人脸检测-MTCNN算法笔记和代码解读
1 介绍
多任务级联卷积神经网络(MTCNN, Multi-task Cascaded Convolutional Networks)用以同时处理人脸检测和人脸关键点定位(5个关键点)问题,该论文入选2016的ECCV。
最近刚刚开始写博客,欢迎大家评论,如果大家对训练过程有什么问题,欢迎提问,我会积极回答大家的提问。
中文代码解读请参看我的github:https://github.com/luckyluckydadada/MTCNN_tf
如果觉得对您有帮助,github上给点个star,谢谢了。

作者认为人脸检测和人脸关键点检测两个任务之间往往存在着潜在的联系,然而大多数方法都未将两个任务有效的结合起来,本文为了充分利用两任务之间潜在的联系,提出一种多任务级联的人脸检测框架,将人脸检测和人脸关键点检测同时进行。
MTCNN 包含三个级联的多任务卷积神经网络,分别是 Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。
但是三个阶段的侧重点不同:
第一阶段的网络模型称为推荐网络P-Net,主要功能是获得脸部区域的窗口与边界Box回归,获得的脸部区域窗口会通过边界Box回归的结果进行校正,然后使用非最大压制(NMS)合并重叠窗口;
第二阶段的网络模型称为优化网络R-Net,通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口,然后继续校正BoundingBox回归的结果,使用NMS进行合并重叠窗口;
第三阶段的网络模型称为输出网络O-Net,输入第二阶段数据进行更进一步的提取,通过一个能力更加强的网络找到人脸上面的五个标记点。
该模型的特征跟HAAR级联检测在某些程度上有一定的相通之处,都是采用了级联方式,都是在初期就拒绝了绝大多数的图像区域,有效的降低了后期CNN网络的计算量与计算时间。
MTCNN模型主要贡献在于:
1.提供一种基于CNN方式的级联检测方法,基于轻量级的CNN模型就实现了人 脸检测与点位标定,而且性能实时。
2.实现了对难样本挖掘在线训练提升性能
3.一次可以完成多个任务。
2 训练数据集
人脸检测的训练数据可以从 http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/ 下载。
WIDER FACE数据集是人脸检测基准数据集,其中的图像是从公开的WIDER数据集中选择的。选择32,203个图像并标记393,703个面部,数据集基于61个事件类进行组织。对于每个事件类,我们随机选择40%/ 10%/ 50%的数据作为训练,验证和测试集。
其训练集12880个图像,标签文件有两种:
标记文件1为wider_face_train.txt,格式为:
0--Parade/0_Parade_Parade_0_1014 121.69 379.67 131.92 391.39 245.55 378.44 257.67 392.15
第一个数据为文件名:0--Parade/0_Parade_Parade_0_1014.jpg
接下来没四个数据一组,表示一个人脸的BOX:121.69 379.67 131.92 391.39 为第一张脸,245.55 378.44 257.67 392.15 为第二张脸。
标记文件2为wider_face_train_bbx_gt.txt,格式为:
0--Parade/0_Parade_marchingband_1_117.jpg
9
69 359 50 36 1 0 0 0 0 1
227 382 56 43 1 0 1 0 0 1
296 305 44 26 1 0 0 0 0 1
353 280 40 36 2 0 0 0 2 1
885 377 63 41 1 0 0 0 0 1
819 391 34 43 2 0 0 0 1 0
727 342 37 31 2 0 0 0 0 1
598 246 33 29 2 0 0 0 0 1
740 308 45 33 1 0 0 0 2 1
文件名:0--Parade/0_Parade_marchingband_1_117.jpg
标记框的数量:9
边界框:x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
其中 x1,y1 为标记框左上角的坐标,w,h 为标记框的宽度
blur, expression, illumination, invalid, occlusion, pose 为标记框的属性,表示是否模糊,表情,光照情况,是否有效,是否遮挡,姿势
