三种分布式爬虫系统的架构方式
分布式爬虫系统广泛应用于大型爬虫项目中,力求以最高的效率完成任务,这也是分布式爬虫系统的意义所在。
分布式系统的核心在于通信,介绍三种分布式爬虫系统的架构思路,都是围绕通信开始,也就是说有多少分布式系统的通信方式就有多少分布式爬虫系统的架构思路。
- Redis
利用redis做分布式系统,最经典的就是scrapy-Redis,这是比较成熟的框架。同时我们也可以利用Redis的队列功能或者订阅发布功能来打造自己的分布式系统。
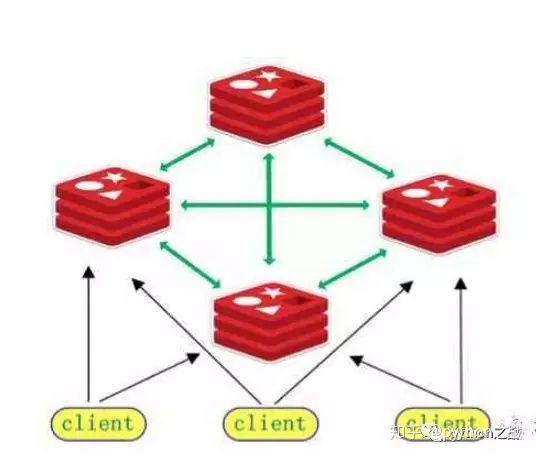
Redis作为通信载体的优点是读写迅速,对爬虫的速度影响可忽略不 计,使用比较普遍。
主程序示例:
import scrapy
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from scrapy.dupefilter import RFPDupeFilter
from scrapy.core.scheduler import Scheduler
import redis
from ..items import XiaobaiItem
from scrapy_redis.spiders import RedisSpider
class RenjianSpider(RedisSpider):
name = 'baidu'
allowed_domains = ['baidu.com']
def parse(self, response):
news_list = response.xpath('//*[@id="content-list"]/div[@class="item"]')
for news in news_list:
content = response.xpath('.//div[@class="part1"]/a/text()').extract_first().strip()
url = response.xpath('.//div[@class="part1"]/a/@href').extract_first()
yield XiaobaiItem(url=url,content=content)
yield Request(url='http://dig..com/',callback=self.parse)
2.RabbitMQ
RabbitMQ是比较靠谱的消息中间件,得益于它的确认机制,当一条消息消费后如果设置确定模式,那么确认后才会继续消费,如果不确定认,那么这个任务将分配给其他消费者。
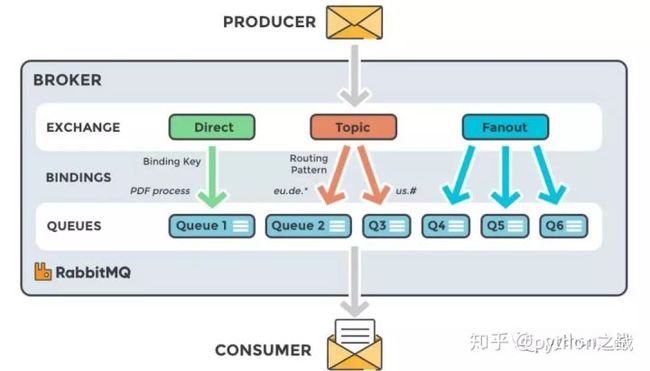
基于这种确认机制,可以在高可靠性和高数据要求情景中,避免数据抓取的遗漏和丢失。
其设计思路应该是基于mq设计两个接口,一个用于URL的存放,一个用户URL的获取,同时基于Redis的URL去重,通过类似scrapy-redis 的调度使爬虫运行。
主程序示例:
import pika
class RabbitMQBASE:
def __new__(cls, *args, **kw):
if not hasattr(cls, '_instance'):
org = super(RabbitMQBASE, cls)
cls._instance = org.__new__(cls)
return cls._instance
def __init__(self, use='root', pwd='111'):
user_pwd = pika.PlainCredentials(use, pwd)
self.s_conn = pika.BlockingConnection(
pika.ConnectionParameters(host='1.1.1.1', heartbeat_interval=3600, credentials=user_pwd))
def channel(self):
return self.s_conn.channel()
def close(self):
"""关闭连接"""
self.s_conn.close()
@staticmethod
def callback(ch, method, properties, body):
print(" [消费者] %r" % body)
class RabbitMQ(RabbitMQBASE):
"""
type_:交换机类型fanout、direct、topic
exchange:交换机名字
queue_name:队列名字,为空则随机命名
exclusive:队列是否持久化False持久,True不持久
