社交网络分析与反欺诈
一、总体概述
目前针对图网络结构,比较热门的一个部分就是知识图谱,知识图谱是基于二元关系知识库,构成网络结构,基本组成单位是”实体-关系-实体“的三元组,实体之间通过关系相互联结。
主要可以应用的场景有:风险预测、反欺诈、精准营销、智能搜索等
常用的是采用个人信息进行一个场景构建,构建知识图谱的流程例子如下所示:
1、通过对数据进行清理,抽取,构建知识图谱的节点,比如:姓名、ip、联系方式、手机号、工作地点、GPS等
2、构建基础信息表,然后不断更新,可以保证数据的一致性
3、基于清洗后的信息,进入图数据库,构建整个知识图谱
4、基于图算法进行相关的特征抽取或者通过网络结构进行负样本挖掘
说到节点的信息,例如一个人为节点,那这个人其它的属性也可以称为这个人的特征,通常某个节点还会提及设备指纹。
设备指纹:可以把手机设备理解成一个人,像人一样有身份证号和名字(设备序列号),适用于唯一标识出该设备的设备特征或者独特的设备标识。一般都是某些设备信息,通过一些设备指纹算法将这些信息组合起来,通过特定的hash算法得到一个最后的ID值,作为该设备的唯一标识码。常见的元素有:Wifi信息;浏览器本身信息,包括UA、版本、操作系统;操作系统的特征,是否越狱等
主动式的设备指纹:一般是指需要在客户端上植入自己的SDK代码,主动的收集设备相关的特征,用以表示设备和用户。一般理想的特征应该是一段时间内不会随着外界的条件变化或者用户的不同操作行为而发生变化,同时在不同的设备上具有显著的差异。现在这种主动式的设备指纹比较常见,例如很多toB的公式,在toC的公司获取数据就是通过SDK的方式或者可以说很多公司有一些事情需要外部的第三方公司的服务,那么这些公司上报自己的数据就是通过第三方的SDK代码的方式上报。
目前比较基础的反欺诈手段做法就是通过经验定义一些规则,制定规则通常会漏掉一些用户、导致一些误判也可能会导致用户流失。
二、图的基本概念
1、节点和边
社交网络,就是表现人与人之间关系的网络。社交网络分析算法,就是为了研究节点(可以理解为人)和节点关系(边,可以理解为人和人之间的关系)的算法。通过对关系的研究,可以对节点关系做梳理,从而聚成团。

2、有向图和无向图
无向图仅表示节点和节点之间是否有关系,例如:在P2P行业反欺诈建模中,通过申请者通讯录获取其社会关系,例如:如果王五和张三的通讯录都有问题用户李四,那么王五和张三问题的风险比较高。
有向图会携带方向信息,最简单的例子就是传销图。传销有比较成熟的上下线制度,是发展团队十分迅速有效的手法,也被互联网公司比较多的用户发展用户-好友邀请制度。如果产生危害的话,对互联网公司,产生的后果就是大规模虚假注册。
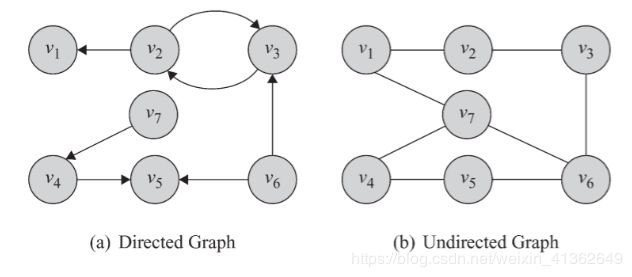
3、节点和度数
度就是从这个节点发散出去了多少条边,或者可以理解为你又多少个朋友。

缺点:没有考虑邻接节点的重要性
4、社区(Community):非重叠社区、重叠社区
社区可以理解成无监督学习中的群组,也就是同一社区中节点和节点关系紧密,而社区和社区之间关系稀疏。
如果任意两个社区的节点集合的交集为空则被称为非重叠社区,否则称为重叠社区。
5、派系(Clique),完全子图
派系是指任意两个点都相连的节点的集合,又称为完全子图。
6、度中心性
每个节点都标注上其度的值大小,如下所示:

