(三篇长文让你玩6Pandas)数据分析入门_PART2常用工具包_CH02数据分析工具:Pandas__Part01(Series和DataFrame全面操作)
'''
【课程2.2】 Pandas数据结构Series:基本概念及创建
"一维数组"Serise
'''
'\n【课程2.2】 Pandas数据结构Series:基本概念及创建\n\n"一维数组"Serise\n\n'
# Series 数据结构
# Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引
# Series 数据结=1标签+2数据数组(可以理解为有索引顺序的dict)
import numpy as np
import pandas as pd
s=pd.Series(np.random.rand(5))
print(s)
print('------')
print(type(s))
0 0.830450
1 0.674102
2 0.528299
3 0.150878
4 0.952043
dtype: float64
------
# Series 创建方法一:由字典创建,字典的key就是index,values就是values
#只要index有一个str则将其他数字类型自动转换为str
dic = {'a':1 ,'b':'hello' , 'c':3, 4:4, 5:5}
s=pd.Series(dic)
print(s)
a 1
b hello
c 3
4 4
5 5
dtype: object
# Series 创建方法二:由数组创建(一维数组)
# 默认index是从0开始,步长为1的数字
arr=np.random.randn(5)
s=pd.Series(arr)
print(arr)
print(s)
# index参数:设置index,长度保持一致
# dtype参数:设置数值类型
'''
pd.Series(
data=None,
index=None,
dtype=None,
name=None,
copy=False,
fastpath=False,
)
'''
s=pd.Series(arr,index=list('abcde'),dtype=np.str)
print(s)
[ 0.26383154 0.97382125 0.13994526 -0.60732141 1.32883897]
0 0.263832
1 0.973821
2 0.139945
3 -0.607321
4 1.328839
dtype: float64
a 0.26383153983884505
b 0.9738212455558085
c 0.1399452564766354
d -0.6073214101102407
e 1.3288389721491793
dtype: object
# Series 创建方法三:由标量创建(Series中所有元素都相同)
s=pd.Series(10,index=range(4))
print(s)
0 10
1 10
2 10
3 10
dtype: int64
# Series 名称属性:name(可有可无 一个实体series对象只有唯一一个name)
# name为Series的一个参数,创建一个数组的 名称
# .name方法:输出数组的名称,输出格式为str,如果没用定义输出名称,输出为None
s1=pd.Series(np.random.rand(5))
print(s1)
print('-----')
s2=pd.Series(np.random.rand(5),name="test")
print(s2)
print(s1.name,s2.name,type(s2.name))
# .rename()重命名一个数组的名称,并且新指向一个数组,原数组不变
s3=s2.rename('xjxj')
print(s3)
print(s3 is s2)
print(s3.name,s2.name)
0 0.603552
1 0.007823
2 0.581088
3 0.262479
4 0.366710
dtype: float64
-----
0 0.638098
1 0.012841
2 0.659852
3 0.009916
4 0.444856
Name: test, dtype: float64
None test
0 0.638098
1 0.012841
2 0.659852
3 0.009916
4 0.444856
Name: xjxj, dtype: float64
False
xjxj test

#作业answer
#1 dict方式创建
dic={'Jack':90.0,'Marry':92,"Tom":89,'Zack':65}
s1=pd.Series(dic,name="作业1")
print(s1)
#2 数组方式创建
ar=np.array((90.0,92,89,65))
s2=pd.Series(ar,index=('Jack','Marry',"Tom",'Zack'),name="作业1")
print(s2)
Jack 90.0
Marry 92.0
Tom 89.0
Zack 65.0
Name: 作业1, dtype: float64
Jack 90.0
Marry 92.0
Tom 89.0
Zack 65.0
Name: 作业1, dtype: float64
'''
【课程2.3】 Pandas数据结构Series:索引
位置下标 / 标签索引 / 切片索引 / 布尔型索引
'''
'\n【课程2.3】 Pandas数据结构Series:索引\n\n位置下标 / 标签索引 / 切片索引 / 布尔型索引\n\n'
# 位置下标,类似序列 (和序列不同的index【-1】不能为负)
# 位置下标从0开始
# 输出结果为numpy.float格式,
# 可以通过float()函数转换为python float格式
# numpy.float与float占用字节不同
s=pd.Series(np.random.rand(5))
print(s[0],type(s[0]),s[0].dtype)
print(float(s[0]),type(float(s[0])))
0.6358412386028008 float64
0.6358412386028008
# 标签索引
# 方法类似下标索引,用[]表示,内写上index,注意此处index是字符串
s=pd.Series(np.random.rand(5),index=list('abcde'))
print(s)
print(s['a'],type(s['a']),s['a'].dtype)
