决策树——基于类的编程实现(第四课)1
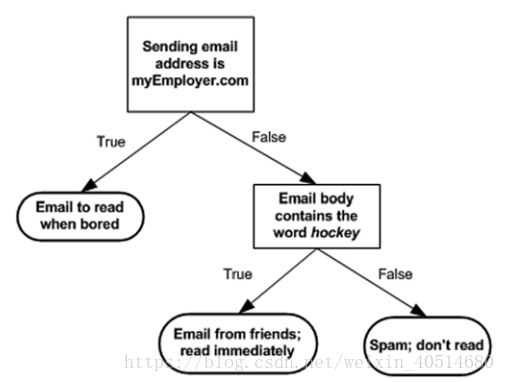
上面这个流程图就是一个决策树。它包含了决策块(长方形,后面用圆形)和终点块(椭圆形,后面用长方形),其中终点块表示已经做出了对应的决策。决策树还包含左右分支,对应于决策块的不同取值。决策树提取数据中的知识表现良好。
创建一个决策树类
DecisionTree <- R6Class("DecisionTree",
private = list(
tree = NULL
),
public = list(
initialize = function(){
private$tree <- igraph::graph.empty()
},
getTree = function(){
private$tree
}
)
)
#给决策树类加公共方法createDataSet,生成数据集
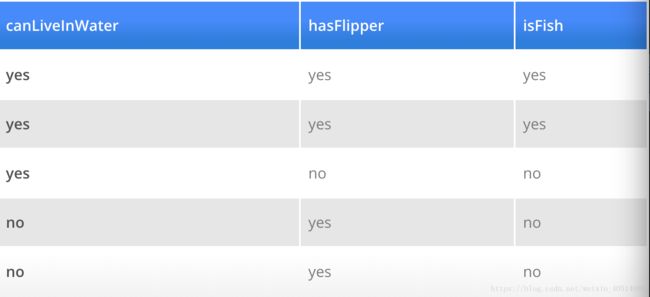
createDataSet <- function(){
canLiveInWater <- c('yes','yes','yes','no','no')
hasFlipper <- c('yes','yes','no','yes','yes')
isFish <- c("yes","yes","no","no","no")
dataSet <- data.frame(canLiveInWater,hasFlipper,isFish,stringsAsFactors = F)
dataSet
}
DecisionTree$set("public","createDataSet",createDataSet,overwrite=T)决策树的伪代码:
Check if every item in the dataset is in the same class:
If so return the class label
Else
Check if the dataset has any feature:
If none return the most voted class label
Else
find the best feature to split the data
split the dataset
create a branch node
for each split
call createTree and add the result to the branch node
return branch node 建树
想要建立一个决策树,首先需要做的决定就是用什么特征来切分数据集。通常有三种分割数据集的方法,分别对应于决策树的三种算法:
- 信息增益;
- 信息增益比;
- 基尼增益。
给决策树类动态增加一个计算熵的方法,一个数据集的熵通常是根据它的类别列来计算。
calcShannonEnt <- function(dataset){
numCols <- ncol(dataset)
clasCol <- dataset[,numCols]
tbl <- table(clasCol)
tbl <- tbl[!tbl==0]#去掉频数为0的项,避免log报错
prob <- tbl/sum(tbl)
-sum(prob*log(prob,base=2))
}
DecisionTree$set("public","calcShannonEnt",calcShannonEnt,overwrite=T)
dT <- DecisionTree$new()
myDat <- dT$createDataSet()
dT$calcShannonEnt(myDat)熵的值越大,表明数据的混杂程度就越高,因此用熵较高的特征来划分数据集能取得较好的划分效果。
可以用原始数据集来做个试验,当我将原始数据集的第一个标签换成“maybe”,这时类别列就有三种类别,显然数据更加复杂了,熵应该会升高。
myDat[1,ncol(myDat)] <- 'maybe'
myDat
dT$calcShannonEnt(myDat)
计算结果为1.3709,熵果然增大了,也就是说明数据集的混乱程度更大了。
- 当一个数据集根据一个特征划分成若干个小的数据集之后,这些数据集的熵如何计算?还是用上述的数据集作为例子。
