轻轻松松使用StyleGAN(六):StyleGAN Encoder找到真实人脸对应的特征码,核心源代码+中文注释
在上一篇文章中,我们用了四种方法来寻找真实人脸对应的特征码,都没有成功,内容请参考:
https://blog.csdn.net/weixin_41943311/article/details/102952854
而事实上,这个问题在2017年2月就已经被美国加州大学圣迭戈分校的Zachary C Lipton和Subarna Tripathi解决,他们的研究成果发表在下面的网址上:
https://arxiv.org/abs/1702.04782
也可以到百度网盘上下载英文论文《PRECISE RECOVERY OF LATENT VECTORS FROM GENERATIVE ADVERSARIAL NETWORKS》:
https://pan.baidu.com/s/1xCWTD5CA615CHOUS-9ToNA
提取码: wkum
他们把解决办法称之为“stochastic clipping”(随机剪裁),其基本原理大致是:特征码(特征向量)中每个数值通常处于一个有限的空间内,论文指出通常分布在[-1.0, 1.0]这个变动区间内,因此可以从某个特征向量开始(甚至于从全零向量开始),先把超出[-1.0, 1.0]范围的数值剪裁到[-1.0, 1.0]区间,然后以这个特征向量为基准值(平均值),在[-1.0, 1.0]这个变动区间内,按正态分布的规律随机取得新向量,计算新向量通过GAN生成的新图片与原图片之间的损失函数,然后用梯度下降的方法寻找使损失函数最小的最优解。论文指出,他们可以使损失函数降低到0,这样就找到了真实人脸对应的“相当精确”的特征码。
基于这个思想,在github.com 上有若干开源项目提供了源代码,我选用的开源项目是:pbaylies/stylegan-encoder,对应的网址是:
https://github.com/pbaylies/stylegan-encoder
在这个开源项目里,作者把变动区间调整为[-2.0, 2.0]。有读者指出更好的变动区间是 [-0.25, 1.5],在这个区间内能够取得更优的质量。
这个开源项目实现的效果如下图所示(左一为源图;中间是基于预训练ResNet从源图“反向”生成dlatents,然后再用这个dlatents生成的“假脸”图片;右一是经随机剪裁方法最终找到的人脸dlatens,并用这个人脸dlatents生成的极为接近源图的“假脸”):

由于我们得到了人脸对应的dlatents,因此可以操纵这个dlatents,从而可以改变人脸的面部表情。
我们可以按下图所示把整个项目下载到本地,并解压缩之:
在工作目录下,新建.\raw_images目录,并把需要提取特征码的真实人脸图片copy到这个目录下。
使用时,可以按一下步骤操作:
(一)从图片中抽取并对齐人脸:
python align_images.py raw_images/ aligned_images/
(二)找到对齐人脸图片的latent表达:
python encode_images.py aligned_images/ generated_images/ latent_representations/
这个StyleGAN Encoder的核心代码结构如下图所示:
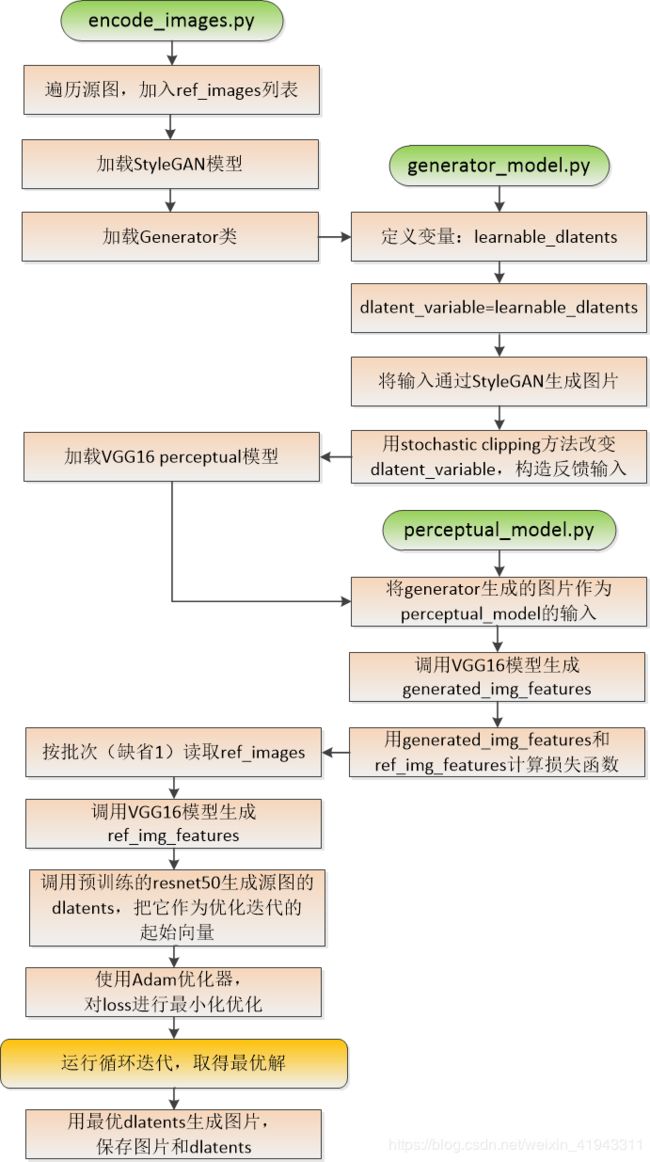
使用中有一些问题要注意:
(1)对显卡内存的要求较高,主页中注明的系统需求如下:
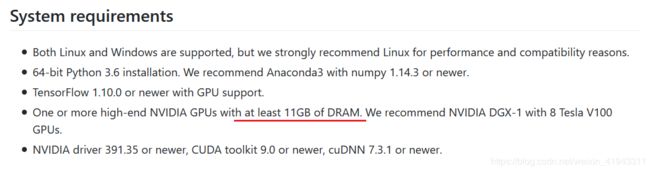
实测,Windows 10 + NVIDIA GeForce RTX 2080Ti 可以运行本项目。
(2)由于不能方便地访问drive.google.com等网站,源代码中的部分资源无法获得,需要提前下载这些资源并修改源代码,包括:
(2.1)预训练的resnet50模型,用于从源图生成优化迭代的初始dlatents,可以从百度网盘下载:
https://pan.baidu.com/s/19ZdGEL5d9J1bpszTJsu0Yw
提取码: zabp
下载以后,将文件copy到工作目录的.\data下
(2.2)预训练的StyleGAN模型,用于从dlatents生成“假”的人脸图片,可以从百度网盘下载:
https://pan.baidu.com/s/1huez99L92_mqbP9sMev5Mw
提取码: jhb5
下载以后,将文件copy到工作目录的.\models下
对应修改的文件是:.\encode_images.py
对应修改的内容如下:
"""
with dnnlib.util.open_url(args.model_url, cache_dir=config.cache_dir) as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
"""
# 加载StyleGAN模型
Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
generator_network, discriminator_network, Gs_network = pickle.load(model_file)
(2.3)预训练的VGG16模型,用于从图片提取features,可以从百度网盘下载:
https://pan.baidu.com/s/1vP6NM9-w4s3Cy6l4T7QpbQ
提取码: 5qkp
下载以后,将文件copy到工作目录的.\models下
对应修改的文件是:.\encode_images.py
对应修改的内容如下:
perc_model = None
if (args.use_lpips_loss > 0.00000001): # '--use_lpips_loss', default = 100
"""
with dnnlib.util.open_url('https://drive.google.com/uc?id=1N2-m9qszOeVC9Tq77WxsLnuWwOedQiD2', cache_dir=config.cache_dir) as f:
perc_model = pickle.load(f)
"""
# 加载VGG16 perceptual模型
Model = './models/vgg16_zhang_perceptual.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
perc_model = pickle.load(model_file)解决以上问题,基本就可以顺利运行了!
完整的带中文注释的源代码如下:
.\encode_images.py
import os
import argparse
import pickle
from tqdm import tqdm
import PIL.Image
import numpy as np
import dnnlib
import dnnlib.tflib as tflib
import config
from encoder.generator_model import Generator
from encoder.perceptual_model import PerceptualModel, load_images
from keras.models import load_model
import glob
import random
def split_to_batches(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
def main():
parser = argparse.ArgumentParser(description='Find latent representation of reference images using perceptual losses', formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('src_dir', help='Directory with images for encoding')
