kaggle_titanic数据集学习
- 目标
- Kaggle介绍
- 问题背景介绍
- 小问题
- 表头#
- 流程
- 分析数据
- 模型以及特征选择
- 数据认知
- 属性与获救结果的关联统计
- 看看各乘客等级的获救情况
-
- 特征选择
- 特征缺失
- 逻辑回归建模
- 交叉验证(cross validation)
-
- 参考
目标
主要是为了几天后的http://www.datafountain.cn/#/competitions/284/activity平安产险数据建模大赛,驾驶行为预测驾驶风险。我认为和这个Titannic数据集有许多相似的地方。
Kaggle介绍
Kaggle是一个数据分析建模的应用竞赛平台,有点类似KDD-CUP(国际知识发现和数据挖掘竞赛),企业或者研究者可以将问题背景、数据、期望指标等发布到Kaggle上,以竞赛的形式向广大的数据科学家征集解决方案。
问题背景介绍
这个数据集就是基于泰坦尼克号逃生的问题,看过电影的都知道,由于救生艇数量有限,“让女人和孩子先走”,所以是否获救不是随机的,而是有分级的。
训练和测试数据是一些船上人员的基本信息和幸存情况,要根据训练数据集生成合适的模型预测测试集的存活情况。
由于预测的只有存活与否,所以这是一个二分类问题。
小问题
由于Kaggle的登录需要验证,而国内不就不能刷出验证码,在C站下载数据集又需要C币。真的很麻烦,所以在github上找数据集。https://github.com/hitcszq/kaggle_titanic这个有数据集。
一共三个文件::
- train.csv 用来训练的数据集
- test.csv 用来测试的数据集,相比train.csv少了Survived这一栏
- titanic.csv 用来检验test,里面有Survived一栏。
表头#
https://www.kaggle.com/c/titanic/data这里有介绍
| 变量 | 定义 | 键值 |
|---|---|---|
| survival | 存活 | 0=No,1=Yes |
| pclass | 票的类别 | 1=1st,2=2nd,3=3rd |
| sex | 性别 | |
| Age | 年龄 | |
| sibsp | 在船上有几个兄弟/配偶 | |
| parch | 在船上有几个双亲/孩子 | |
| ticket | 票编号 | |
| fare | 乘客票价 | |
| cabin | 客舱号码 | |
| embarked | 登船港口 | C = Cherbourg, Q = Queenstown, S = Southampton |
注意
pclass:社会经济地位代号(SES)
1st = 上
2nd = 中
3rd = 下
age:如果年龄小于1,则年龄为分数。如果是估计年龄,格式为xx.5
sibsp:数据集以这种方式定义了家庭关系
Sibling =兄弟,姐妹,继兄弟,继姐妹
Spouse =丈夫,妻子(情妇和未婚妻被忽略)
parch:数据集以这种方式定义家庭关系
Parent =母亲,父亲
Child =女儿,儿子,继女,继子
如果孩子仅由保姆带着出行,他们的parch = 0。
流程
分析数据->学习建模->修改模型
使用Anaconda的spyder进行python开发
anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。
分析数据
使用pandas库加载数据进行大致游览(Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作。)
#引入库
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
import os
from os import path
filepath = path.dirname(__file__) #返回当前文件所在的目录
#加载数据
