内存管家
一:项目简介
内存管家是一个内存池,它实现了在多核多线程的环境下,效率较高的处理高并发的内存池。它由三层缓存结构组成,三层缓存分别为ThreadCache、CentralCache、PageCache。ThreadCache可以解决多核多线程环境下,锁的竞争问题;CentralCache可以均衡内存资源;PageCache可以解决内存碎片问题。
内存碎片:在内存分配的过程中会产生内存碎片,而内存碎片分为内碎片与外碎片。
- 内碎片:是指因为在内存中会因为内存对齐的原因,在内存分配过程中,为了要对齐到响应的对齐位置,会造成一定空间的浪费。
- 外碎片:是指在内存分配过程中,当需要一块内存时,可能是从一个大块的内存上切割下来的,不断的切割就会使3内存块变为小的内存块,最后导致无法申请大内存。
二:三层缓存结构
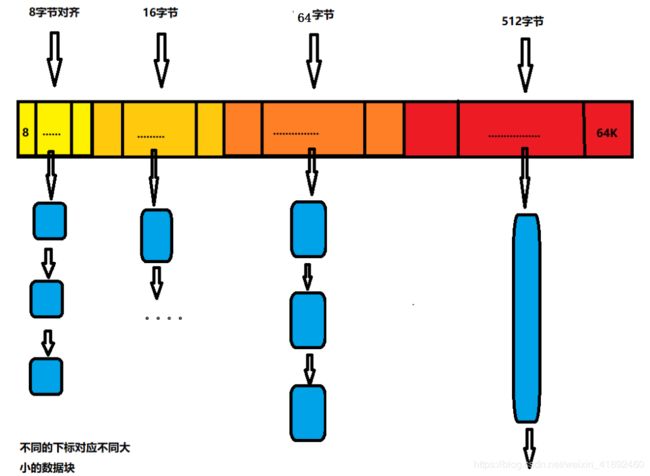
1.ThreadCache
- 第一层为线程缓存,线程直接从这里拿去内存。每个线程都有自己的thread cache,所以不用加锁,这就保证了内存池的高效性。
- 使用哈希映射一个存储不同大小数据块池,通过根据不同大小的对象,构建不同大小的内存的分配器,进行内存的高效分配。
- 根据定长的结构对齐进行改进,将哈希映射的池分为4部分,对齐数分别为8、16、64、512,将这,几部分的内碎片进行一定的控制,从而达到减少内碎片的问题,而外碎片可由第三层解决。
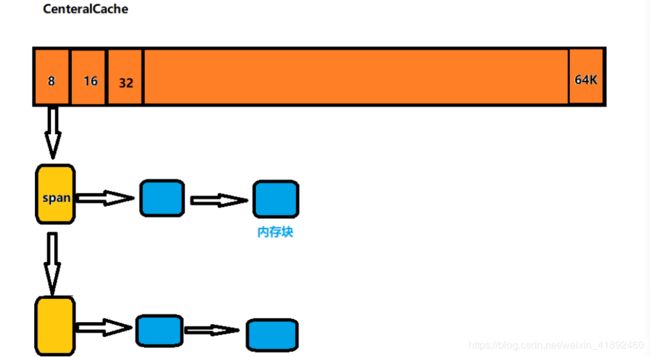
2.CentralCache
- 第一层的线程缓存从该层获取内存对象,每个线程缓存按需从中心缓存获取数据。中心缓存只有一个是所有线程所共享的。
- 中心缓存会周期性的从线程缓存中回收对象,避免因为一个线程占有太多的内存,从而导致其他的线程的内存紧张,因此中心缓存达到了均衡内存的目的,尽可能的保证内存的分配公平合理。
- 中心缓存存在线程安全问题,所以需要加锁进行保护,但是此处的取内存对象效率十分的高,所以不会存在很激烈的锁竞争的问题
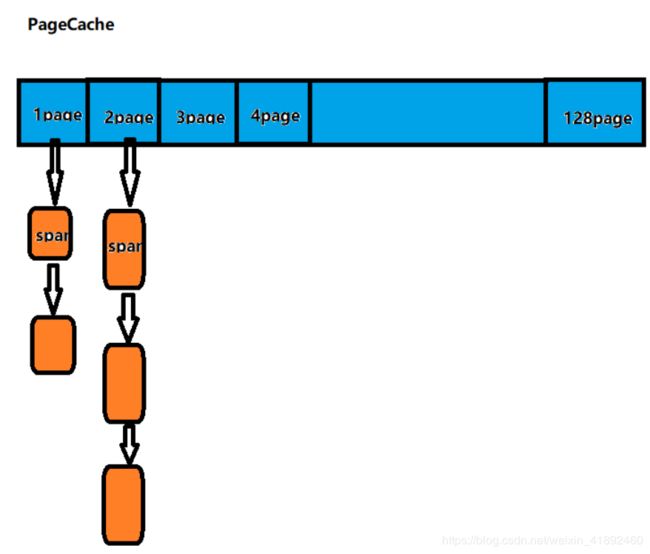
3.PageCache
- 该层处于中心缓存上一层缓存结构,当中心缓存中的内存数据块不够的话,就会从页缓存申请,从而获得内存资源。
- 页缓存是以页为单位进行存储的,通过哈希的映射建立一个缓存池,每个下标对应位置所挂的就是几页的内存块也就是span。
- 在这里通过span来描述连续多个对象数据块的内存,就是一个申请连续内存数据块的集合。
- 当中心缓存区中span满足一定的条件时,PageCache就会对其进行回收,然后进行合并,从而达到
减少内存碎片的目的,当PageCache的内存不够用时,直接向系统堆申请内存。
三:项目的具体实现
1.设计ThreadCache类
class ThreadCache
{
public:
//分配内存
void* Allocate(size_t size);
//释放内存
void Deallocate(void* ptr, size_t size);
//从中心缓存中获取内存对象
void* FetchFromCentralCache(size_t index, size_t size);
//当自由链表中的对象超过一次分配给threadcache的数量,则开始回收
void ListTooLong(FreeList* freelist, size_t byte);
private:
FreeList _freelist[NLISTS];// 创建了一个自由链表数组
};
对于FreeList这个类,我们只要封装一个普通指针和链表的长度即可。
ThreadCache申请内存:
- 只能申请在64k范围以内的大小的内存,如果大于64k,则调用VirtualAlloc直接向系统申请内存。
- 当内存申请size <= 64k 时在thread cache中申请内存,先计算size在自由链表中的位置,如果自由链表中由内存对象时,直接从FreeList[i] 中Pop然后返回对象,时间复杂度为O(1),并且没有锁竞争,效率极高。当FreeList[i]中没有对象时,则批量从CentralCache中获取一定数量的 对象,剩余的n-1个对象插入到自由链表中并返回一个对象。
Thread Cache释放内存:
- 当释放内存小于64k时将内存释放回thread cache,先计算size在自由链表中的位置,然后将对象Push到 FreeList[i]