接下来做标准化处理,用度除以最大连接可能(N-1),则得到:

可以说明的是中心性越高,表示与你有联系的人越多,或者说你的社交任务影响力越大,这是一个社交网站分析用户行为时一个常用的指标。
7、集中度(Centrality)
集中度表示一个群体的紧密程度或者可以理解成密度。集中度又可以分为度集中度、紧密集中度和介数集中度,还有图集中度、特征向量集中度。
度集中度(Degree centrality)
度集中度的方式有很多,例如:基尼系数、标准差以及Freeman集中度公式。以Freeman集中度公式为例:
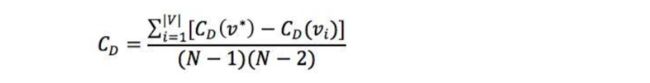
其中,V*表示度最大的节点,根据上述公式计算如下两图的度集中度:

紧密集中度(Closeness centrality)

直观理解依赖于从一个节点出发到其它所有节点的最短路径长度,并定义为总长度的倒数。节点i的紧密中心如下所示:
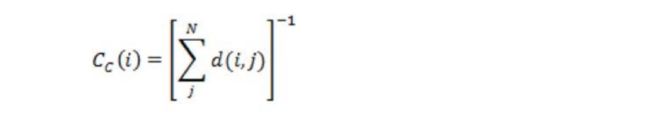
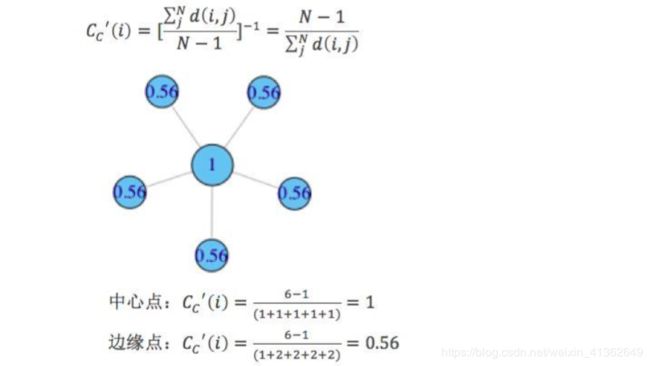
而通常我们讲紧密中心度,是指其标准化形式,也即总距离长除以(N-1)

介数集中度(betweenness centrality)

直观理解,介数就是多少个节点对必须经过本节点实现最小跳数互达到。定义如下:
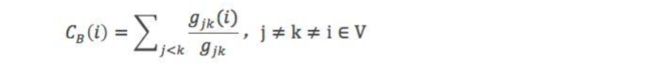
其中,gjk表示节点jk最短路径的个数,gjk(i)表示i位于最短路径的个数。将其标准化,除以除本节点外其它节点对个数,得到:
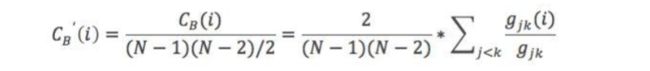
以下面两个图作为示例来计算介数集中度:
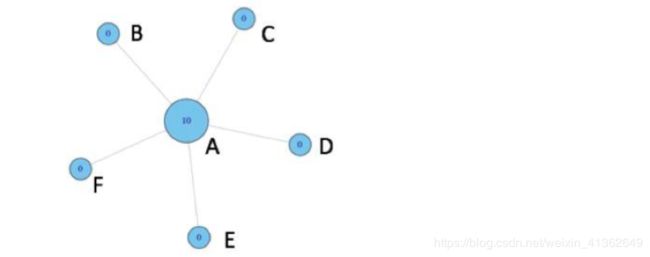
A在 (B,C),(B,D),(B,E),(B,F),(C,D),(C,E),(C,F),(D,E),(D,F),(E,F)十个节点对的最短路径上,非标准化值为10
BCDEF不在任何节点对的最短路径上,所以非标准化值为0

对于节点A和E,都不在任何节点对的最短路径上,所以为0;对于节点B,在(A,C),(A,D),(A,E)三个节点对最短路径上,非标准化值为3。类似节点D和B情况也为3;对于节点C,在(A,D),(A,E),(B,D),(B,E)四个节点对最短路径上,非标准化值为4.
特征向量集中度(Eigenvector)
主要思想:影响作用比较大的人不仅仅朋友多,而且他的朋友也是重要的