data_train = pd.read_csv(filepath+'\\data\\train.csv')
print(data_train.head())# 打印头五个
print(data_train.info())
data_train.describe()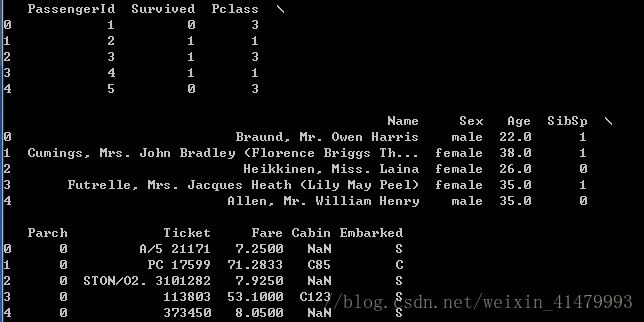
由于没有使用Jupyter Notebook,所以显示被分行了,不太直观。
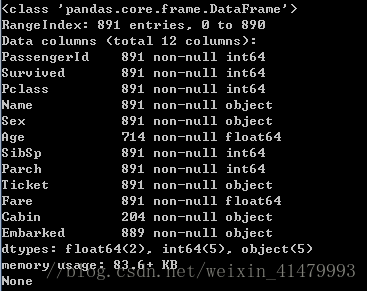
这里可以看到,共有12个属性,891个数据。有的数据不全,如carbin只有204个,年龄也不全。
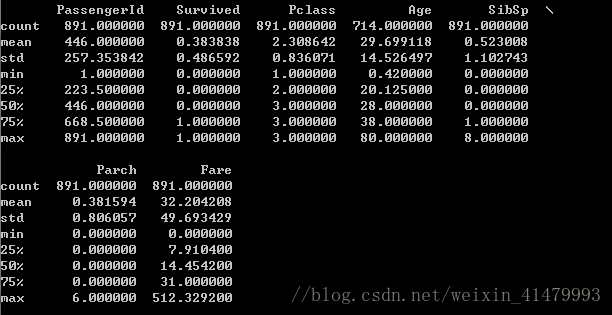
可以看到每个属性的计数(count)、均值(mean)、标准差(std)等。
在survived的mean值中看到,只有0.383838的人获救了,也就是大约1/3。
使用print(data_train.Age.mean()) 可以输出Age的均值。(计算这个时候会略掉无记录的)
模型以及特征选择
机器学习的关键部分无外乎是模型以及特征选择
常见的分类模型有:SVM,LR,Navie Bayesian,CART以及由CART演化而来的树类模型,Random Forest,GBDT。
数据认知
这是特征选择的基础。
#!/usr/bin/python2.6
# -*- coding: utf-8 -*-
#引入库
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
import os
from os import path
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
filepath = path.dirname(__file__) #返回当前文件所在的目录
#加载数据
data_train = pd.read_csv(filepath+'\\data\\train.csv')
#print(data_train.head())# 打印头五个
#print(data_train.info())
#print(data_train.describe())
#print(data_train.Age.mean())
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()
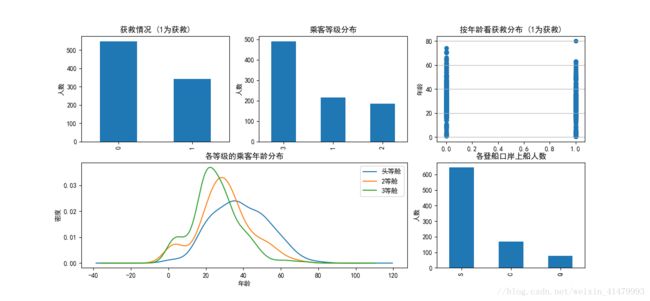
- 被救者300多人
- 3等舱人数很多,1、2等舱人数差不多、
- 遇难者和获救者各年龄都有
- 从S港上船的人数是绝大多数
- 年龄似乎与船舱等级有一定关系,坐在头等舱的年龄平均比其他舱的平均年龄大
这里确实会让人想的比较多:到底什么决定了幸存的概率呢?
属性与获救结果的关联统计
看看各乘客等级的获救情况
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()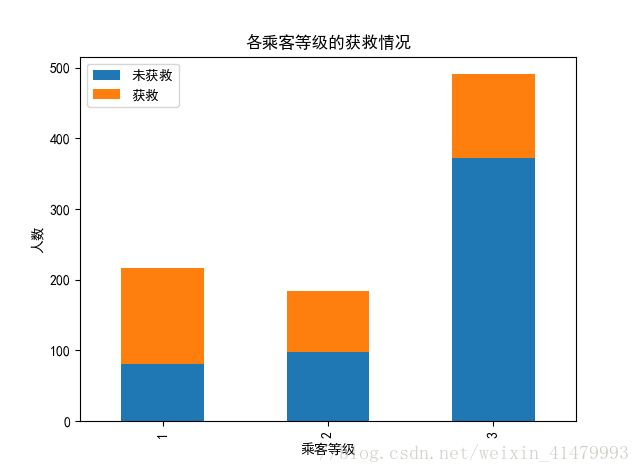
很明显,一等舱的获救概率>二等舱的获救概率>三等舱的获救概率
联系实际,舱位等级越低所居住的位置就更靠近船舱的底部,慌乱而拥挤的过道使得下层的人更不容易逃离。
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()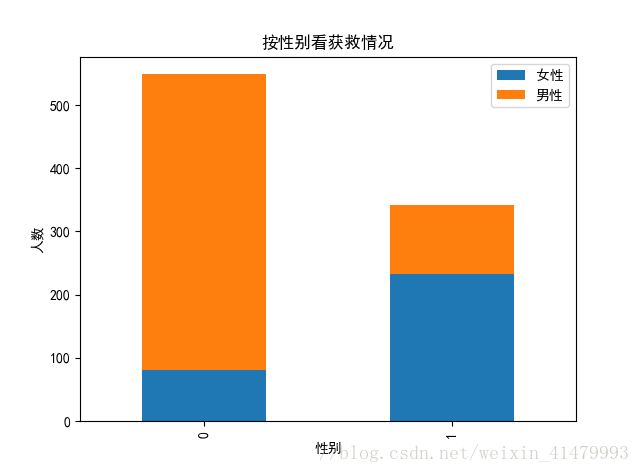
女性确实在幸存者中占很大比例。
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()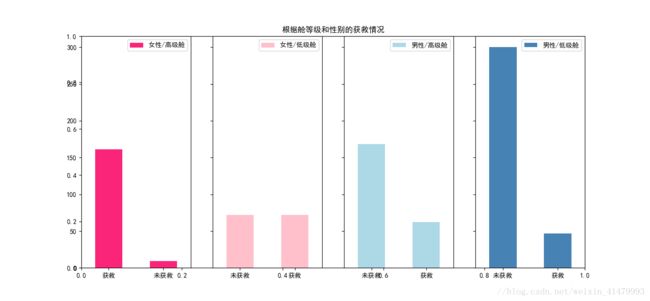
女性在高级舱获救的概率很大。
#各登船港口的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()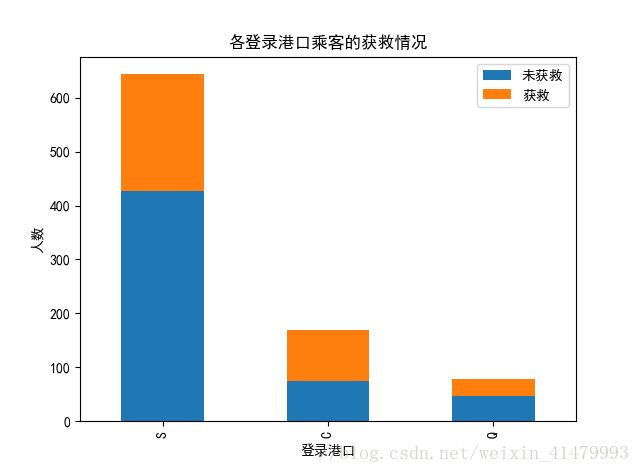