# 如果需要同时选择多个标签的值,用[[]]来表示(相当于[]中包含一个列表!!!)
# 多标签索引结果是新的数组
sci=s[['a','b','c']]
print(sci,type(sci))
a 0.541327
b 0.810801
c 0.296037
d 0.794296
e 0.899370
dtype: float64
0.5413267940720663 float64
a 0.541327
b 0.810801
c 0.296037
dtype: float64
#切片索引
#1 注意:用index做切片是左闭右闭
#序列切片可以有[1:-1]负数序号
#2下标索引做切片,和list写法一样
#3 有str序列的Series也可以用下标索引(数字)做切片
s1=pd.Series(np.random.randint(10,size=5))
s2=pd.Series(np.random.randint(10,size=5),index=list("abcde"))
print(s1[1:4],'\n',s1[1:-1],'\n',s1[2])
print('---')
print(s2["a":"b"],'\n',s2['a'])
print('---')
print(s2[1:-1],'\n',s2[2])
1 3
2 5
3 0
dtype: int32
1 3
2 5
3 0
dtype: int32
5
---
a 5
b 9
dtype: int32
5
---
b 9
c 5
d 2
dtype: int32
5
# 布尔型索引
# 数组做判断之后,返回的是一个由布尔值组成的新的Series
# .isnull() / .notnull() 判断是否为空值 (None代表空值,NaN代表有问题的数值,两个都会识别为空值)
s=pd.Series(np.random.rand(3)*100)
s[4]=None #添加1个空值None
print(s)
bs1 = s > 50
bs2 = s.isnull()
bs3 = s.notnull()
print(bs1, type(bs1), bs1.dtype)
print(bs2, type(bs2), bs2.dtype)
print(bs3, type(bs3), bs3.dtype)
print('-----')
print(s>50)
print('-----')
print(s[s>50])
print('-----')
print(s[bs3])
0 12.5679
1 73.037
2 69.7116
4 None
dtype: object
0 False
1 True
2 True
4 False
dtype: bool bool
0 False
1 False
2 False
4 True
dtype: bool bool
0 True
1 True
2 True
4 False
dtype: bool bool
-----
0 False
1 True
2 True
4 False
dtype: bool
-----
1 73.037
2 69.7116
dtype: object
-----
0 12.5679
1 73.037
2 69.7116
dtype: object

#作业answer
s=pd.Series(np.random.rand(10)*100,index=list('abcdefghij'))
print(s)
print('-------')
print(s['b'],s['c'])
print('-------')
print(s[4:7])
print(s[[4,5,6]])
print('-------')
print(s[s>50])
a 47.610866
b 32.879041
c 60.843136
d 25.798653
e 16.734771
f 72.011496
g 13.186102
h 67.730150
i 28.785863
j 82.482446
dtype: float64
-------
32.87904131859861 60.84313579685892
-------
e 16.734771
f 72.011496
g 13.186102
dtype: float64
e 16.734771
f 72.011496
g 13.186102
dtype: float64
-------
c 60.843136
f 72.011496
h 67.730150
j 82.482446
dtype: float64
'''
【课程2.4】 Pandas数据结构Series:基本技巧
数据查看 / 重新索引 / 对齐 / 添加、修改、删除值
'''
'\n【课程2.4】 Pandas数据结构Series:基本技巧\n\n数据查看 / 重新索引 / 对齐 / 添加、修改、删除值\n\n'
# 数据查看
# .head()查看头部数据
# .tail()查看尾部数据
# 默认查看5条
s=pd.Series(np.random.rand(50))
print(s.head(10))
print(s.tail())
0 0.583793
1 0.340821
2 0.153140
3 0.726648
4 0.482695
5 0.652023
6 0.328461
7 0.177034
8 0.217062
9 0.341393
dtype: float64
45 0.425366
46 0.712421
47 0.423743
48 0.980984
49 0.146227
dtype: float64
# 重新索引reindex
# .reindex将会根据索引重新排序而不是重写index,如果当前索引不存在,则引入缺失值
s=pd.Series(np.random.rand(3),index=list('abc'))
print(s)
s1=s.reindex(list('cbad'))
print(s1)
# .reindex(listofindex)中也是写列表
# 这里'd'索引不存在,所以值为NaN
s2=s.reindex(list('cbad'),fill_value ='666')
print(s2)
