2020 第一周工作总结:TAGE分支预测器算法
TAGE分支预测是综合O-GEHL分支预测和PPM-like分支预测所设计的分支预测算法。
O-GEHL(Optimized GEometric History Length) branch prediction:

是在第一届CBP提出的算法,并且取得了最佳实践奖(best practice award),64Kbits的O-GEHL预测器准确率比其他在第一届CBP提出的预测器更高或相等。特别的,比在这一届CBP提出的其他唯一完备的预测器------PPM-like预测器更出色。
采用M个table, 各个表是通过PC和不同的历史(或路径)长度哈希索引的signed counter。预测结果由各个表预测结果通过加法树给出。
历史长度关系:![]()
加法:![]()
阈值: , 初始值为M
, 初始值为M
最终预测结果由![]() 跟 的关系,以及一些其他参数综合给出
跟 的关系,以及一些其他参数综合给出
对于阈值,有adaptative threshold fitting算法进行调整
对于历史长度,有dynamic history length fitting算法进行调整
例如M = 8, 历史长度会算11项,即T8,T9,T10备用
根据T7的path aliasing程度选择T2,T4,T6采用长历史长度还是短历史长度
混淆程度高则采用短历史长度,低就用高历史长度
由于TAGE已经不涉及到加法树以及O-GEHL的更新策略,我并没有详细阅读论文其他部分。
该部分参考自论文:
A. Seznec. Analysis of the o-gehl branch predictor. In Proceedings of the 32nd Annual International Symposium on Computer Architecture,June 2005.
PPM branch prediction:
PPM-like在第一届CBP取得了第五名的成绩。
PPM设计起初是用于数据压缩,之后才用于分支预测。

最左边的是一个bimodal predictor,记作bank 0。有4K项,是由PC的低12位索引的。每一项包含一个3bit的饱和计数器和一个1bit的m(代表meta-predictor)。所以该部分占用4K * (3+1) = 16K bits。
4个其他的bank是由PC和一些全局历史bits索引的:bank 1,2,3,4分别由10,20,40,80最近全局历史长度索引。每个bank有1K项,每一项由3bit饱和计数器ctr,8bit的tag,和1bit的u(useful entry)组成。即占用4 * 1K * (3+8+1) = 48K bits。
所以图示预测器占用64Kbits的空间。
在获取预测时,五个bank同时运行,找到各个bank中的对应项,对于bank0之外的bank,取对应项的tag跟当前branch pc与当前bank所采用的历史长度哈希出的8bit进行对比,相同则算命中,当前bank预测taken。最终的prediction 采用命中的bank中最高历史长度的预测结果,若都未命中,则采用bank0的预测结果。
更新策略:
当指令执行完毕,我们将会获取到预测来自bank X,以及预测结果是否正确。
更新3-bit counter: 只更新bank X中命中的那一项的ctr,预测正确+1,预测错误-1,边界则不变(饱和计数器)
分配新项:
若预测正确则不必分配新项。
预测错误取bank X+1 到 bank 4的对应项的u bit, 替换其中u=0的项,若无,从中任意选取一项替换。
填充规则:tag填充该bank哈希出的8bit tag;u填充0;ctr填充100或011,选择规则如下:
读取bank0对应项的m,
若为1,看bank X预测结果是taken还是not taken,taken填充100,not taken填充011。
若为0,看bank 0预测结果是taken还是not taken,taken填充100,not taken填充011。
更新u和m: 只更新bank X的对应项的u和bank 0的对应项的m。预测结果正确则都置为1,错误则都置为0。
论文参考自:
P. Michaud, A ppm-like, tag-based predictor. Journal of Instruction Level Parallelism(http://www.jilp.org/vo17), April 2005
TAGE(TAgged GEometric history length branch prediction:
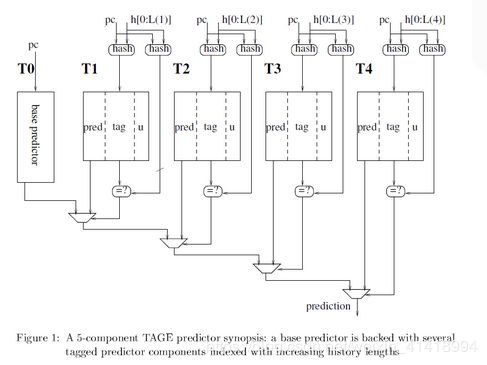
TAGE分支预测器直接源于PPM-like基于tag的分支预测器。由base predictor T0,和一序列(partially)tagged predictor components Ti组成,tagged predictor components Ti所采用索引历史长度是不同的,成几何长度关系,例如![]() 。
。
base predictor T0就是简单的PC索引的2-bit饱和计数器。
tagged predictor components Ti 由3 bit的signed ctr,tag,以及2bit的unsigned useful counter u组成。
预测计算方法跟PPM-like相似,若tag命中则取其中历史长度最长的component的预测结果,若未命中,则取base predictor的预测结果。
一些有用的概念:
provider component: tag命中则取其中历史长度最长的conponent,若无,即base predictor。
alternate component: 次一级tag命中的component,若无,即base predictor。
更新策略:
更新useful counter u:
if provider pred != altpred, 更新provider component中对应项的u(即预测正确+1,预测错误-1,在边界则不变)
此外,周期性重置所有的u,先重置高位,再重置低位。文中周期为256K branch。
预测正确时:更新provider component的ctr
预测错误时:
1. 更新provider component的ctr
2. 分配新项(至多分配一项):
若provider component 为 Ti,
读T(i+1)至T(M-1)的对应项的u,若有u = 0,替换其中最低历史长度的entry。若无,这些u = u -1。
填充的ctr为weak correct, u为0。
论文参考自:
A case for (partially) TAgged GEometric history length branch preddiction