parser.add_argument('generated_images_dir', help='Directory for storing generated images')
parser.add_argument('dlatent_dir', help='Directory for storing dlatent representations')
parser.add_argument('--data_dir', default='data', help='Directory for storing optional models')
parser.add_argument('--mask_dir', default='masks', help='Directory for storing optional masks')
parser.add_argument('--load_last', default='', help='Start with embeddings from directory')
parser.add_argument('--dlatent_avg', default='', help='Use dlatent from file specified here for truncation instead of dlatent_avg from Gs')
parser.add_argument('--model_url', default='https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ', help='Fetch a StyleGAN model to train on from this URL') # karras2019stylegan-ffhq-1024x1024.pkl
parser.add_argument('--model_res', default=1024, help='The dimension of images in the StyleGAN model', type=int)
parser.add_argument('--batch_size', default=1, help='Batch size for generator and perceptual model', type=int)
# Perceptual model params
parser.add_argument('--image_size', default=256, help='Size of images for perceptual model', type=int)
parser.add_argument('--resnet_image_size', default=256, help='Size of images for the Resnet model', type=int)
parser.add_argument('--lr', default=0.02, help='Learning rate for perceptual model', type=float)
parser.add_argument('--decay_rate', default=0.9, help='Decay rate for learning rate', type=float)
parser.add_argument('--iterations', default=100, help='Number of optimization steps for each batch', type=int)
parser.add_argument('--decay_steps', default=10, help='Decay steps for learning rate decay (as a percent of iterations)', type=float)
parser.add_argument('--load_effnet', default='data/finetuned_effnet.h5', help='Model to load for EfficientNet approximation of dlatents')
parser.add_argument('--load_resnet', default='data/finetuned_resnet.h5', help='Model to load for ResNet approximation of dlatents')
# Loss function options
parser.add_argument('--use_vgg_loss', default=0.4, help='Use VGG perceptual loss; 0 to disable, > 0 to scale.', type=float)
parser.add_argument('--use_vgg_layer', default=9, help='Pick which VGG layer to use.', type=int)
parser.add_argument('--use_pixel_loss', default=1.5, help='Use logcosh image pixel loss; 0 to disable, > 0 to scale.', type=float)
parser.add_argument('--use_mssim_loss', default=100, help='Use MS-SIM perceptual loss; 0 to disable, > 0 to scale.', type=float)
parser.add_argument('--use_lpips_loss', default=100, help='Use LPIPS perceptual loss; 0 to disable, > 0 to scale.', type=float)
parser.add_argument('--use_l1_penalty', default=1, help='Use L1 penalty on latents; 0 to disable, > 0 to scale.', type=float)
# Generator params
parser.add_argument('--randomize_noise', default=False, help='Add noise to dlatents during optimization', type=bool)
parser.add_argument('--tile_dlatents', default=False, help='Tile dlatents to use a single vector at each scale', type=bool)
parser.add_argument('--clipping_threshold', default=2.0, help='Stochastic clipping of gradient values outside of this threshold', type=float)
# Masking params
parser.add_argument('--load_mask', default=False, help='Load segmentation masks', type=bool)
parser.add_argument('--face_mask', default=False, help='Generate a mask for predicting only the face area', type=bool)