# fill_value参数:填充缺失值的值
a 0.015252
b 0.631593
c 0.795722
dtype: float64
c 0.795722
b 0.631593
a 0.015252
d NaN
dtype: float64
c 0.795722
b 0.631593
a 0.0152518
d 666
dtype: object
# Series对齐
# Series 和 ndarray 之间的主要区别是,Series 上的操作会根据标签自动对齐
# index顺序不会影响数值计算,以标签来计算!!!
# NaN空值和任何值计算结果扔为空值
s1=pd.Series(np.random.rand(3),index=list('abc'))
s2=pd.Series(np.random.rand(4),index=list('acbd'))
print(s1)
print(s2)
print(s1+s2)
a 0.277334
b 0.088585
c 0.551871
dtype: float64
a 0.222483
c 0.413765
b 0.457875
d 0.072471
dtype: float64
a 0.499817
b 0.546460
c 0.965637
d NaN
dtype: float64
# 删除:.drop
s=pd.Series(np.random.rand(5),index=list("abcde"))
print(s)
# 默认drop 删除元素之后返回副本(inplace=False)
s1=s.drop('a')
s2=s.drop(['a','b'],inplace=True)
print(s1)
print(s2)
print(s)
a 0.073533
b 0.141870
c 0.129170
d 0.714398
e 0.778901
dtype: float64
b 0.141870
c 0.129170
d 0.714398
e 0.778901
dtype: float64
None
c 0.129170
d 0.714398
e 0.778901
dtype: float64
# 添加
# 直接通过下标索引/标签index添加值
s = pd.Series(np.random.rand(5), index = list('ngjur'))
s['h']=2
print(s)
# 通过.append方法,直接添加一个数组
# .append方法生成一个新的数组,不改变之前的数组
#to_append即()内元素 : Series or list/tuple of Series
s3=s.append(s)
print(s3)
print(s1)
n 0.351741
g 0.209274
j 0.333868
u 0.515066
r 0.481014
h 2.000000
dtype: float64
n 0.351741
g 0.209274
j 0.333868
u 0.515066
r 0.481014
h 2.000000
n 0.351741
g 0.209274
j 0.333868
u 0.515066
r 0.481014
h 2.000000
dtype: float64
b 0.141870
c 0.129170
d 0.714398
e 0.778901
dtype: float64
# 修改
# 通过索引直接修改,类似序列
s=pd.Series(np.random.rand(3),index=['a','b','c'])
print(s)
s[0]=1
s['b']=2
print(s)
a 0.703114
b 0.998844
c 0.777766
dtype: float64
a 1.000000
b 2.000000
c 0.777766
dtype: float64


#作业answer
import pandas as pd
import numpy as np
#作业1
s1=pd.Series(range(10),index=list('abcdefghij'))
s1.drop(index='b',inplace=True)
s1[['a','e','f']]=[100,100,100]
print(s1)
#作业2
s1=pd.Series(np.random.rand(5)*10,index=list('abcde'))
s2=pd.Series(np.random.rand(5)*10,index=list('cdefg'))
print(s1+s2)
a 100
c 2
d 3
e 100
f 100
g 6
h 7
i 8
j 9
dtype: int64
a NaN
b NaN
c 2.104558
d 13.033831
e 17.870648
f NaN
g NaN
dtype: float64
'''
【课程2.5】 Pandas数据结构Dataframe:基本概念及创建
"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。
Dataframe中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。
'''
'\n【课程2.5】 Pandas数据结构Dataframe:基本概念及创建\n\n"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。\n\nDataframe中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。\n\n'
# Dataframe 数据结构
# Dataframe是一个表格型的数据结构,“带有标签的二维数组”。
# Dataframe带有index(行标签)和columns(列标签)
data={'name':['Jack','Tom','Mary'],
'age':[18,19,20],
'gender':['m','m','w']}
frame=pd.DataFrame(data)
print(frame)
print(type(frame))
print(frame.index,type(frame.index))
print(frame.columns,type(frame.columns))
print(frame.values,type(frame.values))
# 查看数据,数据类型为dataframe
# .index查看行标签,数据类型为index
# .columns查看列标签,数据 类型为index
# .values查看值,数据类型为ndarray
name age gender
0 Jack 18 m
1 Tom 19 m
2 Mary 20 w
RangeIndex(start=0, stop=3, step=1)
Index(['name', 'age', 'gender'], dtype='object')
[['Jack' 18 'm']
['Tom' 19 'm']
['Mary' 20 'w']]
#DataFrame有五大创建法
# Dataframe 创建方法一:由数组/list组成的字典
#dicoflist or dicofndarry
# 创建方法:pandas.Dataframe()
# 由数组/list组成的字典 创建Dataframe,columns为字典前面的key
#index为默认数字标签
# 字典的值的长度必须保持一致!
#即一数列一数列的添加
data1={'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]
}
data2={'one':np.random.rand(3),
'two':np.random.rand(3)
}
df1=pd.DataFrame(data1)
df2=pd.DataFrame(data2)
print(df1)
print(df2)
#列标签columns只可变size--类似reindex()!!!
# columns参数:可以重新指定列的顺序,格式为list,如果现有数据中没有该列(比如'd'),则产生NaN值
# 如果columns重新指定时候,列的数量可以少于原数据
df1=pd.DataFrame(data1,columns=['a','b','c','d'])
print(df1)
df1=pd.DataFrame(data1,columns=['one','c'])
print(df1)
#行标签index不可变size只可变内容类似于重写!!!
df2=pd.DataFrame(data2,index=['f1','f2','f3'])
print(df2)
# 这里如果尝试 index = ['f1','f2','f3','f4'] 会怎么样?
#报错
a b c
0 1 3 5
1 2 4 6
2 3 5 7
one two
0 0.994078 0.172028
1 0.935417 0.363636
2 0.956896 0.686517
a b c d
0 1 3 5 NaN
1 2 4 6 NaN
2 3 5 7 NaN
one c
0 NaN 5
1 NaN 6
2 NaN 7
one two
f1 0.994078 0.172028
f2 0.935417 0.363636
f3 0.956896 0.686517
# Dataframe 创建方法二:由Series组成的字典 dicofSeries
#同样是一列一列加
# 由Seris组成的字典 创建Dataframe,columns为字典key
#index为Series的标签(如果Series没有指定标签,则是默认数字标签)