上述的方法在无向图上表现较好,但是在有向图上,可能存在某些节点eigenvector centrality变为0

为此,一个大佬Katz提出一个改进的办法,即每个节点初始就有一个centrality值,如下所示:

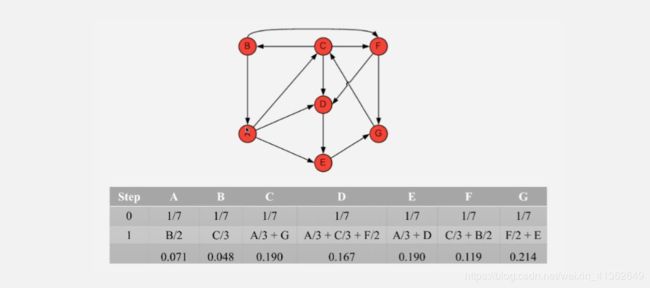
8、Pagerank
PageRank算法是针对上述算法”每条出边都会带上起始完整的中心值,不太合理“基础上,进行改进,假设一个节点的出度是n,每条出边附上1/n的起始节点的中心度量值。如下所示:
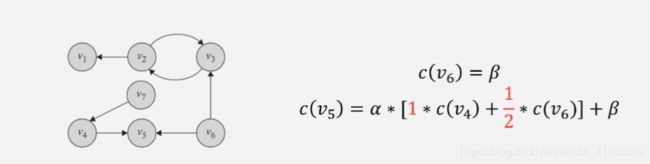

9、传递性 Transitivity

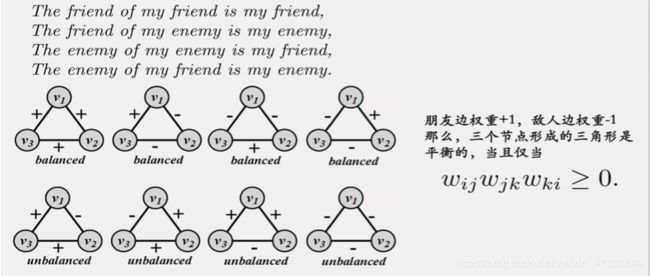
10、结构平衡理论
11、网络相似性
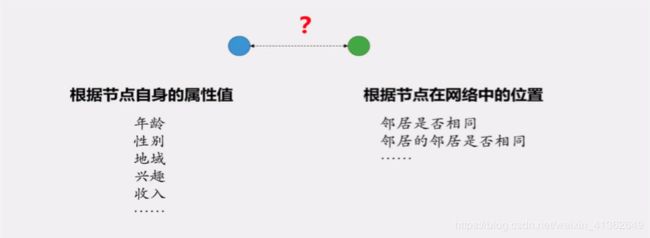
12、结构等价性

13、归一化

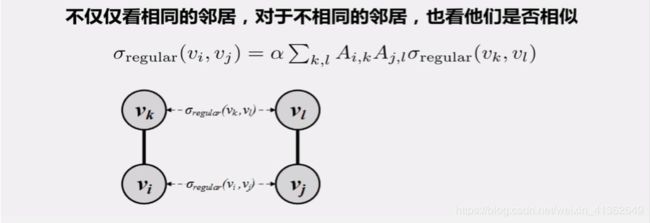
14、Regular Equivalence


三、社区发现算法
社区发现算法的思路就是在复杂网络中发现连接紧密的节点簇(社区结构),与聚类的思路如出一辙。发现这些社区结构的方式有很多,常见的算法有GN算法、Louvain算法、LPA算法和SLPA算法。
1、GN(Girvan-Newman)算法
GN算法是一个最经典的社区发现算法,属于分裂的层次聚类算法(自上而下)。GN算法的基本思想是不断删除网络中具有相对于所有源节点的最大边介数的边,然后,再重新计算网络中剩余的边的相对于所有源节点的边介数。重复这个过程,直到网络中所有的边都被删除。简单理解通过介数的定义我们知道,介数是多少个节点对必须经过本节点实现最小跳数互达的值,而介数高的边必然要比介数低的边更可能是社区之间的边(两个社区中的节点之间的最短路径都要经过那些社区之间的边,所以他们的介数会很高)。方便理解,可以参看下图,方块节点和圆形节点的最短路径,必然经过边AB,因此边AB的介数最大,拆除这条边,就可以将其拆分成两个团体或者称之为两个社区。

