视频包括::图像(还有文字)和音频
视频的本质:具有时间顺序的图像序列。特点:价值密度低,体积大,增速快。
关键帧:视频序列中的代表性帧
视频的任务包括:(第一,物体的跟踪;第二,目标的分类识别;;第三,行为动作的识别)
基于视频理解方向的就业职位
视频推荐:微博,抖音,百度
视频监控:海康,大华,宇视
Intelligent Video surveillance 视频监控
按对视频的理解层次,技术可以分为底层,中层和高层三个等级:
- 底层:目标跟踪(找出感兴趣的前景,持续追踪)
- 中层:目标分类与识别(前景是什么东西)-------一直在做的在这个位置
- 高层:行为动作分类(在做什么)---------视频理解,视频监控及人机交互的基础。
智能:自动,全天候,实时分析及告警
1. 目标跟踪(底层,在哪里)
运动目标检测(从背景中分离出运动的前景):
1.帧间差分
2.背景差分
3.光流法
运动目标跟踪:(感觉跟踪是一个单独的话题,因此先不分散精力,作为了解就好)
1.卡尔曼滤波
2.粒子滤波
3.均值飘移
2. 物体分类识别(中层,是什么)
3. 人的行为识别(高层,在干什么)
(属于模式识别,有一段典型动作编码,只需与此编码比对,区分行为动作类型。
目的:给一段视频序列打动作类型标签
应用:视频检索,视频推荐)
(13年的论文,传统方法)
3.1 模板匹配法:鲁棒性差
3.2 状态空间法:(概率转移法):通过将系列动作构建状态图,然后通过某种概率将这些状态节点的依存关系联系起来
动态贝叶斯网络
隐马科夫模型
跟踪问题的解决方案
- 上个时代的巅峰--相关滤波(KCF)
- 如今是--基于SiamFC系列发展
视频动作的特点
- 动作本身就具有时序动态变化:
- 短暂的,如挥手
- 连续一段时间的,如慢跑
- 算法时间成本:视频可能很长按天年计,因此时间成本很大。
因此需要建模动作的动态变化
根据复杂度和持续时间,行为分析(视频动作的类型)
- 静态姿势,如手势
- 运动行为 如单体普通动作(难点)
- 复杂事件行为(交互,群体行为)(难点)
视频动作检测的任务
- 有没有某个标准动作
- 如果有,确定开始时间及结束时间
动作分析的(瓶颈):
- 对于动作的定义不清,开始及结束时间点也不清楚
- 同一动作由于目标的尺度,相机的抖动,视角的变化导致同一动作类内方差大
- 当动作类型做空间细分时,如慢跑和跑步,不同模型的类间方差小。
- 复杂环境的遮挡
- 模型泛化能力
- 需要大量标注数据
动作识别中研究哪些类型动作可以基于图像识别,哪些动作基于视频中的时空特征做,很重要。
多相机目标跟踪:
一个相机检测到新目标时,须与其他相机发生信息交互:系统内目标还是系统外目标,保证目标编号的唯一性。
感知在自动驾驶领域只是一个重要的前置步骤,后期需要决策,规划,控制。视频监控则不然,视觉基本是主流,语音都很少。
人体动作识别
按数据源又可分为:
- 基于RGB图像
传统的动作识别:
模板匹配
基于时空兴趣点
基于轨迹
基于深度学习:
基于双流卷积网络(两个流之间没有信息交互)
基于三维卷积网络(考虑时间间隔很短,无法捕获长时信息)
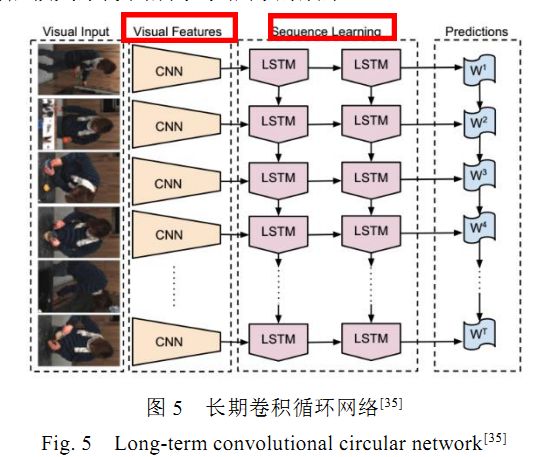
基于lstm网络
3D深度相机:在2D基础上加一个类似激光的传感器,可以返回深度信息(目标距离相机的距离)
- 基于RGB-D图像
基于骨骼的方法(骨骼信息不受背景及光照影响,鲁棒性强,重点)
基于深度序列的方法
基于多特征融合的方法
可作为生物特征的特征应具有的性质:
- 区别性
- 持久性
- 普遍性
- 易收集
如人脸,手势,虹膜,眼周 指纹 。
-------> 适用距离越来越短。
比较重要的人脸及手势。
人脸识别方法:
- 最早:特征脸---对光照和姿态没有鲁棒性
- PCA
- LDA
- LBP
(特征向量)
人脸识别的问题:监控场景人脸的图像分辨率太低
PTZ相机监控系统:15m距离可获得高分人脸