Python金融大数据分析——第10章 推断统计学 笔记1
- 第10章 推断统计学
- 10.1 随机数
- 10.2 模拟
- 10.2.1 随机变量
- 10.2.2 随机过程
- 几何布朗运动
- 平方根扩散
- 随机波动率
- 跳跃扩散
- 10.2.3 方差缩减
第10章 推断统计学
Python金融大数据分析——第10章 推断统计学 笔记1
Python金融大数据分析——第10章 推断统计学 笔记2
Python金融大数据分析——第10章 推断统计学 笔记3
10.1 随机数
import numpy as np
import numpy.random as random
import matplotlib.pyplot as plt
# rand 函数返回开区间[O, 1 )内的随机数,随机数的个数由参数指定
random.rand(10)
# array([ 0.43812444, 0.34411735, 0.23250114, 0.76714005, 0.20759936,
# 0.70901672, 0.95422155, 0.08556689, 0.59033963, 0.84513443])
random.rand(5, 5)
# array([[ 0.95942423, 0.91671855, 0.33619313, 0.37931534, 0.59388659],
# [ 0.84503838, 0.92572621, 0.57089753, 0.84832724, 0.6923007 ],
# [ 0.0257402 , 0.73027026, 0.07831274, 0.85126426, 0.43927961],
# [ 0.31733426, 0.0367936 , 0.26154412, 0.68299204, 0.06117947],
# [ 0.3355343 , 0.72317741, 0.95397264, 0.91341195, 0.8424168 ]])
# 如果想生成区间[5, 10 )内的随机数, 可以这样转换 rand 的返回值
a = 5.
b = 10.
random.rand(10) * (b - a) + a
# array([ 7.72031281, 9.49373699, 7.26951207, 5.08434385, 7.07330462,
# 5.5169059 , 7.93266969, 9.59174389, 7.55476132, 9.07963314])
# 由于 NumPy 的广播特性, 这也适合于多维数组
random.rand(5, 5) * (b - a) + a
# array([[ 6.56262146, 6.58686089, 9.25527619, 7.36295298, 8.10034672],
# [ 9.51719011, 8.79297476, 7.32629772, 8.85443737, 6.95337673],
# [ 9.87850678, 8.87835651, 5.55394611, 9.09984161, 7.46512384],
# [ 8.54888728, 8.34351926, 7.95810147, 6.20483389, 8.86515313],
# [ 9.37562883, 5.81284007, 8.34719867, 6.14204529, 7.31620939]])
简单随机数生成函数
| 函数 | 参数 | 描述 |
|---|---|---|
| rand | d0,d1,…,dn | 指定组成的随机数 |
| rndn | d0,d1,…,dn | 来自标准正态分布的一个(或者多个)样本 |
| randint | low[, high, size] | 从low (含)到high (不含)的随矶整数 |
| random_integers | low[, high, size] | low和nigh (含)之间的随机整数 |
| random_sample | [ size] | 半开区间[0.0, 1.0)内的随机浮点数 |
| random | [ size] | 半开区间[0.0, 1.0)内的随机浮点数 |
| ranf | [ size] | 半开区间 [0.0, 1.0)内的随机浮点数 |
| sample | [ size] | 半开区间[0.0, 1.0)内的随机浮点数 |