# Series可以长度不一样,生成的Dataframe会出现NaN值!!!
#Series->DataFrame自动补全
# 没有设置index的Series
# 设置了index的Series
data1={'one':pd.Series(np.random.rand(2)),
'two':pd.Series(np.random.rand(3))
}
data2 = {'one':pd.Series(np.random.rand(2), index = ['a','b']),
'two':pd.Series(np.random.rand(3),index = ['a','b','c'])}
df1=pd.DataFrame(data1)
df2=pd.DataFrame(data2)
print(df1)
print(df2)
one two
0 0.348506 0.746226
1 0.614500 0.982886
2 NaN 0.296487
one two
a 0.801257 0.886317
b 0.263036 0.620650
c NaN 0.464100
# Dataframe 创建方法三:通过二维数组直接创建
ar = np.random.rand(9).reshape(3,3)
print(ar)
df1 = pd.DataFrame(ar)
df2 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three']) # 可以尝试一下index或columns长度不等于已有数组的情况
print(df1)
print(df2)
# 通过二维数组直接创建Dataframe,得到一样形状的结果数据
#如果不指定index和columns,两者均返回默认数字格式
# index和colunms指定长度与原数组保持一致
[[0.38480599 0.50341925 0.4640469 ]
[0.51968901 0.83803468 0.80929611]
[0.77316926 0.38704004 0.6013333 ]]
0 1 2
0 0.384806 0.503419 0.464047
1 0.519689 0.838035 0.809296
2 0.773169 0.387040 0.601333
one two three
a 0.384806 0.503419 0.464047
b 0.519689 0.838035 0.809296
c 0.773169 0.387040 0.601333
# Dataframe 创建方法四:由字典组成的列表listofdic
#一行一行添加
# 由字典组成的列表创建Dataframe,columns为字典的key,index不做指定则为默认数组标签
# colunms和index参数分别重新指定相应列及行标签
#和reindex使用规则相同
data=[{'a':1,'b':2},{'a':1,'b':2,'c':3}]
df1=pd.DataFrame(data)
#index相当于重写
df2=pd.DataFrame(data,index=['1st','2nd'])
#columns相当于reindex
df3 = pd.DataFrame(data, columns = ['1','2','3'])
print(df1)
print(df2)
print(df3)
a b c
0 1 2 NaN
1 1 2 3.0
a b c
1st 1 2 NaN
2nd 1 2 3.0
1 2 3
0 NaN NaN NaN
1 NaN NaN NaN
# Dataframe 创建方法五:由字典组成的字典 dicofdic
#外层key为colums
#内层key为index
#唯一一个给index的
data = {'Jack':{'math':90,'english':89,'art':78},
'Marry':{'math':82,'english':95,'art':92},
'Tom':{'math':78,'english':67}}
df1=pd.DataFrame(data)
print(df1)
#index和colums都相当于reindex
df2 = pd.DataFrame(data, columns = ['Jack','Tom','Bob'])
df3 = pd.DataFrame(data, index = ['a','b','c'])
print(df2)
print(df3)
Jack Marry Tom
art 78 92 NaN
english 89 95 67.0
math 90 82 78.0
Jack Tom Bob
art 78 NaN NaN
english 89 67.0 NaN
math 90 78.0 NaN
Jack Marry Tom
a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
#总结
#创建时候给什么 哪一个就相当于reindex(再次编制索引)
#eg
#一列一列给 dicoflist和dicofSeries都是先给列标签columns
#所以重新编制columns相当于reindex index相当于重写
#一行一行给listofdic先给columns
#columns reindex index 重写
#行列都给dicofdic
#唯一一个给index的
#两者都相当于reindex
#按照ndarry index和columns都没有给
#所以index 和 columns都相当于重写

#作业answer
import pandas as pd
import numpy as np
#法一 给列 dicoflist
lst1=np.random.randint(1,10,size=5)
lst2=np.random.randint(1,10,size=5)
lst3=np.random.randint(1,10,size=5)
lst4=np.random.randint(1,10,size=5)
dic={'four':lst1,'one':lst2,'three':lst3,'two':lst4}
df1=pd.DataFrame(dic,index=list('abcde'))
print(df1)
#法二 给列 dicofSeries
s1=pd.Series(data=lst1,index=list('abcde'))
s2=pd.Series(data=lst2,index=list('abcde'))
s3=pd.Series(data=lst3,index=list('abcde'))
s4=pd.Series(data=lst4,index=list('abcde'))
dic={'four':s1,'one':s2,'three':s3,'two':s4}
df2=pd.DataFrame(dic)
print(df2)
#法三 给行 listofdic
lst=[{'four':4,'one':1,"three":3,'two':2},
{'four':4,'one':1,"three":3,'two':2},
{'four':4,'one':1,"three":3,'two':2},
{'four':4,'one':1,"three":3,'two':2},
{'four':4,'one':1,"three":3,'two':2},
]
df3=pd.DataFrame(lst,index=list('abcde'))
print(df3)
#法4 都不给 二维ndarray
ar=np.array(np.random.randint(0,10,size=(5,4)))
df4=pd.DataFrame(ar,index=list('abcde'),columns=['four','one','three','one'])
print(df4)
#法5 都给 dicofdic 外层dic的key是columns
data = {'four':{'a':90,'b':89,'c':78,'d':5,'e':6},
'one':{'a':90,'b':89,'c':78,'d':5,'e':6},
'three':{'a':90,'b':89,'c':78,'d':5,'e':6},
'two':{'a':90,'b':89,'c':78,'d':5,'e':6}
}
df5=pd.DataFrame(data)
print(df5)
four one three two
a 9 7 4 3
b 9 8 9 4
c 8 9 5 8
d 6 5 5 4
e 2 6 9 7
four one three two
a 9 7 4 3
b 9 8 9 4
c 8 9 5 8
d 6 5 5 4
e 2 6 9 7
four one three two
a 4 1 3 2
b 4 1 3 2
c 4 1 3 2
d 4 1 3 2
e 4 1 3 2
four one three one
a 6 1 9 7
b 1 2 9 8