然而,虽然GN算法的准确率很高,但是计算量大,时间复杂度也很高。
2、Louvain算法
Louvain可以理解为GN的逆过程,GN的思路是不断拆边,类似于自上而下的层次聚类。而Louvain则是不断凝聚,类似于自下而上的层次聚类。理解Louvain算法的过程,需要了解一个社区评价指标-模块度。
模块度(Modularity)用来衡量一个社区的划分是不是相对比较好的结果。一个相对好的结果在社区内部的节点相似度较高,而在社区外部节点的相似度较低。
设Avw为网络的邻接矩阵的一个元素,定义为:

假设cv和cw分别表示点v和点w所在的两个社区,社区内部的边数和网络中总边数的比例:

函数sigmod(cv,cw)的取值定义为:如果v和w在一个社区,即cv=cw,则为1,否则为0,m为网络中边的总数。
模块度的大小定义为社区内部的总边数和网络中总边数的比例减去一个期望值,该期望值是将网络设定为随机网络时同样的社区分配所形成的社区内部的总边数和网络中总边数的比例的大小,于是模块度Q为:
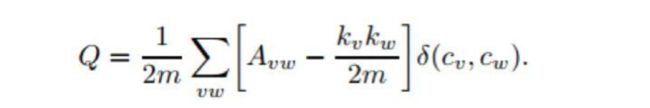
其中kv表示点v的度。

在进行每次划分的时候计算Q值,Q取值最大的时候则是此网络较理想的划分。Q值的范围在0-1之间,Q值越大网络划分的社区结构准确度越高,在实际的网络中,Q值的最高点一般出现在0.3-0.7之间。
Louvain算法,首先是把每一个节点当做独立的社区,假如我们把v1和v2加入i都会使其模块度增加,比较两者的数值,选择增量比较大的一个加入到i社区中。如此这般反复迭代,直到模块度Q的值不再增加为止。
3、LPA(Label Propagation Algorithm)
LPA算法的稳定性不是很好,但是可扩展性强,时间复杂度接近线性,且可以控制迭代次数来划分节点类别,不需要预先给定社区数量,适合处理大规模复杂网络。LPA的计算步骤如下所示:
1). 为所有节点指定一个唯一标签
2). 刷新标签:对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点(如果最多的标签不唯一,随机选择一个)
3). 重复步骤二,直到收敛为止。
4、SLPA(Speaker-listener Label Propagation Algorithm)
SLPA是一种改进的LPA,是一种重叠社区发现算法,其中涉及一个重要的阈值参数r。通过对r的适当选取,可将其退化为非重叠型。
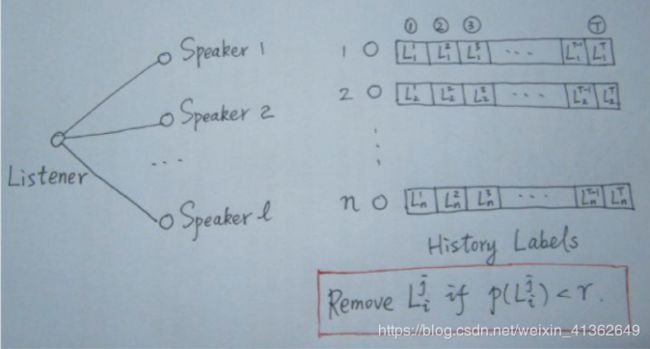
SLPA中引入了listerner和speaker两个比较形象的概念。可以理解为:在刷新节点的过程中,我们将要被刷新的节点定义为listener,其临近节点就是它的speaker,speaker通常不止一个,在众多speaker时,listener应该听那个speaker时,需要制定一个规则。
在LPA中,我们以出现次数最多的标签来做决断,这是一种规则,通常在SLPA框架里,规则的选取方式多由用户指定(通常结合业务逻辑和场景决定)。
与LPA相比,SLPA最大的特点在于他不是仅仅的刷新替代原标签,而是记录每一个节点在刷新迭代过程中的历史标签序列(例如迭代T时,则每一个节点将保留一个长度为T的序列)。当迭代停止时,对每一个节点历史标签序列中各标签出现的频率做统计,按照某一个给定的阈值过滤掉那些出现概率小的标签,剩下的标签为该节点的标签。
不同社区发现算法以及复杂度如下所示:

四、社区网络算法一些应用
特征抽取:不一致性检验、静态分析、动态分析、关联特征提取
不一致性检验: 在团簇中,如果用户的信息与我们的正常理解有严重偏差,那么这种团簇很可疑;如两个用户拥有同个家庭wifi,但所填家庭地址相差甚远,显然与现实不符。这里需要大量的人工干预,因为我们不能通过欺诈标签做相关的统计分析,更多的要靠经验判断。当然如果标签得当,我们其实可以通过做相似性度量来进行筛选重要的关联特征,作为规则。
关联特征提取: 对网络特征的直接提取,提取出中心度或一度二度关联特征可供上层规则系统或风险评估模型使用。基本思想仍然是在网络中社交越广泛,越有可能是一个坏人。
静态分析:给定时间节点,去尝试发现图形结构的异常子图。
动态分析:分析结构图网络随着时间变化的趋势。
失联模型:挖掘更多的潜在的可触达联系人。
网络信息挖掘 : 社区发现
反欺诈对于实时决策的需求很高,这些指标都需要实时提取。其中一些指标,比如二度关联度, 在一般的情况下计算复杂度是很高的。在动态图的情形下,一般会采取一些近似的算法并进行预计算。
负样本生成:染色
染色本质就是一种基于关联图谱的半监督学习方法,我们知道在反欺诈的场景下,一个典型的困境就是欺诈标注非常少,获得的代价非常高,而我们要做一些监督式的机器学习,却又非常依赖于标注。因此如果能用少量的欺诈标注样本产生出更多的标注,就能最大程度利用欺诈样本。这就是染色的初衷,欺诈标注会沿着网络里的边从一个节点传播到另一个节点。
染色从直觉上比较容易理解,我们经常说近朱者赤,近墨者黑。一个用户和坏用户有关联,其实很有可能他本身就是有问题的。这里放一个数据,根据分析得到,一个客户一旦出现在某个坏客户的通讯录中,就有70%的概率会变坏。
五、相关部分代码
import networkx as nx
import pandas as pd
import matplotlib.pyplot as plt
edge_list=pd.read_csv('./data/stack_network_links.csv')
edge_list.head() 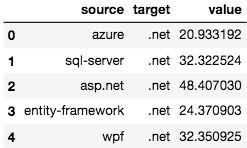
G=nx.from_pandas_edgelist(edge_list,edge_attr='value' )
plt.figure(figsize=(30,15))
nx.draw(G,with_labels=True,
edge_color='blue',
node_color='grey',
node_size=10,
pos=nx.spring_layout(G,k=0.1,iterations=40))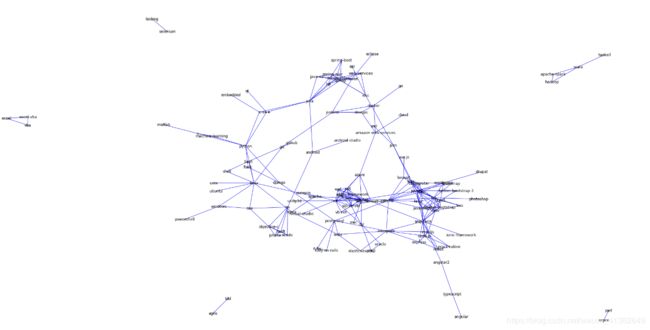
标签传播的两种实现方法:sklearn和networkx
/********基于sklearn的标签算法********/
import numpy as np
import matplotlib.pyplot as plt
from sklearn.semi_supervised import label_propagation
from sklearn.datasets import make_circles
n_samples = 200
X, y = make_circles(n_samples=n_samples, shuffle=False)
# 定义标签第一个位置为0,最后一个位置为1,其它位置为无标签-1
outer, inner = 0, 1
labels = np.full(n_samples, -1.)
labels[0] = outer
labels[-1] = inner
# 调用标签传播算法,构建模型
label_spread = label_propagation.LabelSpreading(kernel='rbf', alpha=0.8)
label_spread.fit(X, labels)
# 标签传播,可视化表示
output_labels = label_spread.transduction_
plt.figure(figsize=(8.5, 4))
plt.subplot(1, 2, 1)
plt.scatter(X[labels == outer, 0], X[labels == outer, 1], color='navy',marker='s', lw=0, label="outer labeled", s=10)
plt.scatter(X[labels == inner, 0], X[labels == inner, 1], color='c',marker='s', lw=0, label='inner labeled', s=10)
plt.scatter(X[labels == -1, 0], X[labels == -1, 1], color='darkorange',marker='.', label='unlabeled')
plt.legend(scatterpoints=1, shadow=False, loc='upper right')
plt.title("Raw data (2 classes=outer and inner)")