| choice | a[, size, replace, p] | 给定一维数组中的随机样本 |
| bytes | length | 随机字节 |
sample_size = 500
rn1 = random.rand(sample_size, 3)
rn2 = random.randint(0, 10, sample_size)
rn3 = random.sample(size=sample_size)
a = [0, 25, 50, 75, 100]
rn4 = random.choice(a, size=sample_size)
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(7, 7))
ax1.hist(rn1, bins=25, stacked=True)
ax1.set_title('rand')
ax1.set_ylabel('frequency')
ax1.grid(True)
ax2.hist(rn2, bins=25)
ax2.set_title('randint')
ax2.grid(True)
ax3.hist(rn3, bins=25)
ax3.set_title('sample')
ax3.set_ylabel('frequency')
ax3.grid(True)
ax4.hist(rn4, bins=25)
ax4.set_title('choice')
ax4.grid(True)
根据不同分布生成随机数的函数
| 函数 | 参数 | 描述 |
|---|---|---|
| beta | a, b[, size] | [0,1]区间上的β分布样本 |
| binomial | n,p[, size] | 二项分布样本 |
| chisquare | df[, size] | 卡方分布样本 |
| dirichlet | alpha[, size] | 狄利克雷分布样本 |
| exponential | [ scale,size] | 指数分布样本 |
| f | dfnum, dfden[, size] | F分布样本 |
| gamma | shape[, scale, size] | γ分布样本 |
| geometic | p[, size] | 集合分布样本 |
| gumbel | [loc, scale, size] | 刚贝尔分布样本 |
| hypergeometric | ngood,nbad, nsample[,size] | 超几何分布样本 |
| laplace | [ loc, scale,size] | 拉普拉斯分布或者双指数分布样本 |
| Logistic | [ loc,scale, size] | 逻羁分布样本 |
| lognormalv | [ mean, sigma. size] | 对数正态分布样本 |
| logseries | p[,size] | 对数序列分布样本 |
| multinomial | n,pvals[, size] | 多项分布样样本 |
| multivaiate_normal | mean, cov[, size] | 多变量正态分布样本 |
| negative_binomial | n, p[, size] | 负二项式分布样本 |
| noncentral_chisquare | df, nonc[, size] | 非中心卡方分布样本 |
| noncentral_f | dfnum, dfden1 none[, size] | 非中心F分布样本 |
| normal | [ loc, scale, size] | 正态(高斯)分布样本 |
| pareto | a[, size] | 特定组成的帕累托II或者洛马克思分布样本 |
| poisson | [lam,size] | 泊松分布 |
| power | a[,size] | [0,1]区间内指数为正(a-1)的幂次分布样本 |
| Rayleigh | [ scale,size] | 瑞利分布样本 |
| standard_cauchy | [ size] | 标准柯西分布(模式0)样本 |
| Standard_exponential | [ size] | 标准指数分布样本 |
| standard_gamma | shape[, size] | 标准γ分布样本 |