c 4 8 0 1
d 5 4 9 8
e 0 7 2 0
four one three two
a 90 90 90 90
b 89 89 89 89
c 78 78 78 78
d 5 5 5 5
e 6 6 6 6
'''
【课程2.6】 Pandas数据结构Dataframe:索引
Dataframe既有行索引也有列索引,可以被看做由Series组成的字典(共用一个索引)
选择列 / 选择行 / 切片 / 布尔判断
'''
'\n【课程2.6】 Pandas数据结构Dataframe:索引\n\nDataframe既有行索引也有列索引,可以被看做由Series组成的字典(共用一个索引)\n\n选择列 / 选择行 / 切片 / 布尔判断\n\n'
# 总说选择行与列
df=pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index=['one','two','three'],
columns=['a','b','c','d'])
print(df)
print('-----------')
# 按照列名选择列
#只选择一列输出Series
#选择多列输出Dataframe
data1=df['a']
data2=df[['a','c']]
print(data1,type(data1))
print(data2,type(data2))
print('-----------')
# 按照行名选择行
#只选择一行输出Series
#选择多行输出Dataframe
data3=df.loc['one']
data4=df.loc[['one','two']]
print(data3,type(data3))
print(data4,type(data4))
a b c d
one 60.066766 20.982593 70.080973 90.991952
two 98.299697 24.508627 47.991541 5.859387
three 61.839048 1.857317 36.815257 42.187342
-----------
one 60.066766
two 98.299697
three 61.839048
Name: a, dtype: float64
a c
one 60.066766 70.080973
two 98.299697 47.991541
three 61.839048 36.815257
-----------
a 60.066766
b 20.982593
c 70.080973
d 90.991952
Name: one, dtype: float64
a b c d
one 60.066766 20.982593 70.080973 90.991952
two 98.299697 24.508627 47.991541 5.859387
#细说选择行
#df【列名】用【列名】索引选择列, 也可以选择行(不常用)
df = pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index = ['one','two','three'],
columns = ['a','b','c','d'])
print(df)
print('-----')
# df[]默认选择列,[]中写列名(所以一般数据colunms都会单独制定,不会用默认数字列名,以免和index冲突)
# 单选列为Series,print结果为Series格式
# 多选列为Dataframe,print结果为Dataframe格式
data1=df['a']
data2=df[['b','c']]
print(data1)
print(data2)
#非重点 不常用法
data3 = df[:1]
#data3 = df[0]
#data3 = df['one']
print(data3,type(data3))
# df[]中为数字时,默认选择行,且只能进行切片的选择,不能单独选择(df[0])
# 输出结果为Dataframe,即便只选择一行
# df[]不能通过索引标签名来选择行(df['one'])
a b c d
one 66.689951 70.917802 43.959189 39.889119
two 47.674709 56.190896 5.577672 46.224369
three 3.090913 76.460138 77.731091 80.235150
-----
one 66.689951
two 47.674709
three 3.090913
Name: a, dtype: float64
b c
one 70.917802 43.959189
two 56.190896 5.577672
three 76.460138 77.731091
a b c d
one 66.689951 70.917802 43.959189 39.889119
#细说选择行
#df.loc[label]
#1针对[行名]选择行
#2如果没有行名 可以针对默认数字选择行
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
print(df2)
print('-----')
data1=df1.loc['one']
data2=df2.loc[1]
print(data1)
print(data2)
print('单标签索引\n-----')
# 单个标签索引,返回Series
data3 = df1.loc[['two','three','five']]
data4 = df2.loc[[3,2,1]]
print(data3)
print(data4)
print('多标签索引\n-----')
# 多个标签索引,如果标签不存在,则返回NaN
# 顺序可变
data5 = df1.loc['one':'three']
data6 = df2.loc[1:3]
print(data5)
print(data6)
print('切片索引')
# 可以做切片对象
# 末端包含!!!用loc做切片末端包含
a b c d
one 8.090184 19.719044 0.671359 17.083233
two 52.571118 65.232782 26.267374 17.837930
three 57.849170 84.111119 72.354688 80.931790
four 65.700928 4.628123 69.963978 18.142123
a b c d
0 88.288394 46.433168 70.374551 58.077134
1 29.609704 93.034972 58.228832 29.418921
2 80.638641 51.854000 10.016064 54.724819
3 31.633185 90.085637 35.456804 79.061184
-----
a 8.090184
b 19.719044
c 0.671359
d 17.083233
Name: one, dtype: float64
a 29.609704
b 93.034972
c 58.228832
d 29.418921
Name: 1, dtype: float64
单标签索引
-----
a b c d
two 52.571118 65.232782 26.267374 17.83793
three 57.849170 84.111119 72.354688 80.93179
five NaN NaN NaN NaN
a b c d
3 31.633185 90.085637 35.456804 79.061184
2 80.638641 51.854000 10.016064 54.724819
1 29.609704 93.034972 58.228832 29.418921
多标签索引
-----
a b c d
one 8.090184 19.719044 0.671359 17.083233
two 52.571118 65.232782 26.267374 17.837930
three 57.849170 84.111119 72.354688 80.931790
a b c d
1 29.609704 93.034972 58.228832 29.418921
2 80.638641 51.854000 10.016064 54.724819
3 31.633185 90.085637 35.456804 79.061184
切片索引
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:22: FutureWarning:
Passing list-likes to .loc or [] with any missing label will raise
KeyError in the future, you can use .reindex() as an alternative.
