python+opencv+tensorflow车牌识别(待补)
车牌定位检测
先上效果

由于不同的颜色、角度、大小需要设置不同的阙值,准确度跟训练样本也有关,因此可以调整阙值以适应不同的环境需求

到这步代码如下
import cv2
import numpy as np
import os
#预设RGB值,在后面处理时筛选出蓝色区域
lower_blue = np.array([160, 80, 19])
upper_blue = np.array([250, 150, 250])
lower_yellow = np.array([15, 55, 55])
upper_yellow = np.array([50, 255, 255])
#在调用cv2库的时候偶尔会报错,经查询是路径的问题,我这里图片全部使用绝对路径
def get_path(dirname):#图片所在目录名
path=os.path.dirname(__file__)#获取当前路径
path0=os.listdir(os.path.join(path+'/'+dirname+'/'))#目录下所有文件名
path1 = os.path.join(path + '/' + dirname + '/')#目录下所有文件绝对路径
# print(path1+path_)
return path0,path1 #返回文件名和绝对路径
def enhance_contrast(image):#图像增强
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
img_tophat = cv2.morphologyEx(image, cv2.MORPH_TOPHAT, kernel)
img_blackhat = cv2.morphologyEx(image, cv2.MORPH_BLACKHAT, kernel)#这里主要将图片腐蚀话,过滤掉较小的噪声
image_plus_tophat = cv2.add(image, img_tophat)
image_plus_blackhat_minus_blackhat = cv2.subtract(image_plus_tophat, img_blackhat)
return image_plus_blackhat_minus_blackhat
def img_processing(img,filename):#进一步图像处理,写的比较乱,图像处理步骤可以重新调整下
img=cv2.imread(img)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (15, 15))
img_=enhance_contrast(img)
hsv = cv2.cvtColor(img_, cv2.COLOR_BGR2HSV)
mask_blue = cv2.inRange(img, lower_blue, upper_blue)
mask_yellow = cv2.inRange(hsv, lower_yellow, upper_yellow)
output = cv2.bitwise_and(hsv, hsv, mask=mask_blue)
# 根据阈值找到对应颜色
closed = cv2.morphologyEx(output, cv2.MORPH_CLOSE, kernel)
closed = cv2.morphologyEx(closed, cv2.MORPH_CLOSE, kernel)
closed_ = cv2.dilate(closed, None, iterations=4)#这里用一个较大的值又对图片腐蚀了一下
gray = cv2.cvtColor(closed_, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,100, 255, cv2.THRESH_BINARY)
img0, ctrs, hier = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#对处理好的图片查找边界
box_filter=[]
a = sorted(ctrs, key=cv2.contourArea, reverse=True)[0]
for i in range(len(ctrs)):
c = sorted(ctrs, key=cv2.contourArea, reverse=True)[i]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)#最小外界矩形,到这步很多不规则噪声就会过滤掉了
box=np.int0(cv2.boxPoints(rect))
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
if width/hight<4 and width/hight>2 and cv2.contourArea(box)>800:#很多时候会有一些其他矩形干扰,这里把长宽比3/1的找出来,并且面积大于800
box_filter.append(box)#多个车牌的时候把所有符合要求的放入到list中
cv2.drawContours(img, [box], -1, (0, 0, 255), 1)#绘制出矩形框,
cropImg = img[y1:y1 + hight, x1:x1 + width]#定位输出区域
cv2.imwrite('plate_num/'+filename+'.jpg',cropImg)#将输出保持为图片存在文件夹下
else:
pass
if box_filter==[]:#对于有变形的无法识别出车牌,这里将最大矩形面积存为图片
rect0 = cv2.minAreaRect(a)
box0 = np.int0(cv2.boxPoints(rect0))
cv2.drawContours(img, [box0], -1, (0, 0, 255), 1)
Xs = [i[0] for i in box0]
Ys = [i[1] for i in box0]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
# RotateMatrix = cv2.getRotationMatrix2D(center=(img.shape[1] / 2, img.shape[0] / 2), angle=-10, scale=1)#试验下调平
# cropImg = cv2.warpAffine(img, RotateMatrix, (img.shape[0] * 2, img.shape[1] * 2))
cropImg = img[y1:y1 + hight,x1:x1 + width]
cv2.imwrite('plate_num/' + filename+'.jpg', cropImg)
else:
pass
print('plate_num/' + filename+'.jpg')
return img,('plate_num/' + filename+'.jpg')
车牌字符分割
先上效果:边框没过滤掉,后面再调整
现在可以去掉这个了![]()




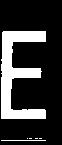


这步代码如下
def split_img():