| standard_nonnal | [ size] | 标准正态分布(均值为0,标准差为1)样本 |
| standard_t | df[, size] | 学生的t分布样本(自由度为df) |
| triangular | left, mode, right[, size] | 三角分布样本 |
| uniform | [ low, high, size] | 均匀分布样本 |
| vonmises | mu, kappa[, size] | 冯·米塞斯分布样本 |
| wald | mean, scale[, size] | 瓦尔德(逆高斯)分布样本 |
| weibull | a[, size] | 戚布尔分布样本 |
| zipf | a[, size] | 齐夫分布样本 |
虽然在金融学中使用(标准)正态分布遭到了许多批评 , 但是它们是不可或缺的工具,在分析和数值应用中仍然是最广泛使用的分布类型。 原因之一是许多金融模型直接依赖于正态分布或者对数正态分布。 另一个原因是许多不直接依赖(对数)正态假设的金融模型可以离散化, 从而通过使用正态分布进行近似模拟。
sample_size = 500
rn1 = random.standard_normal(sample_size) # 均值为0, 标准差为l的标准正态分布
rn2 = random.normal(100, 20, sample_size) # 均值为 100 , 标准差为 20 的正态分布
rn3 = random.chisquare(df=0.5, size=sample_size) # 自由度为 0.5 的卡方分布
rn4 = random.poisson(lam=1.0, size=sample_size) # λ 值为 1 的泊松分布
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(7, 7))
ax1.hist(rn1, bins=25)
ax1.set_title('standard normal')
ax1.set_ylabel('frequency')
ax1.grid(True)
ax2.hist(rn2, bins=25)
ax2.set_title('normal(100,20)')
ax2.grid(True)
ax3.hist(rn3, bins=25)
ax3.set_title('chi square')
ax3.set_ylabel('frequency')
ax3.grid(True)
ax4.hist(rn4, bins=25)
ax4.set_title('Poisson')
ax4.grid(True)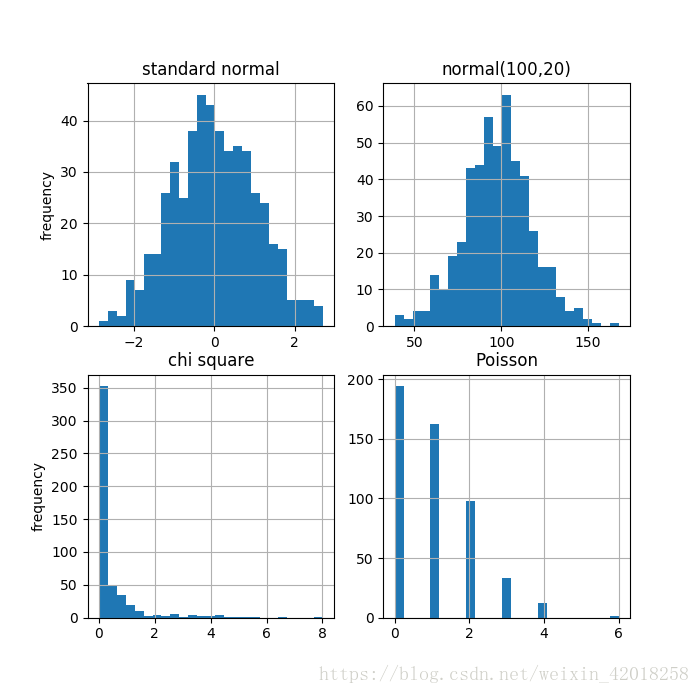
10.2 模拟
蒙特卡洛模拟(MCS)是金融学中最重要的数值技术之一(在重要性和使用广泛程度上也许没有 “之一” }。这主要是因为它是最灵活的数学表达式(如积分)求值方法,特别适合于金融、衍生品的估值。 但是,这种灵活性的代价是相对高的计算负担,估算一个值就可能需要数十万次甚至数百万次复杂计算。
10.2.1 随机变量
我们考虑期权定价所用的Black-Scholes-Meron设置。这种设置中,在今日股票指数水平 S0 S 0 给定的情况下,未来某个日期T的股票指数水平 ST S T
公式:以Black-Scholes-Merton设置模拟未来指数水平
ST S T :T日的指数水平
r :恒定无风险短期利率
σ σ :S的恒定波动率(= 收益率的标准差)
z:标准正态分布随机变量
import numpy as np
import numpy.random as random
import matplotlib.pyplot as plt
S0 = 100 # initial value
r = 0.05 # constant short rate
sigma = 0.25 # constant volatility
T = 2.0 # in years
I = 10000 # number of random draws
ST1 = S0 * np.exp((r - 0.5 * sigma ** 2) * T + sigma * np.sqrt(T) * random.standard_normal(I))
