
db.teacher.aggregate({
"$group": {
"_id": null,
"studentCount": {"$sum": {"$size": "$students"}}
}})
//结果
/* 1 */
{
"_id" : null,
"studentCount" : 4
}
$sort,也就是排序。
db.teacher.aggregate({
"$sort": {"name": 1} //1表示升序,-1表示降序
})
$project,也就是投影。使用这个名词,是指像是用灯光照射物体的不同角度得到不同的影子,我们可以通过抽取和计算一个对象的一个或多个属性,来构造另一个对象,也就是把基于一个对象的值进行某些计算,得到另一个对象的值。
db.teacher.aggregate({
"$project": {
"teacherName": "$name",
"teacherGrade": {
"$cond": [{"$gte": ["$age", 45]}, "old", "young"]
}
}
})
将Pipeline串联起来,只需要将它们按照顺序放进数组中:
db.teacher.aggregate([
{
"$match": {"name": "罗永浩"}
},
{
"$project": {
"teacherName": "$name",
"teacherGrade": {
"$cond": [{"$gte": ["$age", 45]}, "old", "young"]
}
}
},
])
聪明的你一定发现了,我们在SQL中很容易找到Aggregation Pipeline对应的语句:
- $match, $project -> "select xxx as xxx from"
- $group -> "group by"
- $sort -> "order by"
Look Up
你也许听说过,MongoDB不支持跨表查询,如果你熟悉SQL,那么你很有可能第一时间感觉诧异。如果不支持跨表查询,那么数据库中的“关系”将无法实现。嘿,别忘了,MongoDB就是一个NoSQL数据库,它没有“关系”这个概念。我们会在之后的章节中讨论,“没有关系”为什么会没有关系。现在先让我们了解一个折衷的设计,MongoDB的跨表查询:$lookup。
6 Rules
6 Rules of thumb for mongodb schema design
优先选择内嵌文档;
如果文档需要单独被访问,或者数量有几千条,那么不适合内嵌;
一对多(几百左右)使用内嵌ObjectId的方式,一对非常多(几千以上)的时候使用父级引用。(双向引用似乎结合了两者的优点,但也带来了操作的非原子性)
不要担心应用级别的join,在建立索引和使用投射(减少网络传输量)的情况下,应用级别的join和数据库的join的性能差异不大。
在读写比高,可以接收操作非原子性的情况下,将信息冗余到One端或者N端。这个称之为
反范式。数据库设计要考虑应用的读写情况。
Map-Reduce
Map-Reduce,相对于Aggregation Pipeline来说,就像是工厂里的定制流程一样,有两个团队会参与其中,M团队负责将原始数据加工(“投影”),然后分组,再由R团队针对每个分组,将数据整合成一个输出。
这看上去像是$project和$groupby的结合。最大的差异是,M团队和R团队是"定制化"的,“客户”通过编写JavaScript函数,更加灵活的处理数据投影,分组和整合的过程,这种灵活的处理能力,得益于MongoDB提供的JavaScript引擎。
In this map-reduce operation, MongoDB applies the map phase to each input document (i.e. the documents in the collection that match the query condition). The map function emits key-value pairs. For those keys that have multiple values, MongoDB applies the reduce phase, which collects and condenses the aggregated data. MongoDB then stores the results in a collection. Optionally, the output of the reduce function may pass through a finalize function to further condense or process the results of the aggregation.
注意的是,对于某个key下只有一个文档的情况下,是不会经过Reduce的,这要求了,Map函数对于单个文档要投射出,和Reduce之后一样的值,不然就会导致最后结果的结构不一致。
我们来看一个图文例子:
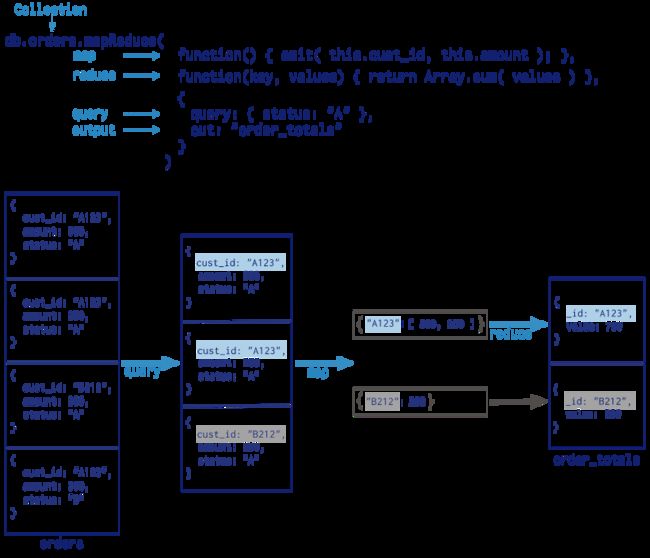
Map-Reduce的设计原则是强大灵活的数据分析框架,但是它的缺点是比较慢,一般不用于实时的数据处理,我们往往会编写相应的数据脚本来运用这个框架。
一个使用Map-Reduce的脚本的例子:
[
{
"_id": {
"$oid": "58d4709f17d28ccee472913e"
},
"age": 40,
"name": "罗永浩",
"students": [
{
"age": 20,
"name": "小玉"
}
]
},
{
"_id": {
"$oid": "58d8e46474eabb47fc43c1a9"
},
"age": 40,
"name": "罗永浩",
"students": [
{
"age": 19,
"name": "小天"
}
],
"partner": {
"age": 40,
"name": "方舟子"
}
},
{
"_id": {
"$oid": "58d8e46474eabb47fc43c1aa"
},
"age": 50,
"name": "比尔盖茨",
"students": [
{
"age": 29,
"name": "小蓝"
}
],
"partner": {
"age": 50,
"name": "鲍尔默"
}
}
]
我们先要统计的是,罗永浩和比尔盖茨,他们各自带的所有的学生的年龄的总和。
db = connect("localhost:27017/test");
let map = function() {
let totalAge = 0;
for(var i = 0; i< this.students.length; i++) {
totalAge += this.students[i].age;
}
emit(this.name, totalAge);
};
let reduce = function(key, values) {
let totalAge = 0;
return Array.sum(values);
}
db.teacher.mapReduce(map, reduce, {
query: {},
out: "totalAge"
});
注意,在map, reduce函数里的print和printjson是不会输出到控制台的,需要在mongodb的日志里查看。
文本搜索
文本搜索是一个非常实用的场景。
按照拼音排序
如果能在MongoDB里按照拼音排序,那么想必是极好的,这也是很常见的需求。然而虽然有Collation这个概念,但是:
zh@collation=pinyin 会报错,提示这个值无效;
collation的排序似乎会受到字符集的影响。按照Character set and collation for simplified Chinese — MySQL的描述,使用不同的字符集和collation的组合,会得到不同的排序结果。MongoDB使用的utf8的字符集,使用拼音排序得到的结果,并不符合预期。
综上所述,最方便的实现,是插入一个拼音的字段。