- 当自由链表的长度超过一次向中心缓存分配的内存块数目时,回收一部分内存对象到Central cache
自由链表的设计
// 控制内碎片浪费不要太大
//[1, 128] 8byte对齐 freelist[0,16)
//[129, 1024] 16byte对齐 freelist[17, 72)
//[1025, 8 * 1024] 64byte对齐 freelist[72, 128)
//[8 * 1024 + 1, 64 * 1024] 512byte对齐 freelist[128, 240)
// 也就是说对于自由链表数组只需要开辟240个空间就可以了
// 大小类
class ClassSize
{
public:
// align是对齐数
static inline size_t _RoundUp(size_t size, size_t align)
{
// 比如size是15 < 128,对齐数align是8,那么要进行向上取整,
// ((15 + 7) / 8) * 8就可以了
// 这个式子就是将(align - 1)加上去,这样的话就可以进一个对齐数
// 然后再将加上去的二进制的低三位设置为0,也就是向上取整了
// 15 + 7 = 22 : 10110 (16 + 4 + 2)
// 7 : 111 ~7 : 000
// 22 & ~7 : 10000 (16)就达到了向上取整的效果
return (size + align - 1) & ~(align - 1);
}
// 向上取整
static inline size_t RoundUp(size_t size)
{
assert(size <= MAXBYTES);
if (size <= 128)
{
return _RoundUp(size, 8);
}
if (size <= 8 * 128)
{
return _RoundUp(size, 16);
}
if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
if (size <= 64 * 1024)
{
return _RoundUp(size, 512);
}
else
{
return -1;
}
}
//求出在该区间的第几个
static size_t _Index(size_t bytes, size_t align_shift)
{
//对于(1 << align_sjift)相当于求出对齐数
//给bytes加上对齐数减一也就是,让其可以跨越到下一个自由链表的数组的元素中
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
//获取自由链表的下标
static inline size_t Index(size_t bytes)
{
//开辟的字节数,必须小于可以开辟的最大的字节数
assert(bytes < MAXBYTES);
//每个对齐区间中,有着多少条自由链表
static int group_array[4] = { 16, 56, 56, 112 };
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024) //(8 * 128)
{
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 4096) //(8 * 8 * 128)
{
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 8 * 128)
{
return _Index(bytes - 4096, 9) + group_array[2] + group_array[1] + group_array[0];
}
else
{
return -1;
}
}
};
2.CentralCache设计
- Central cache本质是由一个哈希映射的span对象自由双向链表构成
- 为了保证全局只有唯一的Central cache,这个类被可以设计成了单例模式
- 单例模式采用饿汉模式,避免高并发下资源的竞争
在此引入了Span:一个Span是由多个页组成的一个span对象。一页大小是4k。
// span结构
// 对于span是为了对于thread cache还回来的内存进行管理