plt.hist(ST1, bins=50)
plt.xlabel('index level')
plt.ylabel('frequency')
plt.grid(True)( 通过 standard_normal ) 模拟的几何布朗运动

随机变量呈对数正态分布。因此 , 我们还可以尝试使用 lognormal 函数直接得出随机变量值。在这种情况下,必须向函数提供均值和标准差:
ST2 = S0 * random.lognormal((r - 0.5 * sigma ** 2) * T, sigma * np.sqrt(T), size=I)
plt.hist(ST2, bins=50)
plt.xlabel('index level')
plt.ylabel('frequency')
plt.grid(True)
( 通过 lognormal ) 模拟的几何布朗运动

使用 scipy.stats子库和下面定义的助手函数 print_statistics 比较模拟结果的分布特性:
import scipy.stats as scs
def print_statistics(a1, a2):
"""
Print selected statistics
"""
sta1 = scs.describe(a1)
sta2 = scs.describe(a2)
print('%14s %14s %14s' % ('statistic', 'data set 1', 'data set 2'))
print(45 * '-')
print('%14s %14.3f %14.3f' % ('size', sta1[0], sta2[0]))
print('%14s %14.3f %14.3f' % ('min', sta1[1][0], sta2[1][0]))
print('%14s %14.3f %14.3f' % ('max', sta1[1][1], sta2[1][1]))
print('%14s %14.3f %14.3f' % ('mean', sta1[2], sta2[2]))
print('%14s %14.3f %14.3f' % ('std', np.sqrt(sta1[3]), np.sqrt(sta2[3])))
print('%14s %14.3f %14.3f' % ('skew', sta1[4], sta2[4]))
print('%14s %14.3f %14.3f' % ('kurtosis', sta1[5], sta2[5]))
print_statistics(ST1, ST2)
# statistic data set 1 data set 2
# ---------------------------------------------
# size 10000.000 10000.000
# min 28.691 28.718
# max 497.050 438.493
# mean 110.298 111.023
# std 40.380 40.577
# skew 1.145 1.156
# kurtosis 2.668 2.428
两个模拟结果的特性很类似, 差异主要是由于模拟中的所谓采样误差。在离散地模拟连续随机过程时会引人离散化误差, 但是由于模拟方法的特性,这种误差在此不起任何作用。
10.2.2 随机过程
粗略地讲, 随机过程是一个随机变量序列。在这个意义上, 我们应该预期, 在模拟一个过程时, 对一个随机变量的一序列重复模拟应该有某种类似之处。 这个结论大体上是正确的 ,但是随机数的选取一般不是独立的?而是依赖于前几次选取的结果。 不过,金融学中使用的随机过程通常表现出马尔科夫特性——主要的含义是:明天的过程值只依赖于今天的过程状态, 而不依赖其他任何 “历史” 状态. 甚至不依赖整个路径历史。 这种过程也被称做 “无记忆过程”。
几何布朗运动
现在我们考虑Black-Scholes-Merton模型的动态形式,这种形式由下面公式中的随机微分方程(SDE)描述。式中的 Zt Z t 是标准布朗运动,SDE 被称作几何布朗运动。 St S t 的值呈对数正态分布,(边际)收益 dSt/St d S t / S t 呈正态分布。
公式 Black-Scholes-Merton设置中的随机微分方程
SDE可以由一个欧拉格式精确地离散化, 下面公式中介绍了一个这样的格式, 其中 Δt Δ t 是固定的离散化间隔, zt z t 是标准正态分布随机变量。