parser.add_argument('--use_grabcut', default=True, help='Use grabcut algorithm on the face mask to better segment the foreground', type=bool)
parser.add_argument('--scale_mask', default=1.5, help='Look over a wider section of foreground for grabcut', type=float)
# Video params
parser.add_argument('--video_dir', default='videos', help='Directory for storing training videos')
parser.add_argument('--output_video', default=False, help='Generate videos of the optimization process', type=bool)
parser.add_argument('--video_codec', default='MJPG', help='FOURCC-supported video codec name')
parser.add_argument('--video_frame_rate', default=24, help='Video frames per second', type=int)
parser.add_argument('--video_size', default=512, help='Video size in pixels', type=int)
parser.add_argument('--video_skip', default=1, help='Only write every n frames (1 = write every frame)', type=int)
# 获取到基本设置时,如果运行命令中传入了之后才会获取到的其他配置,不会报错;而是将多出来的部分保存起来,留到后面使用
args, other_args = parser.parse_known_args()
# learning rate衰减的steps
args.decay_steps *= 0.01 * args.iterations # Calculate steps as a percent of total iterations
if args.output_video:
import cv2
synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=False), minibatch_size=args.batch_size)
# 找到src_dir下所有图片文件,加入ref_images列表(即:源图的列表;只有一个图片也可以)
ref_images = [os.path.join(args.src_dir, x) for x in os.listdir(args.src_dir)]
ref_images = list(filter(os.path.isfile, ref_images))
if len(ref_images) == 0:
raise Exception('%s is empty' % args.src_dir)
# 创建工作目录
os.makedirs(args.data_dir, exist_ok=True)
os.makedirs(args.mask_dir, exist_ok=True)
os.makedirs(args.generated_images_dir, exist_ok=True)
os.makedirs(args.dlatent_dir, exist_ok=True)
os.makedirs(args.video_dir, exist_ok=True)
# Initialize generator and perceptual model
tflib.init_tf()
"""
with dnnlib.util.open_url(args.model_url, cache_dir=config.cache_dir) as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
"""
# 加载StyleGAN模型
Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
generator_network, discriminator_network, Gs_network = pickle.load(model_file)
# 加载Generator类,参与构建VGG16 perceptual model,用于调用(说是生成,更好理解)generated_image
# generated_image通过perceptual_model转化为generated_img_features,参与计算loss
generator = Generator(Gs_network, args.batch_size, clipping_threshold=args.clipping_threshold, tiled_dlatent=args.tile_dlatents, model_res=args.model_res, randomize_noise=args.randomize_noise)
if (args.dlatent_avg != ''):
generator.set_dlatent_avg(np.load(args.dlatent_avg))
perc_model = None
if (args.use_lpips_loss > 0.00000001): # '--use_lpips_loss', default = 100
"""
with dnnlib.util.open_url('https://drive.google.com/uc?id=1N2-m9qszOeVC9Tq77WxsLnuWwOedQiD2', cache_dir=config.cache_dir) as f:
perc_model = pickle.load(f)
"""
# 加载VGG16 perceptual模型
Model = './models/vgg16_zhang_perceptual.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
perc_model = pickle.load(model_file)
# 创建VGG16 perceptual模型
perceptual_model = PerceptualModel(args, perc_model=perc_model, batch_size=args.batch_size)
perceptual_model.build_perceptual_model(generator)
ff_model = None
# Optimize (only) dlatents by minimizing perceptual loss between reference and generated images in feature space
# tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息
# 把ref_images分割为若干批次,每个批次的大小为args.batch_size,分批使用perceptual_model.optimize()求解每个源图的dlatents的最优解
# 对每一个源图,优化迭代的过程是从一个初始dlatents开始,在某个空间内,按正态分布取值,使用Adam优化器,逐步寻找使loss最小的dlatents,即:stochastic clipping方法
for images_batch in tqdm(split_to_batches(ref_images, args.batch_size), total=len(ref_images)//args.batch_size):