# 标签完的可视化表示
plt.subplot(1, 2, 2)
output_label_array = np.asarray(output_labels)
outer_numbers = np.where(output_label_array == outer)[0]
inner_numbers = np.where(output_label_array == inner)[0]
plt.scatter(X[outer_numbers, 0], X[outer_numbers, 1], color='navy',marker='s', lw=0, s=10, label="outer learned")
plt.scatter(X[inner_numbers, 0], X[inner_numbers, 1], color='c',marker='s', lw=0, s=10, label="inner learned")
plt.legend(scatterpoints=1, shadow=False, loc='upper right')
plt.title("Labels learned with Label Spreading (KNN)")
plt.subplots_adjust(left=0.07, bottom=0.07, right=0.93, top=0.92)
plt.show() 
/********基于图谱的标签传播算法********/
# 生成一个5个节点的连续连通图
G = nx.path_graph(5)
G.node[0]['label'] = 'A'
G.node[3]['label'] = 'B'
G.nodes(data=True)
plt.figure(figsize=(20,10))
nx.draw(G,with_labels=True,
edge_color='blue',
node_color='grey',
node_size=10,
pos=nx.spring_layout(G,k=0.1,iterations=40))

import networkx as nx
from networkx.algorithms import node_classification
predicted = node_classification.local_and_global_consistency(G)
predicted
['A', 'B', 'B', 'B', 'B']# 关键特征提取
# 度
print(nx.degree(G))
DegreeView({'azure': 5, '.net': 8, 'sql-server': 9, 'asp.net': 13, 'entity-framework': 8, 'wpf': 6, 'linq': 7, 'wcf': 8, 'c#': 14, 'tdd': 1, 'agile': 1, 'codeigniter': 6, 'ajax': 7, 'jquery': 16, 'mysql': 11, 'css': 14, 'php': 10, 'javascript': 12, 'json': 4, 'cloud': 1, 'amazon-web-services': 4, 'devops': 3, 'docker': 4, 'ios': 6, 'android': 3, 'android-studio': 1, 'java': 8, 'typescript': 2, 'angular': 1, 'angular2': 2, 'angularjs': 13, 'ionic-framework': 1, 'reactjs': 8, 'mongodb': 8, 'sass': 9, 'twitter-bootstrap': 6, 'express': 5, 'node.js': 7, 'asp.net-web-api': 7, 'html5': 10, 'nginx': 3, 'apache': 3, 'linux': 10, 'scala': 3, 'apache-spark': 2, 'hadoop': 2, 'rest': 5, 'api': 1, 'sql': 5, 'mvc': 1, 'vb.net': 3, 'bash': 3, 'shell': 2, 'git': 4, 'bootstrap': 2, 'c++': 4, 'c': 4, 'python': 7, 'embedded': 1, 'xamarin': 1, 'unity3d': 1, 'visual-studio': 1, 'qt': 1, 'laravel': 4, 'wordpress': 6, 'photoshop': 1, 'html': 6, 'less': 3, 'jenkins': 4, 'django': 3, 'flask': 2, 'postgresql': 6, 'go': 1, 'drupal': 1, 'maven': 5, 'eclipse': 1, 'redis': 4, 'elasticsearch': 2, 'vba': 2, 'excel': 2, 'excel-vba': 2, 'redux': 4, 'github': 1, 'haskell': 1, 'jsp': 4, 'hibernate': 9, 'spring-boot': 3, 'web-services': 3, 'spring-mvc': 7, 'java-ee': 4, 'spring': 9, 'twitter-bootstrap-3': 2, 'swift': 4, 'osx': 4, 'objective-c': 5, 'iphone': 4, 'xcode': 4, 'xml': 1, 'vue.js': 1, 'unix': 1, 'ubuntu': 1, 'windows': 3, 'machine-learning': 2, 'r': 3, 'matlab': 1, 'react-native': 3, 'oracle': 2, 'plsql': 2, 'regex': 1, 'perl': 1, 'ruby-on-rails': 2, 'ruby': 2, 'powershell': 1, 'testing': 1, 'selenium': 1})
# 度中心性 m/(n-1)
print(nx.degree_centrality(G))
{'azure': 0.043859649122807015,
'.net': 0.07017543859649122,
'sql-server': 0.07894736842105263,
'asp.net': 0.11403508771929824,