人脸关键点的训练数据可从 http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm 下载。
该数据集包含 5,590 张 LFW 数据集的图片和 7,876 张从网站下载的图片。如下所示:

标记文件的格式为:
lfw_5590\Abbas_Kiarostami_0001.jpg 75 165 87 177 106.750000 108.250000 143.750000 108.750000 131.250000 127.250000 106.250000 155.250000 142.750000 155.250000
第一个数据为文件名:lfw_5590\Abbas_Kiarostami_0001.jpg
第二和第三个数据为标记框左上角坐标: 75 165
第四和第五个数据为标记框长宽: 87 177
第六和第七个数据为左眼标记点:106.750000 108.250000
第八和第九个数据为右眼标记点:143.750000 108.750000
第十和第十一个数据为鼻子标记点:131.250000 127.250000
第十二和第十三个数据为左嘴标记点:106.250000 155.250000
第十四和第十五个数据为右嘴标记点:142.750000 155.250000
3 代码实现
汇总:https://github.com/open-face/mtcnn
- MTCNN的TensorFlow实现可以参考我的github:https://github.com/luckyluckydadada/MTCNN_tf (中文注释完整,含详细训练过程)
- Matlab + Caffe:https://github.com/kpzhang93/MTCNN_face_detection_alignment (论文作者)
- Caffe:https://github.com/dlunion/mtcnn
- TensorFlow:https://github.com/davidsandberg/facenet (被经常调用的tf版mtcnn) https://github.com/davidsandberg/facenet/blob/master/src/align/detect_face.py
4 训练流程
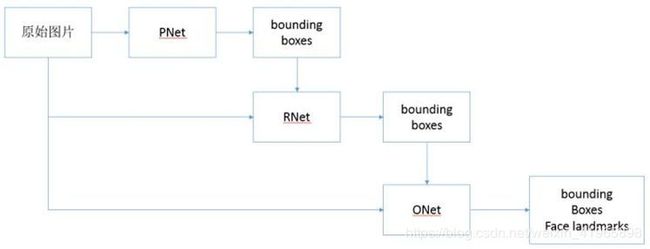
输入原始图片和 PNet 生成预测的 bounding boxes。
输入原始图片和 PNet 生成的 bounding box,通过 RNet,生成校正后的 bounding box。
输入原始图片和 RNet 生成的 bounding box,通过 ONet,生成校正后的 bounding box 和人脸面部轮廓关键点。
在训练阶段数据被分为四种类型:
负样本:并交比小于0.3
正样本:并交比大于0.65
部分脸:并交比在0.4~0.65之间
Landmark脸:能够找到五个landmark位置的
其中在负样本与部分脸之间并没有明显的差异鸿沟,作者选择0.3与0.4作为区间。
正负样本被用来实现人脸分类任务训练
正样本与部分脸样本训练BB回归
Landmark脸用来训练人脸五个点位置定位
整个训练数的比例如下:
负样本:正样本:部分脸:landmark脸=3:1:1:2
5 网络结构
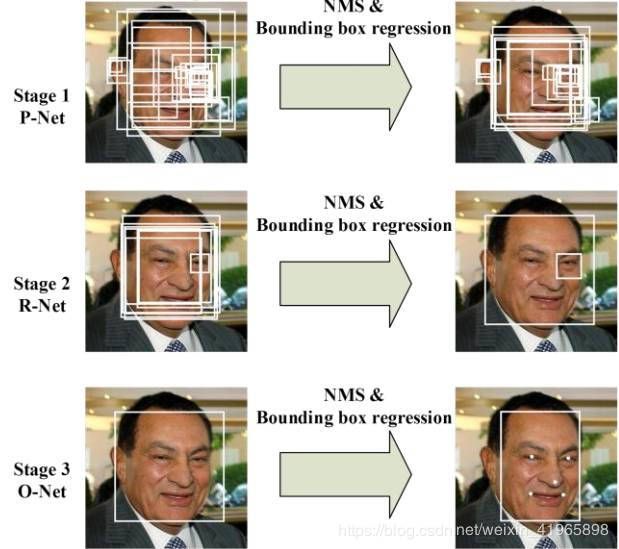
照片会按照不同的缩放比例,缩放成不同大小的图片,形成图片的特征金字塔。
网络实现人脸检测(人脸分类、边框回归)和关键点定位分为三个阶段:
第一阶段:
由 P-Net 获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。
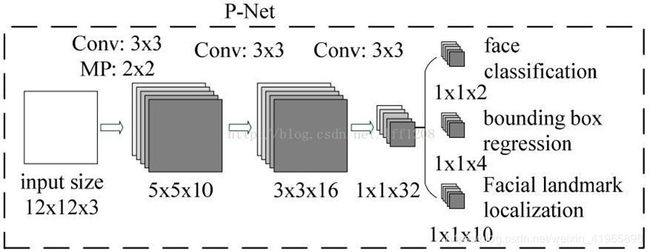
1 该训练网络的输入是一个 12×12 大小的图片,所以训练前需要生成 PNet 网络的训练数据。
训练数据可以通过和 Guarantee True Box 的 IOU 的计算生成一系列的 bounding box。可以通过滑动窗口或者随机采样的方法获取训练数据,训练数据分为三种正样本,负样本,中间样本。其中正阳本是生成的滑动窗口和 Guarantee True Box 的 IOU 大于 0.65,负样本是 IOU 小于 0.3,中间样本是 IOU 大于 0.4 小于 0.65。
然后把 bounding box resize 成 12×12 大小的图片,转换成 12×12×3 的结构,生成 PNet 网络的训练数据。