# 读取每个批次中的文件名
names = [os.path.splitext(os.path.basename(x))[0] for x in images_batch]
if args.output_video:
video_out = {}
for name in names:
video_out[name] = cv2.VideoWriter(os.path.join(args.video_dir, f'{name}.avi'),cv2.VideoWriter_fourcc(*args.video_codec), args.video_frame_rate, (args.video_size,args.video_size))
# 给源图及源图用VGG16生成的features赋值(这是计算loss的基准)
perceptual_model.set_reference_images(images_batch)
dlatents = None
if (args.load_last != ''): # load previous dlatents for initialization
for name in names:
dl = np.expand_dims(np.load(os.path.join(args.load_last, f'{name}.npy')),axis=0)
if (dlatents is None):
dlatents = dl
else:
dlatents = np.vstack((dlatents,dl))
else:
if (ff_model is None):
if os.path.exists(args.load_resnet):
print("Loading ResNet Model:")
ff_model = load_model(args.load_resnet)
from keras.applications.resnet50 import preprocess_input
if (ff_model is None):
if os.path.exists(args.load_effnet):
import efficientnet
print("Loading EfficientNet Model:")
ff_model = load_model(args.load_effnet)
from efficientnet import preprocess_input
if (ff_model is not None): # predict initial dlatents with ResNet model
dlatents = ff_model.predict(preprocess_input(load_images(images_batch,image_size=args.resnet_image_size)))
# 设置用于perceptual_model优化迭代的初始值dlatents,它是用resnet50或者efficientnet从源图预测得到的
if dlatents is not None:
generator.set_dlatents(dlatents)
# 对每一个源图,用tqdm构造进度条,显示优化迭代的过程
op = perceptual_model.optimize(generator.dlatent_variable, iterations=args.iterations)
pbar = tqdm(op, leave=False, total=args.iterations)
vid_count = 0
best_loss = None
best_dlatent = None
# 用stochastic clipping方法,使用VGG16 perceptual_model进行优化迭代,迭代次数为iterations=args.iterations
for loss_dict in pbar:
pbar.set_description(" ".join(names) + ": " + "; ".join(["{} {:.4f}".format(k, v)
for k, v in loss_dict.items()]))
if best_loss is None or loss_dict["loss"] < best_loss:
best_loss = loss_dict["loss"]
best_dlatent = generator.get_dlatents()
if args.output_video and (vid_count % args.video_skip == 0):
batch_frames = generator.generate_images()
for i, name in enumerate(names):
video_frame = PIL.Image.fromarray(batch_frames[i], 'RGB').resize((args.video_size,args.video_size),PIL.Image.LANCZOS)
video_out[name].write(cv2.cvtColor(np.array(video_frame).astype('uint8'), cv2.COLOR_RGB2BGR))
# 用stochastic clip方法更新dlatent_variable
generator.stochastic_clip_dlatents()
print(" ".join(names), " Loss {:.4f}".format(best_loss))
if args.output_video:
for name in names:
video_out[name].release()
# Generate images from found dlatents and save them
generator.set_dlatents(best_dlatent)
generated_images = generator.generate_images()
generated_dlatents = generator.get_dlatents()
for img_array, dlatent, img_name in zip(generated_images, generated_dlatents, names):
img = PIL.Image.fromarray(img_array, 'RGB')
img.save(os.path.join(args.generated_images_dir, f'{img_name}.png'), 'PNG')
np.save(os.path.join(args.dlatent_dir, f'{img_name}.npy'), dlatent)
generator.reset_dlatents()
if __name__ == "__main__":
main()
.\encoder\generator_model.py
import math
import tensorflow as tf
import numpy as np
import dnnlib.tflib as tflib
from functools import partial
def create_stub(name, batch_size):
return tf.constant(0, dtype='float32', shape=(batch_size, 0))