// 一个span中包含了内存块
typedef size_t PageID;
struct Span
{
PageID _pageid = 0; //起始页号(一个span包含多个页)
size_t _npage = 0; //页的数量
Span* _next = nullptr; // 维护双向span链表
Span* _prev = nullptr;
void* _objlist = nullptr; //对象自由链表
size_t _objsize = 0; //记录该span上的内存块的大小
size_t _usecount = 0; //使用计数
};
将span组成的spanlist设计为一个双向链表,插入删除效率增大:
class SpanList
{
public:
// 双向循环带头结点链表
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span* begin()
{
return _head->_next;
}
Span* end()
{
return _head;
}
bool Empty()
{
return _head == _head->_next;
}
void Insert(Span* cur, Span* newspan)
{
assert(cur);
Span* prev = cur->_prev;
//prev newspan cur
prev->_next = newspan;
newspan->_prev = prev;
newspan->_next = cur;
cur->_prev = newspan;
}
void Erase(Span* cur)
{
assert(cur != nullptr && cur != _head);
Span* prev = cur->_prev;
Span* next = cur->_next;
prev->_next = next;
next->_prev = prev;
}
void PushBack(Span* cur)
{
Insert(end(), cur);
}
void PopBack()
{
Span* span = end();
Erase(span);
}
void PushFront(Span* cur)
{
Insert(begin(), cur);
}
Span* PopFront()
{
Span* span = begin();
Erase(span);
return span;
}
// 给每一个Spanlist桶加锁
std::mutex _mtx;
private:
Span * _head = nullptr;
};
CentralCache申请内存:
- 当threadcache中没有内存时,就会批量向CentralCache申请一定数量的内存对象,CentralCache也是一个哈希映射的Spanlist,Spanlist中挂着span,从span中取出对象给threadcache,这个过程是2需要加锁的,可能会存在多个线程同时取对象,会导致线程安全的问题。
- 当CentralCache中没有非空的span时,则将空的span连在一起,然后向PageCache申请一个span对象,span对象中是一些以页为单位的内存,将这个span对象切成需要的内存大小并连接起来,最后挂到CentralCache中。
- CentralCache的每一个span都有一个use_count,分配一个对象给threadcache,就++use_count,当这个span的使用计数为0,说明这个span所有的内存对象都是空闲的,然后将它交给PageCache合并为更大的页,减少内存碎片。
CentralCache释放内存: - 当threadcache过长或者线程销毁,则会将内存释放到CentralCache,每释放一个内存对象,检查该内存所在的span使用计数是否为空,释放回来时–use_count。
- 当use_count减到0时则表示所有对象都回到了span,则将span释放回PageCache,在PageCache中会对前后相邻的空闲页进行合并。
- 在PageCache维护一个页号到span的映射,当PageCache给CentralCache分配一个span时,将这个映射更新到map中去,在ThreadCache还给CentralCache时,可以查map找到对应的span.