2 训练数据通过 10 个 3×3×3 的卷积核,2×2 的 Max Pooling(stride=2)操作,生成 10 个 5×5 的特征图。
3 接着通过 16 个 3×3×10 的卷积核,生成 16 个 3×3 的特征图。
4 接着通过 32 个 3×3×16 的卷积核,生成 32 个 1×1 的特征图。
5 最后针对 32 个 1×1 的特征图:(最后这一步依然是卷积,不是全连接)
通过 2 个 1×1×32 的卷积核,生成 2 个 1×1 的特征图用于分类;
通过 4 个 1×1×32 的卷积核,生成 4 个 1×1 的特征图用于回归框判断;
通过10 个 1×1×32 的卷积核,生成 10 个 1×1 的特征图用于特征点的判断。
第二阶段, P-Net 得出的候选框作为输入,输入到 R-Net,网络最后选用全连接的方式进行训练,利用边界框向量微调候选窗体,再利用NMS去除重叠窗体。。
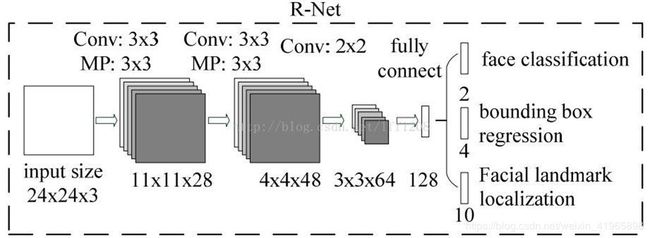
1 RNet 的训练数据生成类似于 PNet,检测数据为图片经过 PNet 网络后,检测出来的 bounding boxes,包括正样本,负样本和中间样本。
2 模型输入为 24×24 大小的图片,通过 28 个 3×3×3 的卷积核和 3×3(stride=2)的 max pooling 后生成 28 个 11×11 的特征图;
3 通过 48 个 3×3×28 的卷积核和 3×3(stride=2)的 max pooling 后生成 48 个 4×4 的特征图;
4 通过 64 个 2×2×48 的卷积核后,生成 64 个 3×3 的特征图;
5 把 3×3×64 的特征图转换为 128 大小的全连接层;
6 最后接入不同大小全连接层:
对回归框分类问题转换为大小为 2 的全连接层;
对 bounding box 的位置回归问题,转换为大小为 4 的全连接层;
对人脸轮廓关键点转换为大小为 10 的全连接层。
第三阶段,使用更加强大的CNN( O-Net),网络结构比R-Net多一层卷积,功能与R-Net作用一样,只是在去除重叠候选窗口的同时,显示五个人脸关键点定位。ONet 是网络的最后输出。
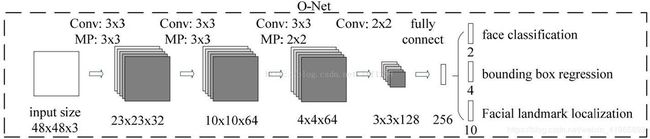
1 ONet 的训练数据生成类似于 RNet,检测数据为图片经过 PNet 和 RNet 网络后,检测出来的 bounding boxes,包括正样本,负样本和中间样本。
2 模型输入是一个 48×48×3 大小的图片,通过 32 个 3×3×3 的卷积核和 3×3(stride=2)的 max pooling 后转换为 32 个 23×23 的特征图;
3 通过 64 个 3×3×32 的卷积核和 3×3(stride=2)的 max pooling 后转换为 64 个 10×10 的特征图;
4 通过 64 个 3×3×64 的卷积核和 3×3(stride=2)的 max pooling 后转换为 64 个 4×4 的特征图;
5 通过 128 个 2×2×64 的卷积核转换为 128 个 3×3 的特征图;
6 通过全链接操作转换为 256 大小的全链接层;
7 最后接入不同大小全连接层:
大小为 2 的回归框分类特征;
大小为 4 的回归框位置的回归特征;
大小为 10 的人脸轮廓关键点回归特征。
6 损失函数

7 Trike :在线hard-negative-mining
为了提升网络性能,需要hard-negative-mining,传统方法是通过研究训练好的模型进行挑选,而本文提出一种能在训练过程中进行挑选困难样本的在线挑选方法。
1 在 mini-batch 中,对每个样本的损失进行排序,挑选前 70% 较大的损失对应的样本作为困难样本。
2 在反向传播时,忽略那 30% 的样本,因为那 30% 样本对更新作用不大。
在P-Net中对人脸进行二元分类时候就可以在线进行难样本挖掘(hard-negative-mining),在网络前向传播时候对每个样本计算得到的损失进行排序(从高到低)然后选择70%进行反向传播,原因在于好的样本对网络的性能提升有限,只有那些难样本才能更加有效训练,进行反向传播之后才会更好的提升整个网络的人脸检测准确率。作者的对比实验数据表明这样做可以有效提升准确率。
8 结果
MTCNN 在人脸检测数据集 FDDB 和 WIDER FACE 以及人脸关键点定位数据集 LFPW 均获得当时最佳成绩。
在运行时间方面,采用 2.60GHz 的 CPU 可以达到 16fps,采用 Nvidia Titan Black 可达 99fps。