# 定义变量learnable_dlatents(batch_size, 18, 512),用于训练
def create_variable_for_generator(name, batch_size, tiled_dlatent, model_scale=18):
if tiled_dlatent:
low_dim_dlatent = tf.get_variable('learnable_dlatents',
shape=(batch_size, 512),
dtype='float32',
initializer=tf.initializers.random_normal())
return tf.tile(tf.expand_dims(low_dim_dlatent, axis=1), [1, model_scale, 1])
else:
return tf.get_variable('learnable_dlatents',
shape=(batch_size, model_scale, 512),
dtype='float32',
initializer=tf.initializers.random_normal())
# StyleGAN生成器,生成batch_size个图片,用于训练模型
class Generator:
# 初始化
def __init__(self, model, batch_size, clipping_threshold=2, tiled_dlatent=False, model_res=1024, randomize_noise=False):
self.batch_size = batch_size
self.tiled_dlatent=tiled_dlatent
self.model_scale = int(2*(math.log(model_res,2)-1)) # For example, 1024 -> 18
# 初始张量为全0(batch_size, 512),通过create_variable_for_generator自定义输入:learnable_dlatents
# functools.partial为偏函数
if tiled_dlatent:
self.initial_dlatents = np.zeros((self.batch_size, 512))
model.components.synthesis.run(np.zeros((self.batch_size, self.model_scale, 512)),
randomize_noise=randomize_noise, minibatch_size=self.batch_size,
custom_inputs=[partial(create_variable_for_generator, batch_size=batch_size, tiled_dlatent=True),
partial(create_stub, batch_size=batch_size)],
structure='fixed')
# 初始张量为全0(batch_size, 18, 512),通过create_variable_for_generator自定义输入:learnable_dlatents
else:
self.initial_dlatents = np.zeros((self.batch_size, self.model_scale, 512))
model.components.synthesis.run(self.initial_dlatents,
randomize_noise=randomize_noise, minibatch_size=self.batch_size,
custom_inputs=[partial(create_variable_for_generator, batch_size=batch_size, tiled_dlatent=False, model_scale=self.model_scale),
partial(create_stub, batch_size=batch_size)],
structure='fixed')
self.dlatent_avg_def = model.get_var('dlatent_avg') # Decay for tracking the moving average of W during training. None = disable.
self.reset_dlatent_avg()
self.sess = tf.get_default_session()
self.graph = tf.get_default_graph()
# 定义dlatent_variable,遍历全局变量的名字空间找到learnable_dlatents
self.dlatent_variable = next(v for v in tf.global_variables() if 'learnable_dlatents' in v.name)
# 定义全零的初始向量,若没有在外部指定训练的初始dlatents,则使用全零向量开始寻找ref_images的dlatents最优解(这估计会很慢,而且不容易收敛)
self.set_dlatents(self.initial_dlatents)
def get_tensor(name):
try:
return self.graph.get_tensor_by_name(name)
except KeyError:
return None
# 定义输出
self.generator_output = get_tensor('G_synthesis_1/_Run/concat:0')
if self.generator_output is None:
self.generator_output = get_tensor('G_synthesis_1/_Run/concat/concat:0')
if self.generator_output is None:
self.generator_output = get_tensor('G_synthesis_1/_Run/concat_1/concat:0')
# If we loaded only Gs and didn't load G or D, then scope "G_synthesis_1" won't exist in the graph.
if self.generator_output is None:
self.generator_output = get_tensor('G_synthesis/_Run/concat:0')
if self.generator_output is None:
self.generator_output = get_tensor('G_synthesis/_Run/concat/concat:0')
if self.generator_output is None:
self.generator_output = get_tensor('G_synthesis/_Run/concat_1/concat:0')
if self.generator_output is None:
for op in self.graph.get_operations():
print(op)
raise Exception("Couldn't find G_synthesis_1/_Run/concat tensor output")
# 定义方法,将输出的张量转换为图片
self.generated_image = tflib.convert_images_to_uint8(self.generator_output, nchw_to_nhwc=True, uint8_cast=False)
self.generated_image_uint8 = tf.saturate_cast(self.generated_image, tf.uint8)