img=cv2.imread('plate_num/timg5.jpeg.jpg')#读取上一步定位的车牌信息
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_thre = gray
ret, thresh1=cv2.threshold(img_thre, 130, 255, cv2.THRESH_BINARY)
#图片二值化处理,原先多个通道的现在只有一个 0-黑色 255-白色
print(thresh1.shape)
# 以下为识别车牌中的字符
w_point=[]
w_point0=[]
height = thresh1.shape[0] #获取车牌高
width = thresh1.shape[1] #获取车牌长
for i in range(height):#去掉w_point数值小于X的行
a = 0
for j in range(width):
if thresh1[i][j] == 255:
a+=1
if 300>a>50 :#如果一行中白色元素在300/5之间则保留,其余行全部转为黑色
continue
else:
for b in range(width):
thresh1[i][b]=0
for i in range(width):#去掉w_point数值小于X的列
a = 0
for j in range(height):
if thresh1[j][i] == 255:
a+=1
if 300>a>=20 :#如果一列中白色元素在300/5之间则保留,其余列全部转为黑色
continue
else:
for b in range(height):
thresh1[b][i] = 0
#因为是按列分割,所以行不变,对列进行分析,如果一列上白元素为0那肯定是分割点
for i in range(width):#对于刚才处理完的图片,重新查询每一列白色
a = 0
for j in range(height):
if thresh1[j][i] == 255:
a+=1
w_point.append(a)#生成一两list用来存储每一列白元素的数量
letter = []
n = 0
for i in range(len(w_point) - 1):
if w_point[i] == 0 and w_point[i + 1] != 0:
letter.append(i)#生成一个list,保存了从哪列开始有白元素
#针对demo letter列表为[6, 23, 80, 164, 225, 282, 344, 399, 453],也就是从6,23,80....开始有白元素
print(letter)
for i in range(len(letter)-1):#直接安装letter点对图像进行分割
start=letter[i]
end=letter[i+1]
i=i+1
print(start,end)
if end-start>10# 去掉边框及误差
img_=thresh1[:,start:end]
# cv2.imshow('img',img_)
cv2.imwrite('spilt_num/'+'%s.jpg'%i,img_)
卷积神经网络训练(附数据集)
多层神经网络训练,这个没啥还说滴,具体算法可见上篇文章,数据集为网上找的,也可以自行采集训练,包含24个字母(无i,o),0-9数字和部分省标识
也可从我的资源这下载https://download.csdn.net/download/weixin_41819529
# !/usr/bin/python3.5
# -*- coding: utf-8 -*-
import sys
import os
import time
import numpy as np
import tensorflow as tf
from PIL import Image, ImageFilter
sess=tf.InteractiveSession(config=tf.ConfigProto(allow_soft_placement=True))
NUM_CLASSES = 26
SIZE=1280
WIDTH = 32
HEIGHT = 40
iterations = 300
x = tf.placeholder(tf.float32, shape=[None, SIZE])
y_ = tf.placeholder(tf.float32, shape=[None, NUM_CLASSES])
x_image = tf.reshape(x, [-1, WIDTH, HEIGHT, 1])
def weight_variable(shape,name):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial,name=name)
def bias_variable(shape,name):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial,name=name)
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
#数据整理
input_count = 0
for i in range(0, NUM_CLASSES):
dir = 'tf_car_license_dataset/train_images/training-set/letters/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
input_count += 1 #1254
input_images = np.array([[0] * SIZE for i in range(input_count)]) #shape=(1254,1280)
input_labels = np.array([[0] * NUM_CLASSES for i in range(input_count)]) #shape=(1254,6)
# 第二次遍历图片目录是为了生成图片数据和标签
index = 0
for i in range(0, NUM_CLASSES):
dir = 'tf_car_license_dataset/train_images/training-set/letters/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
filename = dir + filename
img = Image.open(filename)
im = img.convert('L')
width = img.size[0] #32
height = img.size[1] #40
for h in range(0, height):
for w in range(0, width):
# 通过这样的处理,使数字的线条变细,有利于提高识别准确率
if im.getpixel((w, h)) > 230:
input_images[index][w + h * width] = 0
else:
input_images[index][w + h * width] = 1
input_labels[index][i] = 1
index += 1
# 第一次遍历图片目录是为了获取图片总数
val_count = 0
for i in range(0, NUM_CLASSES):