key_list:消费者的交换机、队列绑定的关键词列表
key:生产者路由的关键词
no_ack:是否确认消息True不确定,False确定
"""
def __init__(self, use='root', pwd='Kw7pGR4xDD1CsP*U', type_='direct', exchange='test',
queue_name=None, exclusive=True, key_list=['test'], key='test', no_ack=True):
RabbitMQBASE.__init__(self, use=use, pwd=pwd)
self.type_ = type_
self.exchange = exchange
self.queue_name = queue_name
self.exclusive = exclusive
self.key = key
self.key_list = key_list
self.no_ack = no_ack
def rabbit_get(self):
"""消费者"""
channel = self.channel()
channel.exchange_declare(exchange=self.exchange, exchange_type=self.type_)
if self.queue_name == None:
result = channel.queue_declare(exclusive=self.exclusive)
self.queue_name = result.method.queue
if self.type_ != 'fanout':
for key in self.key_list:
channel.queue_bind(exchange=self.exchange, # 将交换机、队列、关键字绑定
queue=self.queue_name, routing_key=key)
channel.basic_consume(RabbitMQBASE.callback, queue=self.queue_name, no_ack=self.no_ack)
channel.start_consuming()
def rabbit_put(self, message='hello word'):
"""生产者"""
channel = self.channel()
channel.exchange_declare(exchange=self.exchange, exchange_type=self.type_)
if self.type_ == 'fanout':
self.key = ""
channel.basic_publish(exchange=self.exchange, routing_key=self.key, body=message)
channel.close()
3.Celery
celery典型的分布式任务队列,常用于异步操作中,如tornado、Django的异步任务中,用celery设计分布式爬虫系统,往往结合网络框架,打造一个爬虫任务接口,提供给其他人使用。
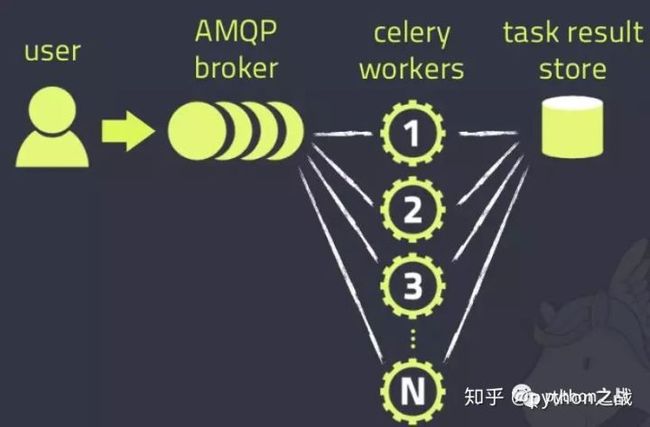
同时celery在定时任务方面有着优势,只需要在配置文件中设置一下,就可以定期执行任务,不必自己写定时操作。
celery使用消息中间件,而这个消息中间件,可以使用Redis也可以使用RabbitMQ,但他的调度不必担心,已经封装。
主程序示例:
# -*- coding:utf-8 -*-
from celery import Celery
app = Celery("tasks")
app.config_from_object("celeryconfig") # 指定配置文件
@app.task
def taskA(x, y):
return x + y
@app.task
def taskB(x, y, z):
return x + y + z
@app.task
def add(x, y):
return x + y
注意:上面的程序片段只是片段,用于示例。
综上我们应该清楚在不同的任务场景中使用甚至如何设计自己的爬虫系统,分布式爬虫系统的核心是不同主机的通信。
------------------------------
ID:Python之战
|作|者|公(zhong)号:python之战
专注Python,专注于网络爬虫、RPA的学习-践行-总结
喜欢研究技术瓶颈并分享,欢迎围观,共同学习。
独学而无友,则孤陋而寡闻!
---------------------------