'entity-framework': 0.07017543859649122,
'wpf': 0.05263157894736842,
'linq': 0.06140350877192982,
'wcf': 0.07017543859649122,
'c#': 0.12280701754385964,
'tdd': 0.008771929824561403,
'agile': 0.008771929824561403,
'codeigniter': 0.05263157894736842,
'ajax': 0.06140350877192982,
'jquery': 0.14035087719298245,
'mysql': 0.09649122807017543,
'css': 0.12280701754385964,
'php': 0.08771929824561403,
'javascript': 0.10526315789473684,
'json': 0.03508771929824561,
'cloud': 0.008771929824561403,
'amazon-web-services': 0.03508771929824561,
'devops': 0.02631578947368421,
'docker': 0.03508771929824561,
'ios': 0.05263157894736842,
'android': 0.02631578947368421,
'android-studio': 0.008771929824561403,
'java': 0.07017543859649122,
'typescript': 0.017543859649122806,
'angular': 0.008771929824561403,
'angular2': 0.017543859649122806,
................
print(nx.betweenness_centrality(G))
{'azure': 0.054000196569856024,
'.net': 0.002291495700904178,
'sql-server': 0.0035624458060689187,
'asp.net': 0.17406690608353656,
'entity-framework': 0.0010466285487518948,
'wpf': 0.0,
'linq': 2.5875899187496765e-05,
'wcf': 0.0010466285487518948,
'c#': 0.05575657988189837,
'tdd': 0.0,
'agile': 0.0,
'codeigniter': 0.007164044704799249,
'ajax': 0.018884826898334116,
'jquery': 0.25553997534572337,
'mysql': 0.19769314773273786,
'css': 0.04133537048548419,
'php': 0.011546520113878122,
'javascript': 0.023657465051749836,
'json': 0.12319763505138448,
'cloud': 0.0,
'amazon-web-services': 0.05643737397347083,
'devops': 0.015288500162743298,
'docker': 0.03081403967524134,
'ios': 0.03848717309360066,
'android': 0.03133053873622108,
'android-studio': 0.0,
'java': 0.07601405167311086,
'typescript': 0.01552553951249806,
'angular': 0.0,
'angular2': 0.030740568234746156,
'angularjs': 0.12286762799187793,
'ionic-framework': 0.0,
'reactjs': 0.01540985613288964,
'mongodb': 0.06737252741910404,
'sass': 0.0062847124280314215,
'twitter-bootstrap': 0.0,
....................
print(nx.closeness_centrality(G))
{'azure': 0.2120437349297414,
'.net': 0.20199200031681913,
'sql-server': 0.2047653458589265,
'asp.net': 0.24650814363733023,
'entity-framework': 0.20336921850079745,
'wpf': 0.1966647387700019,
'linq': 0.1970979210139887,
'wcf': 0.20336921850079745,
'c#': 0.2120437349297414,
'tdd': 0.008771929824561403,
'agile': 0.008771929824561403,
'codeigniter': 0.24448758508292587,
'ajax': 0.2586198154345401,
'jquery': 0.2895872367001647,
'mysql': 0.2778958265228288,
'css': 0.25787451337276907,
'php': 0.2513552138773901,
'javascript': 0.2571334946561807,
'json': 0.2458309234625024,
'cloud': 0.1654019522002789,
'amazon-web-services': 0.20290806381031945,
'devops': 0.1970979210139887,
'docker': 0.19753301576236396,
'ios': 0.17896491228070177,
'android': 0.1737523420200988,
'android-studio': 0.14549992868349734,
'java': 0.20018446563836884,
'typescript': 0.16509678254677285,
'angular': 0.13938077280428485,
.............
print(nx.katz_centrality(G))