See the documentation here:
https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike
# df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
# 类似list的索引,其顺序就是dataframe的整数位置,从0开始计
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
print(df.iloc[0])
print(df.iloc[-1])
#print(df.iloc[4])
print('单位置索引\n-----')
# 单位置索引
# 和loc索引不同,不能索引超出数据行数的整数位置
print(df.iloc[[0,2]])
print(df.iloc[[3,2,1]])
print('多位置索引\n-----')
# 多位置索引
# 顺序可变
print(df.iloc[1:3])
print(df.iloc[::2])
print('切片索引')
# 切片索引
# 末端不包含!!!按照数字切片一般都末端不包含
a b c d
one 63.865808 67.918670 79.147570 96.612447
two 44.578604 52.973829 93.495585 57.698461
three 89.960372 75.657540 85.973381 85.055974
four 77.390780 75.258005 47.897852 11.303472
------
a 63.865808
b 67.918670
c 79.147570
d 96.612447
Name: one, dtype: float64
a 77.390780
b 75.258005
c 47.897852
d 11.303472
Name: four, dtype: float64
单位置索引
-----
a b c d
one 63.865808 67.91867 79.147570 96.612447
three 89.960372 75.65754 85.973381 85.055974
a b c d
four 77.390780 75.258005 47.897852 11.303472
three 89.960372 75.657540 85.973381 85.055974
two 44.578604 52.973829 93.495585 57.698461
多位置索引
-----
a b c d
two 44.578604 52.973829 93.495585 57.698461
three 89.960372 75.657540 85.973381 85.055974
a b c d
one 63.865808 67.91867 79.147570 96.612447
three 89.960372 75.65754 85.973381 85.055974
切片索引
# 布尔型索引
# 和Series原理相同
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
b1=df<20
print(b1,type(b1))
print(df[b1])# 也可以书写为 df[df < 20]
print('------')
# 全部DataFrame做判断矩阵
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b2 = df['a'] > 50
print(b2,type(b2))
print(df[b2]) # 也可以书写为 df[df['a'] > 50]
print('------')
# 单列做判断矩阵
# 索引结果保留 单列判断为True的行数据 其他列不显示
b3 = df[['a','b']] > 50
print(b3,type(b3))
print(df[b3]) # 也可以书写为 df[df[['a','b']] > 50]
print('------')
# 多列做判断矩阵
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
# 判断矩阵中不含有的元素返回NaN
b4 = df.loc[['one','three']] < 50
print(b4,type(b4))
print(df[b4]) # 也可以书写为 df[df.loc[['one','three']] < 50]
print('------')
# 多行做判断矩阵
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
# 判断矩阵中不含有的元素返回NaN
a b c d
one 53.165072 72.137349 49.335356 94.371570
two 31.833981 18.591801 46.263265 97.524672
three 43.453369 89.621918 39.201420 18.235790
four 92.772641 12.172163 52.007352 42.280553
------
a b c d
one False False False False
two False True False False
three False False False True
four False True False False
a b c d
one NaN NaN NaN NaN
two NaN 18.591801 NaN NaN
three NaN NaN NaN 18.23579
four NaN 12.172163 NaN NaN
------
one True
two False
three False
four True
Name: a, dtype: bool
a b c d
one 53.165072 72.137349 49.335356 94.371570
four 92.772641 12.172163 52.007352 42.280553
------
a b
one True True
two False False
three False True
four True False
a b c d
one 53.165072 72.137349 NaN NaN
two NaN NaN NaN NaN
three NaN 89.621918 NaN NaN
four 92.772641 NaN NaN NaN
------
a b c d
one False False True False
three True False True True
a b c d
one NaN NaN 49.335356 NaN
two NaN NaN NaN NaN
three 43.453369 NaN 39.201420 18.23579
four NaN NaN NaN NaN
------
# 多重索引:比如同时索引行和列
# 先选择列再选择行 —— 相当于对于一个数据,先筛选字段,再选择数据值
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
print(df['a'].loc)
print('------')
print(df['a'].loc[['one','three']]) # 选择a列(属性)的one,three行(个体数据值)
print(df.loc[['one','three']]['a'])
print('------')
print(df[['b','c','d']].loc[['one','three']]) # 选择b,c,d列(属性)的one,three行(个体数据值)
print(df[df['a']<50].iloc[:2])# 选择满足判断条件(属性a<50)的前两行数据
a b c d
one 38.359537 40.536516 50.215082 24.690263
two 18.713505 74.621177 20.050490 47.546497
three 11.369268 65.753554 54.547829 7.002664
four 5.435595 48.839504 98.276157 21.352956
------
------
one 38.359537
three 11.369268
Name: a, dtype: float64
one 38.359537
three 11.369268
Name: a, dtype: float64