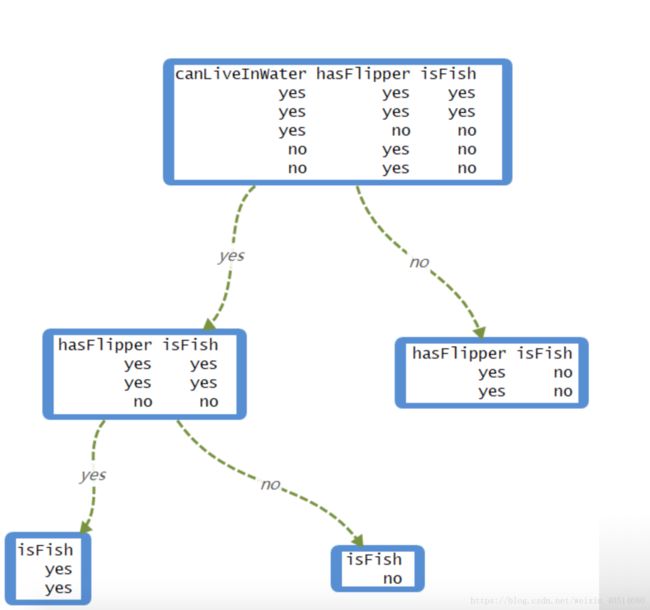
假如用第一个指标(canLiveInWater)来划分数据集,由于该指标只有两个取值,所以可以将原数据集划分成两个子数据集。
dataset1 d a t a s e t 1

dataset2 d a t a s e t 2

值得注意的是,划分之后的两个子数据集已经不再包含第一个指标(canLiveInWater)。
我们令原数据集的熵是 Hori H o r i ,现在我们分别计算数据集 dataset1 d a t a s e t 1 和 dataset2 d a t a s e t 2 的熵,分别记为 H1 H 1 和 H2 H 2 ,然后计算它们的权重和: w1H1+w2H2 w 1 H 1 + w 2 H 2 ,记为 Hnew H n e w 。最后,我们就可以得到由第一个特征(canLiveInWater)分割数据集产生的信息增益:
还有一个问题就是上面的权重 w1,w2 w 1 , w 2 如何计算?
事实上,这个问题很简单:
给决策树类动态添加一个分割数据集的方法(基于某一个特征):
splitDataSet <- function(dataset, axis){#axis表示用来分割数据集dataset的特征所在的列数,即用第几维特征来切分数据集
retDataSet <- list()
featureCol <- dataset[axis]
vals <- unique(unlist(featureCol))
for(val in vals){
tmp <- subset(dataset,dataset[axis]==val)
tmp <- tmp[-axis]
retDataSet[[as.character(val)]] <- tmp
}
retDataSet
}
DecisionTree$set("public","splitDataSet",splitDataSet,overwrite = T)上面分割数据集的方法有了之后,我们只需要得到分割数据集最佳的特征就可以将数据集划分来建立决策树了,但是分割数据集的最佳特征如何确定?这里还需要继续给决策树类添加一个寻找最佳分割特征的方法:
chooseBestFeatureToSplit <- function(dataset){
numFeatures <- ncol(dataset) -1
H_ori <- self$calcShannonEnt(dataset)
H_new <- c()
for(i in 1:numFeatures){
datasets <- self$splitDataSet(dataset,i)
H_tmp <- c()
for(j in 1:length(datasets)){
H_tmp <- c(H_tmp,self$calcShannonEnt(datasets[[j]]))
}
H_new <- c(H_new,sum(sapply(datasets,nrow)/nrow(dataset)*H_tmp))
}
infoGain <- H_ori - H_new
return(which(infoGain==max(infoGain))[1])
}
DecisionTree$set("public","chooseBestFeatureToSplit",chooseBestFeatureToSplit,overwrite = T)有了切分数据集的方法和寻找最优切分特征的方法之后,就可以对原数据集进行切分了。
dT <- DecisionTree$new()
myDat <- dT$createDataSet()
bestFeat_1 <- dT$chooseBestFeatureToSplit(myDat)
datasets_step1 <- dT$splitDataSet(myDat,bestFeat_1)
bestFeat_2 <- dT$chooseBestFeatureToSplit(datasets_step1[[1]])
datasets_step2 <- dT$splitDataSet(datasets_step1[[1]],bestFeat_2)