I = 10000
M = 50
dt = T / M
S = np.zeros((M + 1, I))
S[0] = S0
for t in range(1, M + 1):
S[t] = S[t - 1] * np.exp((r - 0.5 * sigma ** 2) * dt + sigma * np.sqrt(dt) * random.standard_normal(I))
plt.hist(S[-1], bins=50)
plt.xlabel('index level')
plt.ylabel('frequency')
plt.grid(True)
到期日的模拟几何布朗运动

print_statistics(S[-1], ST2)
# statistic data set 1 data set 2
# ---------------------------------------------
# size 10000.000 10000.000
# min 28.421 28.718
# max 379.855 438.493
# mean 110.613 111.023
# std 40.392 40.577
# skew 1.145 1.156
# kurtosis 2.413 2.428前四个统计和静态模拟方法得出的结果相当接近。
展示了前10条模拟路径:
plt.plot(S[:, :10], lw=1.5)
plt.xlabel('time')
plt.ylabel('index level')
plt.grid(True)模拟几何布朗运动路径
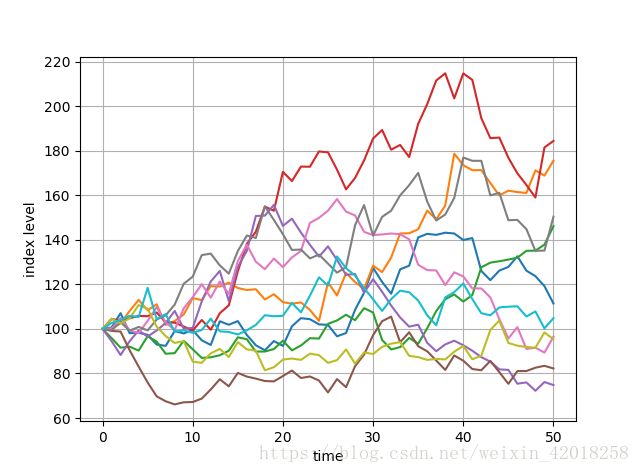
使用动态模拟方怯不仅可以像上图那样可视化路径,还可以估算美式/百慕大期权或者收益与路径相关的期权价值。 可以这么说, 你所得到的是全动态图像。
平方根扩散
另一类重要的金融过程是均值回归过程,用于建立短期利率或者波动性过程的模型。流行和广泛使用的模型之 一是平方根扩散 公式提供了对应的SDE。
公式 平方根扩散的随机微分方程
xt x t :日期 t 的过程水平
k : 均值回归因子
θ θ :长期过程均值
σ σ :恒定波动率参数
Z :标准布朗运动
众所周知, xt x t 的值呈卡方分布。但是,许多金融模型可以使用正态分布进行离散化和近似计算(即所谓的欧拉离散化格式)。虽然欧拉格式对几何布朗运动很准确 ,但是对于大部分其他随机过程则会产生偏差。即使有精确的格式,因为数值化或者计算的原因,使欧拉格式可能最合适。定义 s≡t−Δt s ≡ t − Δ t 和 x+≡max(x,0) x + ≡ m a x ( x , 0 ) ,下面公式提出了一种欧拉格式。这种特殊格式在文献中通常称作完全截断。
公式 平方根扩散的欧拉离散化
我们用可以表示短期利率模型的值参数化后续模拟所用的模型:
x0 = 0.05
kappa = 3.0
theta = 0.02
sigma = 0.1平方根扩散有方便和实际的特性—— xt x t 的值严格为正。用欧拉格式离散化时,负值无法排除。这就是人们处理的总是原始模拟过程整数版本的原因。因此在模拟代码中,需要两个ndarray对象:
I = 10000
M = 50
dt = T / M
def srd_euler():
xh = np.zeros((M + 1, I))
x1 = np.zeros_like(xh)
xh[0] = x0
x1[0] = x0
for t in range(1, M + 1):
xh[t] = (xh[t - 1]
+ kappa * (theta - np.maximum(xh[t - 1], 0)) * dt
+ sigma * np.sqrt(np.maximum(xh[t - 1], 0)) * np.sqrt(dt)
* random.standard_normal(I))
x1 = np.maximum(xh, 0)
return x1
x1 = srd_euler()
plt.hist(x1[-1], bins=50)
plt.xlabel('value')
plt.ylabel('frequency')
plt.grid(True)
到期日的模拟平方根扩散(欧拉格式)

plt.plot(x1[:, :10], lw=1.5)