------
b c d
one 40.536516 50.215082 24.690263
three 65.753554 54.547829 7.002664
a b c d
one 38.359537 40.536516 50.215082 24.690263
two 18.713505 74.621177 20.050490 47.546497
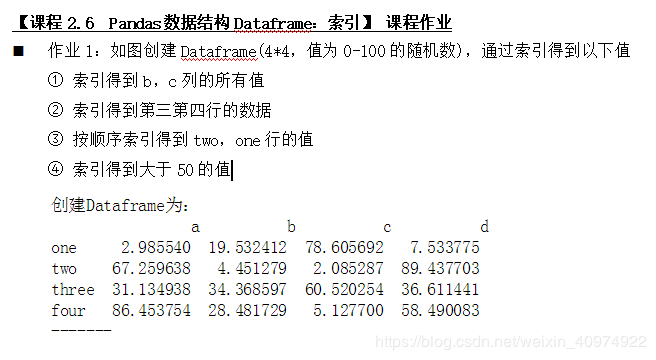
#作业answer
df=pd.DataFrame(np.random.rand(4,4)*100,
index=['one','two','three','four'],
columns=[list('abcd')])
print(df)
print('------')
print(df[['b','c']])
print('------')
print(df.loc[['three','four']])
print('------')
print(df.iloc[[1,0]])
print('------')
print(df[df>50])
a b c d
one 11.775827 98.052886 2.618347 53.166143
two 48.787931 31.037028 14.595130 72.661248
three 24.311761 4.930614 60.633819 69.031862
four 33.716489 37.270337 55.445232 92.749330
------
b c
one 98.052886 2.618347
two 31.037028 14.595130
three 4.930614 60.633819
four 37.270337 55.445232
------
a b c d
three 24.311761 4.930614 60.633819 69.031862
four 33.716489 37.270337 55.445232 92.749330
------
a b c d
two 48.787931 31.037028 14.595130 72.661248
one 11.775827 98.052886 2.618347 53.166143
------
a b c d
one NaN 98.052886 NaN 53.166143
two NaN NaN NaN 72.661248
three NaN NaN 60.633819 69.031862
four NaN NaN 55.445232 92.749330
'''
【课程2.7】 Pandas数据结构Dataframe:基本技巧
数据查看、转置 / 添加、修改、删除值 / 对齐 / 排序
'''
'\n【课程2.7】 Pandas数据结构Dataframe:基本技巧\n\n数据查看、转置 / 添加、修改、删除值 / 对齐 / 排序\n\n'
# 数据查看、转置
df = pd.DataFrame(np.random.rand(16).reshape(8,2)*100,
columns = ['a','b'])
print(df.head(2))
print(df.tail())
# .head()查看头部2条数据
# .tail()查看尾部5条数据
# 默认查看5条
print(df.T)
# .T 转置
a b
0 67.123579 78.540599
1 16.668997 11.536215
a b
3 19.796982 7.295293
4 26.793664 95.924559
5 22.213018 60.779001
6 3.675648 38.955255
7 60.925783 64.103140
0 1 2 3 4 5 \
a 67.123579 16.668997 41.758860 19.796982 26.793664 22.213018
b 78.540599 11.536215 59.150321 7.295293 95.924559 60.779001
6 7
a 3.675648 60.925783
b 38.955255 64.103140
# 添加与修改
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df)
# 新增列/行并赋值直接【】or loc【】
df['e']=10
df.loc[4]=20
# 索引后直接修改值
df[['a','c']]=100
df['b'].loc[0]=666
print(df)
a b c d
0 85.971229 27.821810 77.466322 87.766945
1 41.422117 85.382627 37.848980 22.375692
2 18.105688 33.636029 10.040581 30.562783
3 50.128665 10.891343 56.333581 33.924682
a b c d e
0 100 666.000000 100 87.766945 10
1 100 85.382627 100 22.375692 10
2 100 33.636029 100 30.562783 10
3 100 10.891343 100 33.924682 10
4 100 20.000000 100 20.000000 20
# 删除 del / drop()
#del只能删列 drop可以删行或列
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df)
print('-----')
del df['a']
print(df)
print('-----')
# del语句 - 删除列
print(df.drop(0))
print(df.drop([1,2]))
print(df)
print('-----')
# drop()删除行,inplace=False → 删除后生成新的数据,不改变原数据
print(df.drop(['d'], axis = 1))
print(df)
# drop()删除列,需要加上axis = 1,inplace=False → 删除后生成新的数据,不改变原数据
a b c d
0 52.376431 98.951314 3.665786 90.532788
1 72.710362 60.761235 10.310778 20.850619
2 41.186250 48.993426 68.769189 72.845749
3 2.091445 77.853150 1.332935 1.946453
-----
b c d
0 98.951314 3.665786 90.532788
1 60.761235 10.310778 20.850619
2 48.993426 68.769189 72.845749
3 77.853150 1.332935 1.946453
-----
b c d
1 60.761235 10.310778 20.850619
2 48.993426 68.769189 72.845749
3 77.853150 1.332935 1.946453
b c d
0 98.951314 3.665786 90.532788
3 77.853150 1.332935 1.946453
b c d
0 98.951314 3.665786 90.532788
1 60.761235 10.310778 20.850619
2 48.993426 68.769189 72.845749
3 77.853150 1.332935 1.946453
-----
b c
0 98.951314 3.665786
1 60.761235 10.310778
2 48.993426 68.769189
3 77.853150 1.332935
b c d
0 98.951314 3.665786 90.532788
1 60.761235 10.310778 20.850619
2 48.993426 68.769189 72.845749
3 77.853150 1.332935 1.946453
df1=pd.DataFrame(np.random.rand(10,4),columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.random.randn(7, 3), columns=['A', 'B', 'C'])
print(df1)
print(df2)
print(df1+df2)
#按照行的index对齐自动相加,如果出现不存在的元素则加的结构也是NaN