# Implement stochastic clipping similar to what is described in https://arxiv.org/abs/1702.04782
# (Slightly different in that the latent space is normal gaussian here and was uniform in [-1, 1] in that paper,
# so we clip any vector components outside of [-2, 2]. It seems fine, but I haven't done an ablation check.)
# 设定区间[-2, +2]
clipping_mask = tf.math.logical_or(self.dlatent_variable > clipping_threshold, self.dlatent_variable < -clipping_threshold)
# 以dlatent_variable为均值,按正态分布取值,并赋值给clipped_values
clipped_values = tf.where(clipping_mask, tf.random_normal(shape=self.dlatent_variable.shape), self.dlatent_variable)
# 将clipped_values赋值给神经网络图中的变量dlatent_variable,构建优化迭代的反馈输入
self.stochastic_clip_op = tf.assign(self.dlatent_variable, clipped_values)
# 归零
def reset_dlatents(self):
self.set_dlatents(self.initial_dlatents)
# 设置训练开始时的dlatents初始值,将shape统一调整为(batch_size, 512)或者(batch_size, model_scale, 512)
# 将dlatents作为初始值赋给dlatent_variable
def set_dlatents(self, dlatents):
if self.tiled_dlatent:
if (dlatents.shape != (self.batch_size, 512)) and (dlatents.shape[1] != 512):
dlatents = np.mean(dlatents, axis=1)
if (dlatents.shape != (self.batch_size, 512)):
dlatents = np.vstack([dlatents, np.zeros((self.batch_size-dlatents.shape[0], 512))])
assert (dlatents.shape == (self.batch_size, 512))
else:
if (dlatents.shape[1] > self.model_scale):
dlatents = dlatents[:,:self.model_scale,:]
if (dlatents.shape != (self.batch_size, self.model_scale, 512)):
dlatents = np.vstack([dlatents, np.zeros((self.batch_size-dlatents.shape[0], self.model_scale, 512))])
assert (dlatents.shape == (self.batch_size, self.model_scale, 512))
self.sess.run(tf.assign(self.dlatent_variable, dlatents))
# 对dlatent_variable执行stochastic_clip操作
def stochastic_clip_dlatents(self):
self.sess.run(self.stochastic_clip_op)
# 读取dlatent_variable
def get_dlatents(self):
return self.sess.run(self.dlatent_variable)
def get_dlatent_avg(self):
return self.dlatent_avg
def set_dlatent_avg(self, dlatent_avg):
self.dlatent_avg = dlatent_avg
def reset_dlatent_avg(self):
self.dlatent_avg = self.dlatent_avg_def
# 用dlatents生成图片
def generate_images(self, dlatents=None):
if dlatents:
self.set_dlatents(dlatents)
return self.sess.run(self.generated_image_uint8)
.\encoder\perceptual_model.py
import os
import bz2
import PIL.Image
import numpy as np
import tensorflow as tf
from keras.models import Model
from keras.utils import get_file
from keras.applications.vgg16 import VGG16, preprocess_input
import keras.backend as K
import traceback
def load_images(images_list, image_size=256):
loaded_images = list()
for img_path in images_list:
img = PIL.Image.open(img_path).convert('RGB').resize((image_size,image_size),PIL.Image.LANCZOS)
img = np.array(img)
img = np.expand_dims(img, 0)
loaded_images.append(img)
loaded_images = np.vstack(loaded_images)
return loaded_images
def tf_custom_l1_loss(img1,img2):
return tf.math.reduce_mean(tf.math.abs(img2-img1), axis=None)
def tf_custom_logcosh_loss(img1,img2):
return tf.math.reduce_mean(tf.keras.losses.logcosh(img1,img2))
def unpack_bz2(src_path):
data = bz2.BZ2File(src_path).read()
dst_path = src_path[:-4]
with open(dst_path, 'wb') as fp:
fp.write(data)
return dst_path
class PerceptualModel:
# 初始化
def __init__(self, args, batch_size=1, perc_model=None, sess=None):
self.sess = tf.get_default_session() if sess is None else sess
K.set_session(self.sess)
self.epsilon = 0.00000001
self.lr = args.lr
self.decay_rate = args.decay_rate
self.decay_steps = args.decay_steps
self.img_size = args.image_size
self.layer = args.use_vgg_layer #'--use_vgg_layer', default=9
self.vgg_loss = args.use_vgg_loss
self.face_mask = args.face_mask
self.use_grabcut = args.use_grabcut
self.scale_mask = args.scale_mask
self.mask_dir = args.mask_dir
if (self.layer <= 0 or self.vgg_loss <= self.epsilon):
self.vgg_loss = None
self.pixel_loss = args.use_pixel_loss
if (self.pixel_loss <= self.epsilon):
self.pixel_loss = None
self.mssim_loss = args.use_mssim_loss
if (self.mssim_loss <= self.epsilon):
self.mssim_loss = None
self.lpips_loss = args.use_lpips_loss
if (self.lpips_loss <= self.epsilon):
self.lpips_loss = None
self.l1_penalty = args.use_l1_penalty
if (self.l1_penalty <= self.epsilon):
self.l1_penalty = None
self.batch_size = batch_size
if perc_model is not None and self.lpips_loss is not None:
self.perc_model = perc_model
else:
self.perc_model = None
self.ref_img = None
self.ref_weight = None
self.perceptual_model = None
