从架构角度来看 Java 分布式日志如何收集
原创
首先,当我们如果作为架构师的角度去处理一件事情的时候,必须要有一些大局观。
也就是要求我们对个 Logging 的生态有完整的认识,从而来考虑分布式日志如何处理。
我们先来理解一些概念:
划分清楚 Logging 、Metrics、 Tracing
身边有很多同事会把这三件可能认识不太彻底,其实这是三件分别侧重点不同的事情,每件事都有各自的深度、边界和重叠部分。
Logging:
Logging 更加偏重的是一条一条的记录,而记录本身是离散事件,没有任何直接关系。Logging 可以在 Console、ElasticSearch、Kafka、File 等各种媒介中显示。而 Logging 的格式又可以通过各种 Logging 的实现去定义 Logging 的格式。Tracing:
Tracing 的重心是整个处理链条的间接关系,而是需要把各种离散的 Logging 产生联系,让各种处理事件产生一定范围。Metrics:
Metrics 度量的定义特征是它们是可聚合的。它们是在一段时间内构成单个逻辑度量,计数或直方图的原子数据,偏重于度量。

而三者的边界和重叠部分需要我们在整个分布式系统中要非常清楚,而本 chat 就围绕 Logging 和 Tracing 这两件事情展开一下。
技术 Tracing 链路跟踪、生态圈现状
Google Dapper:Dapper——Google 生产环境下的分布式跟踪系统,而紧接着就发表了论文 Google Dapper paper 。
然后就变成了所有分布式日志 Tracing 的鼻祖了,后来发展起来的 Zipkin、OpenTracing、sleuth 都是在 Google 的这篇论文作为理论基础上,不断优化发展出来的。
Zipkin:Zipkin 是分布式日志链路跟踪系统,最早由 Twitter 创造和开源,现在交由 OpenZipkin 社区管理。它可以帮助收集时间数据在 Microservice 架构需要解决延迟问题。
它管理这些数据的收集和查找。Zipkin 的设计是基于 Dapper。它也是一个完整的生态解决方案包括:collector(收集)、 storage(储存)、 search(搜索)、 Zipkin Web UI(页面控制台)。
而其也对个各种语言做了支持,我们重点关注了一下 java 的 client,看后面的表格。github : https://github.com/openzipkin;官方地址:http://zipkin.io/
OpenTracing:OpenTracinghttp://opentracing.io/通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。
OpenTracing 正在为全球的分布式追踪,提供统一的概念和数据标准。而 OpenTracing 来自大名鼎鼎的 CNCF(Cloud Native Computing Foundation, https://www.cncf.io/)。
虽然 OpenTracing 晚于 Zipkin 但是更大大佬、更大抽象,这使其很快成为业内首选。而开源团队:Zipkin、TRACER、JAEGER(Uber 出品)等等逐渐实现了 OpenTracing 的标准。
Sleuth:这个热闹的事情,怎么能少了 Spring 开源社区呢?Spring-Cloud-Sleuth 是 Spring Cloud 的组成部分之一,为 SpringCloud 应用实现了一种分布式追踪解决方案,其兼容了Zipkin、HTrace、OpenTracing。
而底层是基于 Zipkin 的 brave 做了实现。设计思路也是参考 Dapper(他们之间的关系,作者认为应该是这样的 sleuth 通过 brave 默认输出到 Zipkin,由 Zipkin 决定是否是 OpenTracing 格式的输出,PS:这个欢迎大家一起讨论)。
官方地址:http://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.0.0.RC1/single/spring-cloud-sleuth.html
Jaeger 分布式监控系统由 Uber 设计并实现,现已捐赠给 CNCF 基金会,作为分布式环境下推荐的监控系统。其实主要是作为 Tracing 的 server 端,前期先支持了 Zipkin 后来又实现了 OpenTracing 的标准。有 UI 和储存(ElasticSearch、cassandra)。和 Zipkin 的 ui 服务器端有点像。官方地址:https://www.jaegertracing.io/
重点关注一下 Zipkin 的开源库