A B C D
0 0.116265 0.286147 0.509417 0.123862
1 0.591067 0.220565 0.893078 0.995741
2 0.160296 0.327076 0.372967 0.740136
3 0.444086 0.254079 0.056255 0.721923
4 0.059144 0.665892 0.504307 0.746240
5 0.909397 0.426231 0.685564 0.056044
6 0.442812 0.477964 0.208796 0.830122
7 0.573963 0.196914 0.294245 0.073122
8 0.484215 0.885544 0.493887 0.768655
9 0.450795 0.552202 0.750659 0.006042
A B C
0 1.862325 0.285321 0.505303
1 -0.664007 1.091699 -1.074902
2 -0.932387 -0.062655 0.307506
3 -2.796463 -1.310375 -1.439840
4 -0.364978 -0.376336 0.711008
5 0.705022 -1.029143 1.118433
6 -0.255299 2.005879 -0.419431
A B C D
0 1.978590 0.571468 1.014720 NaN
1 -0.072939 1.312263 -0.181824 NaN
2 -0.772091 0.264421 0.680473 NaN
3 -2.352377 -1.056296 -1.383586 NaN
4 -0.305834 0.289556 1.215315 NaN
5 1.614419 -0.602912 1.803996 NaN
6 0.187513 2.483843 -0.210635 NaN
7 NaN NaN NaN NaN
8 NaN NaN NaN NaN
9 NaN NaN NaN NaN
# 排序1 - 按值排序 .sort_values 按照某个属性(列)的值进行排序
# 同样适用于Series
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
# 单列排序
# ascending参数:设置升序降序,默认升序
print(df1.sort_values(by=['a'],ascending=True))# 升序
print(df1.sort_values(['a'], ascending = False)) # 降序
print('------')
# 多列排序
df2 = pd.DataFrame({'a':[1,1,1,1,2,2,2,2],
'b':list(range(8)),
'c':list(range(8,0,-1))})
print(df2)
print(df2.sort_values(['a','c']))
# 多列排序,先排'a',在拍好'a'的基础上再拍'c'有点像基数排序的感觉
a b c d
0 9.198370 45.091469 40.676043 74.669533
1 85.051633 98.125841 73.817642 72.571482
2 75.304951 55.935442 70.350217 4.555149
3 38.234080 62.093133 32.545653 0.724567
a b c d
0 9.198370 45.091469 40.676043 74.669533
3 38.234080 62.093133 32.545653 0.724567
2 75.304951 55.935442 70.350217 4.555149
1 85.051633 98.125841 73.817642 72.571482
a b c d
1 85.051633 98.125841 73.817642 72.571482
2 75.304951 55.935442 70.350217 4.555149
3 38.234080 62.093133 32.545653 0.724567
0 9.198370 45.091469 40.676043 74.669533
------
a b c
0 1 0 8
1 1 1 7
2 1 2 6
3 1 3 5
4 2 4 4
5 2 5 3
6 2 6 2
7 2 7 1
a b c
3 1 3 5
2 1 2 6
1 1 1 7
0 1 0 8
7 2 7 1
6 2 6 2
5 2 5 3
4 2 4 4
# 排序2 - 索引排序 .sort_index
# 按照行index排序
# 默认 ascending=True, inplace=False
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = [5,4,3,2],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['h','s','x','g'],
columns = ['a','b','c','d'])
print(df1)
print(df1.sort_index())
print(df2)
print(df2.sort_index())
a b c d
5 84.095499 13.313575 99.483003 52.785404
4 31.363606 82.146044 48.645785 61.034812
3 42.635269 70.476056 65.823774 52.421584
2 42.028122 46.937515 92.741171 90.049750
a b c d
2 42.028122 46.937515 92.741171 90.049750
3 42.635269 70.476056 65.823774 52.421584
4 31.363606 82.146044 48.645785 61.034812
5 84.095499 13.313575 99.483003 52.785404
a b c d
h 69.897356 83.189551 67.665089 43.221810
s 32.360179 1.464245 54.805584 48.618503
x 59.188794 72.810460 51.521598 27.956133
g 21.787669 17.587755 65.334653 66.057178
a b c d
g 21.787669 17.587755 65.334653 66.057178
h 69.897356 83.189551 67.665089 43.221810
s 32.360179 1.464245 54.805584 48.618503
x 59.188794 72.810460 51.521598 27.956133

#作业answer
#作业1
df1=pd.DataFrame(np.random.rand(3,3)*100,index=list('abc'),columns=['v1','v2','v3'])
print(df1.sort_index(ascending=False))
print('------')
print(df1.sort_values(by=['v2'],ascending=False))
print('------')
#作业2
df1=pd.DataFrame(np.random.rand(5,2)*100,index=list('abcde'),columns=['v1','v2'])
df2=df1.T
df2.drop(['e'],axis=1)
v1 v2 v3
c 71.187723 52.861998 59.219050
b 54.618639 38.720337 94.535586
a 77.624794 53.408849 69.616503
------
v1 v2 v3
a 77.624794 53.408849 69.616503
c 71.187723 52.861998 59.219050
b 54.618639 38.720337 94.535586
------
| a | b | c | d | |
|---|---|---|---|---|
| v1 | 11.507745 | 14.183001 | 51.572311 | 62.421454 |
| v2 | 33.023802 | 62.028549 | 12.476100 | 1.098652 |