{'azure': 0.086000597404453,
'.net': 0.12752395048659432,
'sql-server': 0.13490800430383726,
'asp.net': 0.1838839825412127,
'entity-framework': 0.1313654632872137,
'wpf': 0.1074413543796159,
'linq': 0.11970571584751195,
'wcf': 0.1313654632872137,
'c#': 0.16287279019149037,
'tdd': 0.024188487461603535,
'agile': 0.024188487461603535,
'codeigniter': 0.13405042234441555,
'ajax': 0.17009541155997618,
'jquery': 0.30513597783897295,
'mysql': 0.20736972742053683,
'css': 0.2753226815308488,
'php': 0.2187064376319827,
'javascript': 0.2654431371952479,
'json': 0.0772301825655986,
'cloud': 0.025746815297941216,
'amazon-web-services': 0.039771768002536595,
'devops': 0.032987025719495855,
'docker': 0.03528687353843744,
'ios': 0.04480929107470212,
'android': 0.03501405935072478,
'android-studio': 0.025271044646416534,
'java': 0.06236387099104653,
'typescript': 0.029049352694621024,
'angular': 0.024674573815228796,
'angular2': 0.0481225808512019,
'angularjs': 0.23448019736451475,
..............
# 连通子图
print(list(nx.connected_components(G))[0])
{'.net',
'ajax',
'amazon-web-services',
'android',
'android-studio',
'angular',
'angular2',
'angularjs',
'apache',
'api',
'asp.net',
'asp.net-web-api',
'azure',
'bash',
'bootstrap',
'c',
'c#',
'c++',
'cloud',
'codeigniter',
'css',
'devops',
'django',
'docker',
'drupal',
'eclipse',
'elasticsearch',
'embedded',
'entity-framework',
'express',
'flask',
'git',
'github',
'go',
'hibernate',
'html',
'html5',
......
# 取出网络的最大子图
Sub_G=G.subgraph(list(nx.connected_components(G))[0])
#计算节点的聚类系数
print(nx.clustering(Sub_G))
{'azure': 0.5,
'.net': 0.7857142857142857,
'sql-server': 0.6388888888888888,
'asp.net': 0.3974358974358974,
'entity-framework': 0.8571428571428571,
'wpf': 1.0,
'linq': 0.9523809523809523,
'wcf': 0.8571428571428571,
'c#': 0.34065934065934067,
'codeigniter': 0.6666666666666666,
'ajax': 0.6666666666666666,
'jquery': 0.3333333333333333,
'mysql': 0.36363636363636365,
'css': 0.3956043956043956,
'php': 0.5777777777777777,
'javascript': 0.5151515151515151,
'json': 0.16666666666666666,
'cloud': 0,
'amazon-web-services': 0.16666666666666666,
'devops': 0.6666666666666666,
'docker': 0.3333333333333333,
'ios': 0.4666666666666667,
'android': 0,
'android-studio': 0,
'java': 0.35714285714285715,
'typescript': 0,
'angular': 0,
'angular2': 0,
'angularjs': 0.3076923076923077,
'ionic-framework': 0,
'reactjs': 0.5,
'mongodb': 0.32142857142857145,
'sass': 0.6111111111111112,
'twitter-bootstrap': 1.0,
'express': 0.8,
'node.js': 0.5714285714285714,
'asp.net-web-api': 0.5714285714285714,
'html5': 0.5333333333333333,
'nginx': 0.3333333333333333,
'apache': 0.3333333333333333,
'linux': 0.08888888888888889,
...............
#计算网络的聚类系数
print(nx.average_clustering(Sub_G))
#计算网络的平均路径
#只能在连通子图中求解
print(nx.average_shortest_path_length(Sub_G))networkx官方文档参考:https://networkx.github.io/documentation/stable/reference/algorithms/node_classification.html