self.ref_img_features = None
self.features_weight = None
self.loss = None
if self.face_mask:
import dlib
self.detector = dlib.get_frontal_face_detector()
# 用于发现人脸框
LANDMARKS_MODEL_URL = 'http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2'
landmarks_model_path = unpack_bz2(get_file('shape_predictor_68_face_landmarks.dat.bz2',
LANDMARKS_MODEL_URL, cache_subdir='temp'))
self.predictor = dlib.shape_predictor(landmarks_model_path)
def compare_images(self,img1,img2):
if self.perc_model is not None:
return self.perc_model.get_output_for(tf.transpose(img1, perm=[0,3,2,1]), tf.transpose(img2, perm=[0,3,2,1]))
return 0
def add_placeholder(self, var_name):
var_val = getattr(self, var_name)
setattr(self, var_name + "_placeholder", tf.placeholder(var_val.dtype, shape=var_val.get_shape()))
setattr(self, var_name + "_op", var_val.assign(getattr(self, var_name + "_placeholder")))
def assign_placeholder(self, var_name, var_val):
self.sess.run(getattr(self, var_name + "_op"), {getattr(self, var_name + "_placeholder"): var_val})
# 创建VGG16 perceptual_model模型
def build_perceptual_model(self, generator):
# Learning rate
global_step = tf.Variable(0, dtype=tf.int32, trainable=False, name="global_step")
incremented_global_step = tf.assign_add(global_step, 1)
self._reset_global_step = tf.assign(global_step, 0) # 从零开始
self.learning_rate = tf.train.exponential_decay(self.lr, incremented_global_step,
self.decay_steps, self.decay_rate, staircase=True)
self.sess.run([self._reset_global_step])
# 由StyleGAN通过输入dlatents不断迭代生成的图片,作为perceptual_model的输入
generated_image_tensor = generator.generated_image
# 使用最近邻插值调整images为(img_size, img_size)
generated_image = tf.image.resize_nearest_neighbor(generated_image_tensor,
(self.img_size, self.img_size), align_corners=True)
# 定义变量ref_img和ref_weight,初始化为0
self.ref_img = tf.get_variable('ref_img', shape=generated_image.shape,
dtype='float32', initializer=tf.initializers.zeros())
self.ref_weight = tf.get_variable('ref_weight', shape=generated_image.shape,
dtype='float32', initializer=tf.initializers.zeros())
# 添加占位符,用于输入数据
self.add_placeholder("ref_img")
self.add_placeholder("ref_weight")
# 调用keras.applications.vgg16的VGG16模型
if (self.vgg_loss is not None):
# 加载VGG16模型
vgg16 = VGG16(include_top=False, input_shape=(self.img_size, self.img_size, 3))
# 定义perceptual_model,vgg16.layers[self.layer].output的shape是(-1, 4, 4, 512)
self.perceptual_model = Model(vgg16.input, vgg16.layers[self.layer].output)
# 用perceptual_model对generated_image进行运算,得到generated_img_features,用于计算loss
# generated_img_features.shape: (batch_size, 4, 4, 512)
generated_img_features = self.perceptual_model(preprocess_input(self.ref_weight * generated_image))
# 定义变量ref_img_features、features_weight
self.ref_img_features = tf.get_variable('ref_img_features', shape=generated_img_features.shape,
dtype='float32', initializer=tf.initializers.zeros())
self.features_weight = tf.get_variable('features_weight', shape=generated_img_features.shape,
dtype='float32', initializer=tf.initializers.zeros())
# 添加占位符,用于输入数据
self.sess.run([self.features_weight.initializer, self.features_weight.initializer])
self.add_placeholder("ref_img_features")
self.add_placeholder("features_weight")
# 计算ref和generated之间的loss
self.loss = 0
# L1 loss on VGG16 features
if (self.vgg_loss is not None):
self.loss += self.vgg_loss * tf_custom_l1_loss(self.features_weight * self.ref_img_features, self.features_weight * generated_img_features)
# + logcosh loss on image pixels
if (self.pixel_loss is not None):
self.loss += self.pixel_loss * tf_custom_logcosh_loss(self.ref_weight * self.ref_img, self.ref_weight * generated_image)
# + MS-SIM loss on image pixels
if (self.mssim_loss is not None):
self.loss += self.mssim_loss * tf.math.reduce_mean(1-tf.image.ssim_multiscale(self.ref_weight * self.ref_img, self.ref_weight * generated_image, 1))
# + extra perceptual loss on image pixels
if self.perc_model is not None and self.lpips_loss is not None:
self.loss += self.lpips_loss * tf.math.reduce_mean(self.compare_images(self.ref_weight * self.ref_img, self.ref_weight * generated_image))
# + L1 penalty on dlatent weights
if self.l1_penalty is not None:
self.loss += self.l1_penalty * 512 * tf.math.reduce_mean(tf.math.abs(generator.dlatent_variable-generator.get_dlatent_avg()))
def generate_face_mask(self, im):
from imutils import face_utils
import cv2
rects = self.detector(im, 1)
# loop over the face detections
for (j, rect) in enumerate(rects):
"""