Tracing 整体负责干的事情有:
生成 trackId, spanId。
负责 MDC 给 log。
发送给 tracingserver 端,server 负责储存和搜索。
Tracing UI 负责展示。
技术 Logging 本身,生态圈现状
上面我们了解整个 Tracing 的技术栈,我们再来看下关于 Logging 的技术栈。
Spring Logging:Java Util Logging、SLF4J、Log4J、Log4J2和Logback 这些都是老生常谈的问题了,默认 Spring Logging 内部采用的是 Commons Logging。
但是当我们引用相应的其它 Logging 的实现和相应的 Logging 文件的时候就会自动切换 Logging 的实现,并做到兼容。我们唯一需要注意的是:SpringProfile 的支持,如下:
自定义日志实现:

ELK:Spring Logging 紧紧是负责单机日志输出,而分布式不得不请出 ELK。
ElasticSearch 负责作为我们的 logs 的储存和查询,其数据可以提供给 Jaeger 使用可以给 Kibana 使用。
而 Kibana 负责做各种基于 logs 的 chat 图和查看详细的 Logging 的日志记录的详情。Logstash 不用多说了,负责给我们收集日志,包括网关层,业务层等。

Sentry:也是一个重量级选手。负责解决我们系统中的 error 日志和 error 日志警告。
Sentry 就是来帮我们解决这个问题的,它是一款精致的 Django 应用,目的在于帮助开发人员从散落在多个不同服务器上毫无头绪的日志文件里发掘活跃的异常,继而找到潜在的臭虫。
Sentry 是一个日志平台, 它分为客户端和服务端,客户端(目前客户端有 Python、PHP、C#、Ruby 等多种语言)就嵌入在你的应用程序中间,程序出现异常就向服务端发送消息,服务端将消息记录到数据库中并提供一个 Web 界面方便查看。
Sentry 还有有很多亮点,比如敏感信息过滤, release 版本跟踪,关键字查找,受影响用户统计,权限管理等(部分可能需要我们通过代码提供内容)可以通过 Sentry 进行问题分配与跟踪。
Sentry 的 plugin 模块还可以集成大量的第三方工具如: slack , jira 。
对我们来说最大的便利就是利用日志进行错误发现和排查的效率变高了。
重要的有一下三点:
及时提醒
报警的及时性:不需要自己再去额外集成报警系统,一旦产生了 issue 便以邮件通知到项目组的每个成员。问题关联信息的聚合
每个问题不仅有一个整体直观的描绘,聚合的日志信息省略了人工从海量日志中寻找线索,免除大量无关信息的干扰。丰富的上下文
Sentry 不仅丰富还规范了上下文的内容,也让我们意识到更多的有效内容,提高日志的质量。
技术选型 VS
当我们了解了我们需要知道的技术点之后,接下去就是针对我们公司具体业务现状进行选型,以我们公司为例,可能不止一个 Java 团队,还有 Ruby,node.js 等其它语言的开发团队。
好多其它技术选型都是基于 cncf 的,如:k8s、docker、permissions 等,所以我们就一如既往的还选择了 CNCF 的技术体系及 OpenTracing。
其实如果要去真实比较的话,差别也不是特别大,并且都做到了相互的兼容。而 Jaeger VS Zipkin server 选择了 Jaeger,因其启动简单与 Java 解耦。
Java 语言体系采用 Spring 的 Sleuth,这样我们可以省很多事情,并且也是很成熟的解决方案,而 Spring Cloud 生态也非常成熟。
实战
生产的日志要求
每个请求的参数是什么,输出结果是什么,debug 可以选择自由开启。
每个请求的链路要串起来。
error 独立收集上下文是什么,及时警告,各个环境分开。
生产的日志实现
第一个问题:所有请求的日志明细
1. 我们利用
import org.springframework.web.filter.CommonsRequestLoggingFilter;来打印我们的所有的请求的日志配置如下:
//我们只需要将此类在配置文件中加载即可。里面可以设置Logging里面是否打印header 、request payload、query String 、client信息等。唯一的缺点就是没有办法打印responseBody。
@Bean
@ConditionalOnMissingBean
public CommonsRequestLoggingFilter requestLoggingFilter() {
CommonsRequestLoggingFilter loggingFilter = new CommonsRequestLoggingFilter();
loggingFilter.setIncludeClientInfo(true);
loggingFilter.setIncludeQueryString(true);
loggingFilter.setIncludePayload(true);
loggingFilter.setIncludeHeaders(true); return loggingFilter;
}//源码和原理其实非常简单,做个filter做logging debug即可。public class CommonsRequestLoggingFilter extends AbstractRequestLoggingFilter { @Override
protected boolean shouldLog(HttpServletRequest request) { return logger.isDebugEnabled();
} /**
* Writes a log message before the request is processed.
*/
@Override
protected void beforeRequest(HttpServletRequest request, String message) {
logger.debug(message);
} /**
* Writes a log message after the request is processed.
*/
@Override
protected void afterRequest(HttpServletRequest request, String message) {
logger.debug(message);
}
}日志输出的格式如下:
[36667] 2018-05-19 20:22:06.185 - [notification-api,93bb291ab411e41a,93bb291ab411e41a,false] - DEBUG [http-nio-8080-exec-1] org.springframework.web.filter.CommonsRequestLoggingFilter.log - Before request [uri=/hello;client=127.0.0.1;headers={host=[127.0.0.1:8080], connection=[keep-alive], accept=[*/*], user-agent=[Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36], referer=[http://127.0.0.1:8080/swagger-ui.html], accept-encoding=[gzip, deflate, br], accept-language=[en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7], cookie=[OUTFOX_SEARCH_USER_ID_NCOO=1602949848.9012377; gsScrollPos-73=]}]
[36667] 2018-05-19 20:22:06.434 - [notification-api,93bb291ab411e41a,93bb291ab411e41a,false] - DEBUG [http-nio-8080-exec-1] org.springframework.web.filter.CommonsRequestLoggingFilter.log - After request [uri=/hello;client=127.0.0.1;headers={host=[127.0.0.1:8080], connection=[keep-alive], accept=[*/*], user-agent=[Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36], referer=[http://127.0.0.1:8080/swagger-ui.html], accept-encoding=[gzip, deflate, br], accept-language=[en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7], cookie=[OUTFOX_SEARCH_USER_ID_NCOO=1602949848.9012377; gsScrollPos-73=]}]2. 针对没有 responseBody 的问题,我们可以自定义一个拦截器,和 CommonsRequestLoggingFilter 做差不多的事情即可。这里需要注意的是需要用到:
import org.springframework.web.util.ContentCachingRequestWrapper;
import org.springframework.web.util.ContentCachingResponseWrapper;来做参数的输出和 response 的 io 的输出。但是切记很多东西不需要重复写给大家看一个关键代码:

第二个问题: 将 Logging 收集到 ELK
此处我们采用的是 Docker 容器,直接将日志输出到控制台,用 logstash 直接收集 Docker 的日志给 ElasticSearch 在 kibana 显示。如下图所示:
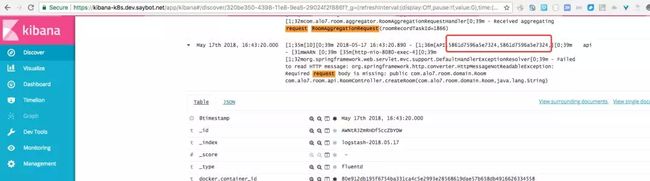
我们只需要 search trackID 即可。
或者以 logback 为例,添加 logstash appender。关键代码如下:
${LOG_FILE}.json
${LOG_FILE}.json.%d{yyyy-MM-dd}.gz
7
UTC
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
第三个问题:我们在我们的每个请求 Header 上加上 traceId
//从上下文中取到traceId,然后丢到返回的header里面
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
String traceId = ThreadContext.get("traceId");
chain.doFilter(request, response);
((HttpServletResponse)response).setHeader("TraceId", traceId);
}第四个问题:Tracing 处理
1. 有了上面的理论基础,就是就看看 spring cloud sleuth 怎么支持 OpenTracing 和生成 tracId 和 span,及其将 log 吐给 jaeger。