3.PageCache
- PageCache是一个以页为单位的span自由链表
- 为了保证全局只有唯一的PageCache,这个类也可以被设计为单例模式(饿汉)
// 采用饿汉模式,在main函数之前单例对象已经被创建
class PageCache
{
public:
// 获取单例模式
static PageCache* GetInstance()
{
return &_inst;
}
// 在SpanList中获取一个span对象,如果没有或者申请内存大于128页,则直接去系统申请
Span* NewSpan(size_t npage);
Span* _NewSpan(size_t npage);
// 获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
// 从CentralCache归还span到Page,然后PageCache进行合并
void RelaseToPageCache(Span* span);
private:
// NPAGES是129,最大页数为128,也就是下标从1开始到128分别为1页到128页
SpanList _pagelist[NPAGES];
private:
PageCache() = default;
PageCache(const PageCache&) = delete;
PageCache& operator=(const PageCache&) = delete;
static PageCache _inst;
// 为了锁住SpanList,可能会存在多个线程同时来PageCache申请span
std::mutex _mtx;
std::unordered_map _id_span_map;
};
PageCache申请内存:
- CentralCache向PageCache申请内存时,PageCache先检查对应位置有没有span,如果没有则向更大页寻找一个span,如果找到则分裂成两个。比如:申请的是4page,4page后面没有挂span,则向后面寻找更大的span,假设在10page位置找到一个span,则将10page span分裂为一个4page span和 一个6page span。
- 如果找到128 page都没有合适的span,则向系统使用mmap、brk(Linux)或者VirtualAlloc(windows)等方式申请128page span挂在自由链表中,再重复1中的过程。
PageCache释放内存: - 如果CentralCache释放回一个span,则依次寻找span的前后page id的span,看是否可以合并,如果能够合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。但是合并的最大页数超过128页,则不能合并。
- 如果ThreadCache想直接申请大于64k的内存,直接去PageCache去申请,当在PageCache申请时,如果申请的内存大于128页,则直接向系统申请这块内存,如果小于128页,则去SpanList去查找。
四:项目内存的申请
1.申请小于64K的空间
- 此时申请的空间在三层缓存空间锁能分配的大小的范围之内,所以就从每个线程的各自的内存池中获取内存。
- 首先根据所申请的空间的大小进行内存对齐找到其对其数,再根据其对其数确定该块空间在内存池中的下标,从中获取内存。
- 如果在threadCache中没有内存,则从第二块内存中获取内存,从中取出相应的块数,返回所需的内存数,将剩余的内存挂到第一层的空闲链表池下。
- 当第二层也没有相应的内存数就从第三层去获取,在内存获取时,通过遍历整个哈希映射表, 找到内存块,如果找到的内存块大于要申请的内存块就及进行分割,返回要申请的内存的大小,将剩余的内存继续挂到第三层。
- 当第三层也没有足够的内存时,就直接从系统内存中进行申请。
2.申请大于64k 且小于 128页的空间
- 因为此时申请的空间大于第二层所能分配的空间,但小于第三层所能分配的最大的空间。所以此时申请时绕过第一层从第三层直接申请
- 释放时也直接将内存释放给第三层
3.申请大于128页的空间
- 直接从系统是申请, 绕过三层的缓存结构
- 释放时直接将该块空间进行释放
五:项目测试
1.50个线程,进行500轮次,每轮次50次
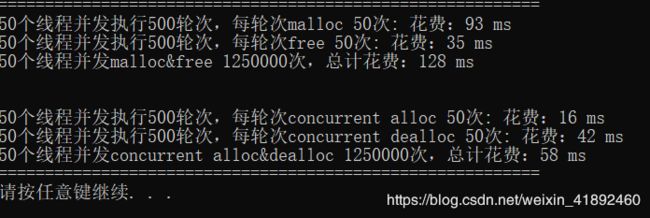
2.50个线程,进行50轮次,每轮次500次
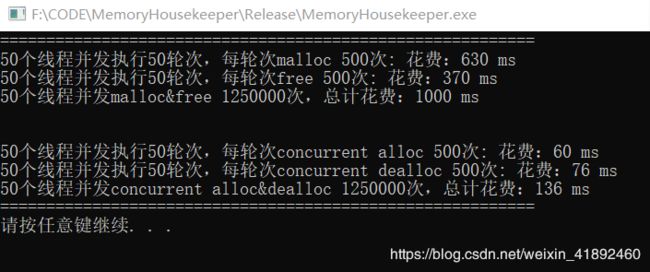
六:项目不足
- 本项目没有完全脱离malloc和free,需要使用new和delete去创建span来维护从系统申请来的堆内存。
- 平台兼容问题:linux系统下面,需要将VirtualAlloc替换为brk。
项目源码:https://github.com/TaoJun724/Project_Memory_House_Keeper