dir = 'tf_car_license_dataset/train_images/validation-set/letters/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
val_count += 1 #32
# 定义对应维数和各维长度的数组
val_images = np.array([[0] * SIZE for i in range(val_count)])
val_labels = np.array([[0] * NUM_CLASSES for i in range(val_count)])
# 第二次遍历图片目录是为了生成图片数据和标签
index = 0
for i in range(0, NUM_CLASSES):
dir = 'tf_car_license_dataset/train_images/validation-set/letters/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
filename = dir + filename
img = Image.open(filename)
im = img.convert('L')
width = img.size[0]
height = img.size[1]
for h in range(0, height):
for w in range(0, width):
# 通过这样的处理,使数字的线条变细,有利于提高识别准确率
if im.getpixel((w, h)) > 230:
val_images[index][w + h * width] = 0
else:
val_images[index][w + h * width] = 1
val_labels[index][i] = 1
index += 1
#第一个卷积层
w_conv1 = weight_variable([5, 5, 1, 16], 'w_conv1')
b_conv1 = bias_variable([16], 'b_conv1')
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1)
h_pool1 = max_pool(h_conv1)
#
#第二个卷积层
w_conv2 = weight_variable([5, 5, 16, 32], 'w_conv2')
b_conv2 = bias_variable([32], 'b_conv2')
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)
h_pool2 = max_pool(h_conv2)
#relu激活
w_fc1 = weight_variable([8 * 10 * 32, 256], 'w_fc1')
b_fc1 = bias_variable([256], 'b_fc1')
h_pool_flat = tf.reshape(h_pool2, [-1, 8 * 10 * 32])
h_fc1 = tf.nn.relu(tf.matmul(h_pool_flat, w_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
h_drop = tf.nn.dropout(h_fc1, keep_prob)
#全连接层
w_fc2 = weight_variable([256, 26], 'w_fc2')
b_fc2 = bias_variable([26], 'b_fc2')
y_conv = tf.nn.softmax(tf.matmul(h_drop, w_fc2) + b_fc2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
# cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))#y_conv(2,6),y_(2,6)
train = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
tf.global_variables_initializer().run()
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 设置每次训练op的输入个数和迭代次数,这里为了支持任意图片总数,定义了一个余数remainder,譬如,如果每次训练op的输入个数为60,图片总数为150张,则前面两次各输入60张,最后一次输入30张(余数30)
batch_size = 50
iterations = iterations
batches_count = int(input_count / batch_size)
remainder = input_count % batch_size
print("训练数据集分成 %s 批, 前面每批 %s 个数据,最后一批 %s 个数据" % (batches_count + 1, batch_size, remainder))
with tf.device('/GPU:0'):
for it in range(iterations):
# 这里的关键是要把输入数组转为np.array
for n in range(batches_count):
train.run(feed_dict={x: input_images[n*batch_size:(n+1)*batch_size], y_: input_labels[n*batch_size:(n+1)*batch_size], keep_prob: 0.5})
if remainder > 0:
start_index = batches_count * batch_size;
train.run(feed_dict={x: input_images[start_index:input_count-1], y_: input_labels[start_index:input_count-1], keep_prob: 0.5})
iterate_accuracy = 0
if it % 5 == 0:
iterate_accuracy = accuracy.eval(feed_dict={x: val_images, y_: val_labels, keep_prob: 1.0})
print('第 %d 次训练迭代: 准确率 %0.5f%%' % (it, iterate_accuracy * 100),cross_entropy)
if iterate_accuracy >= 0.9999 and it >= 150:
break;
saver = tf.train.Saver()
if not os.path.exists('save-vehicle'):
print('不存在训练数据保存目录,现在创建保存目录')
os.makedirs('save-vehicle')
saver_path = saver.save(sess, "%smodel.ckpt"%('save-vehicle-LETTERS/'))
print('完成训练!')
车牌识别合并输出
我这里放上已经训练好的模型,我这里使用GTX1080 用时30秒左右
可以在这下载车牌识别模型
参考了很多大神的操作,这里就不一一指出,望见谅