#堂兄弟/妹,孩子/父母有几人,对是否获救的影响。
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print df
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print df
好像不明显。
特征选择
『特征工程(feature engineering)十分重要!』
Carbin缺失严重,先不考虑。
考虑Name,船上肯定是有一家人的,面对危险,大家都会寻找亲人逃生,所以一家人的存活状况相关性会较高;另外,考虑当时的背景,“女士和孩子优先”,所以这个时候加人就会分开,要综合考虑。
特征缺失
数据中某些数据的缺失是很正常的,处理方法:
- 抛弃这条数据
- 对于缺失数据统一归为一类,分析这一类占的权值
- 如何这个特征缺失率很高:
- 直接抛弃这列特征
- 设置一个模型拟合这维度的特征
- 设置默认值 ,可以使均值、或众数。
逻辑回归建模
逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,’no’],而将其平展开为’Cabin_yes’,’Cabin_no’两个属性。
Age和Fare两个属性,乘客的数值幅度变化很大。而逻辑回归与梯度下降,如果各属性值之间范围差距太大,将对收敛速度造成影响,甚至难以收敛! 所以我们应该对这些属性做一个缩放(scaling),其实就是将一些变化幅度较大的特征化到[-1,1]之间。
然后就可以进行建模了。
建模测试后就代表一个基础模型建立完成,我们应分析模型现在的状态了,是过拟合还是欠拟合?确定我们需要更多的特征还是更多数据,或者其他操作。
计算关联度系数
每修改一次就判定一次修改的结果好还是坏,这样其实不是一个好方法。
分析bad case。
要判断是过拟合(overfitting/high variace),还是欠拟合(underfitting/high bias)。过拟合在训练数据集表现很好,而在测试集上表现较差。
交叉验证(cross validation)
思想介绍编辑
在使用训练集对参数进行训练的时候,经常会发现人们通常会将一整个训练集分为三个部分(比如mnist手写训练集)。一般分为:训练集(train_set),评估集(valid_set),测试集(test_set)这三个部分。这其实是为了保证训练效果而特意设置的。其中测试集很好理解,其实就是完全不参与训练的数据,仅仅用来观测测试效果的数据。而训练集和评估集则牵涉到下面的知识了。
因为在实际的训练中,训练的结果对于训练集的拟合程度通常还是挺好的(初试条件敏感),但是对于训练集之外的数据的拟合程度通常就不那么令人满意了。因此我们通常并不会把所有的数据集都拿来训练,而是分出一部分来(这一部分不参加训练)对训练集生成的参数进行测试,相对客观的判断这些参数对训练集之外的数据的符合程度。这种思想就称为交叉验证(Cross Validation) 。
Q:为什么不用测试集进行评估,而是要单独分出一个评估集合
W:我个人认为如果用测试集评估,就等于要用训练集拟合测试集,这很容易产生过拟合,即为了满足测试集去修改模型。采用评估集合,就以此来做为评价分类器的性能指标
1)训练集的比例要足够多,一般大于一半
2)训练集和测试集要均匀抽样
模型融合
简单的模型融合大概就是这么个意思,比如分类问题,当我们手头上有一堆在同一份数据集上训练得到的分类器(比如logistic regression,SVM,KNN,random forest,神经网络),那我们让他们都分别去做判定,然后对结果做投票统计,取票数最多的结果为最后结果
参考
http://blog.csdn.net/han_xiaoyang/article/details/49797143
http://blog.csdn.net/lhx878619717/article/details/49079785