Determine the facial landmarks for the face region, then convert the facial landmark (x, y)-coordinates to a NumPy array
"""
shape = self.predictor(im, rect)
shape = face_utils.shape_to_np(shape)
# we extract the face
vertices = cv2.convexHull(shape)
mask = np.zeros(im.shape[:2],np.uint8)
cv2.fillConvexPoly(mask, vertices, 1)
if self.use_grabcut:
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (0,0,im.shape[1],im.shape[2])
(x,y),radius = cv2.minEnclosingCircle(vertices)
center = (int(x),int(y))
radius = int(radius*self.scale_mask)
mask = cv2.circle(mask,center,radius,cv2.GC_PR_FGD,-1)
cv2.fillConvexPoly(mask, vertices, cv2.GC_FGD)
cv2.grabCut(im,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1)
return mask
# 加载源图,将loaded_image赋值给ref_img
# 用VGG16生成image_features,并赋值给ref_img_features
def set_reference_images(self, images_list):
assert(len(images_list) != 0 and len(images_list) <= self.batch_size)
# 按照img_size加载图片list
loaded_image = load_images(images_list, self.img_size)
image_features = None
if self.perceptual_model is not None:
# keras中 preprocess_input() 函数完成数据预处理的工作,数据预处理能够提高算法的运行效果。常用的预处理包括数据归一化和白化(whitening)
# predict_on_batch() 本函数在一个batch的样本上对模型进行测试,函数返回模型在一个batch上的预测结果(提取的特征)
image_features = self.perceptual_model.predict_on_batch(preprocess_input(loaded_image))
# weight_mask用于标识len(images_list) <= self.batch_size的情况
weight_mask = np.ones(self.features_weight.shape)
if self.face_mask:
image_mask = np.zeros(self.ref_weight.shape)
for (i, im) in enumerate(loaded_image):
try:
# 读取face_mask文件并转换为array,并赋值给image_mask
_, img_name = os.path.split(images_list[i])
mask_img = os.path.join(self.mask_dir, f'{img_name}')
if (os.path.isfile(mask_img)):
print("Loading mask " + mask_img)
imask = PIL.Image.open(mask_img).convert('L')
mask = np.array(imask)/255
mask = np.expand_dims(mask,axis=-1)
else:
mask = self.generate_face_mask(im)
imask = (255*mask).astype('uint8')
imask = PIL.Image.fromarray(imask, 'L')
print("Saving mask " + mask_img)
imask.save(mask_img, 'PNG')
mask = np.expand_dims(mask,axis=-1)
mask = np.ones(im.shape,np.float32) * mask
except Exception as e:
print("Exception in mask handling for " + mask_img)
traceback.print_exc()
mask = np.ones(im.shape[:2],np.uint8)
mask = np.ones(im.shape,np.float32) * np.expand_dims(mask,axis=-1)
image_mask[i] = mask
img = None
else:
image_mask = np.ones(self.ref_weight.shape)
# 如果images_list中的图片不足batch_size,将不足位置的weight_mask和image_features置为0
if len(images_list) != self.batch_size:
if image_features is not None:
# 将元组转换为列表(可以修改),features_space.shape为(4, 4, 512)
features_space = list(self.features_weight.shape[1:])
existing_features_shape = [len(images_list)] + features_space
empty_features_shape = [self.batch_size - len(images_list)] + features_space
existing_examples = np.ones(shape=existing_features_shape)
empty_examples = np.zeros(shape=empty_features_shape)
weight_mask = np.vstack([existing_examples, empty_examples])
image_features = np.vstack([image_features, np.zeros(empty_features_shape)])
images_space = list(self.ref_weight.shape[1:])
existing_images_space = [len(images_list)] + images_space
empty_images_space = [self.batch_size - len(images_list)] + images_space
existing_images = np.ones(shape=existing_images_space)
empty_images = np.zeros(shape=empty_images_space)
image_mask = image_mask * np.vstack([existing_images, empty_images])
loaded_image = np.vstack([loaded_image, np.zeros(empty_images_space)])
if image_features is not None:
self.assign_placeholder("features_weight", weight_mask)
self.assign_placeholder("ref_img_features", image_features)
self.assign_placeholder("ref_weight", image_mask)
self.assign_placeholder("ref_img", loaded_image)
# 优化迭代
def optimize(self, vars_to_optimize, iterations=100):
# 检查是实例还是列表
vars_to_optimize = vars_to_optimize if isinstance(vars_to_optimize, list) else [vars_to_optimize]
# 使用Adam优化器
optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
# 对loss进行最小化优化
min_op = optimizer.minimize(self.loss, var_list=[vars_to_optimize])
# 初始化变量
self.sess.run(tf.variables_initializer(optimizer.variables()))
# 从0开始
self.sess.run(self._reset_global_step)
# 说明需要运行神经网络图中与min_op, self.loss, self.learning_rate相关的部分
fetch_ops = [min_op, self.loss, self.learning_rate]
# 循环迭代优化
# 带yield的函数是一个生成器,这个生成器有一个函数是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行
for _ in range(iterations):
_, loss, lr = self.sess.run(fetch_ops)
yield {"loss":loss, "lr": lr}
下一篇:
轻轻松松使用StyleGAN(七):用StyleGAN Encoder为女朋友制作美丽头像
(完)