plt.xlabel('time')
plt.ylabel('index level')
plt.grid(True)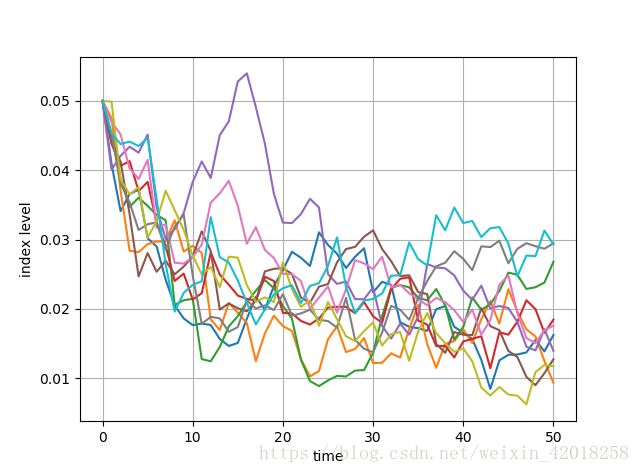
前 10 条模拟路径,说明得出的平均偏离值为负值(因为 x0>θ x 0 > θ )并收敛于 θ=0.02 θ = 0.02 。
现在我们寻求更精确的结果。下面公式提出了基于自由度 df=4θκσ2 d f = 4 θ κ σ 2 ,非中心参数 nc=4κe−κΔtσ2(1−e−κΔt)xs n c = 4 κ e − κ Δ t σ 2 ( 1 − e − κ Δ t ) x s 的卡方分布 χ′2d χ d ′ 2 平方根扩散的精准离散化格式。
公式 平方根扩散的精确离散化
def srd_exact():
x2 = np.zeros((M + 1, I))
x2[0] = x0
for t in range(1, M + 1):
df = 4 * theta * kappa / sigma ** 2
c = (sigma ** 2 * (1 - np.exp(-kappa * dt))) / (4 * kappa)
nc = np.exp(-kappa * dt) / c * x2[t - 1]
x2[t] = c * random.noncentral_chisquare(df, nc, size=I)
return x2
x2 = srd_euler()
plt.hist(x2[-1], bins=50)
plt.xlabel('value')
plt.ylabel('frequency')
plt.grid(True)到期日的模拟平方根扩散(精确格式)

plt.plot(x2[:, :10], lw=1.5)
plt.xlabel('time')
plt.ylabel('index level')
plt.grid(True)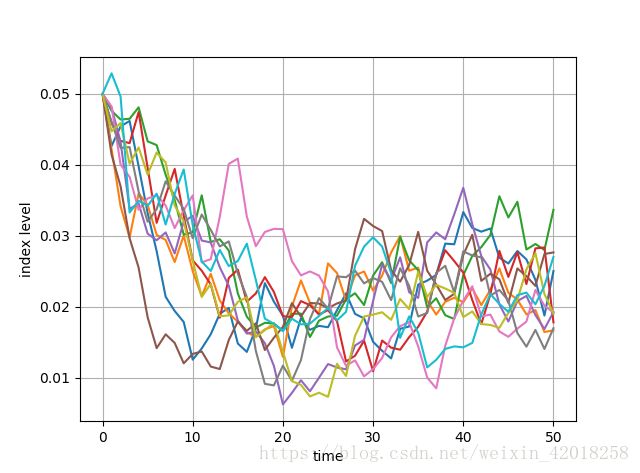
比较不同方法中的主要统计数字可以看出, 偏置欧拉格式确实很好地表现出理想的统计属性:
print_statistics(x1[-1], x2[-1])
# statistic data set 1 data set 2
# ---------------------------------------------
# size 10000.000 10000.000
# min 0.005 0.004
# max 0.050 0.053
# mean 0.020 0.020
# std 0.006 0.006
# skew 0.545 0.625
# kurtosis 0.477 0.744在执行速度方面可以观察到重大的差异。这是因为从非中心卡方分布中采样的计算要求高于标准正态分布的采样。为了说明这一点, 我们考虑更大的模拟路径数量:
I=250000
%time x1=srd_euler()
# Wall time: 2.33 s
%time x2=srd_exact()
# Wall time: 3.9 s
# 精确格式大约需要花费2倍的时间,而结果实际上和欧拉格式相同
print_statistics(x1[-1], x2[-1])
# statistic data set 1 data set 2
# ---------------------------------------------
# size 250000.000 250000.000
# min 0.003 0.004
# max 0.058 0.056
# mean 0.020 0.020
# std 0.006 0.006
# skew 0.556 0.573
# kurtosis 0.454 0.479随机波动率
Black-Scholes-Meron模型中重要的简化假设之一是恒定波动率。但是, 波动率一般来说既不是恒定的、也不具确定性, 而是随机的。 因此,20世纪90年代初金融模型的重大进步之一是所谓随机波动率模型的推出。 这一类别中最为流行的模型之一是Heston ( 1993 )模型:
公式 Heston随机流动率模型的随机徽分方程
单一变量和参数的均值现在很容易从几何布朗运动和平方根扩散的讨论中得出。参数 ρ ρ 代表两个标准布朗运动 Z1t Z t 1 , Z2t Z t 2 之间的瞬时相关性。这使我们可以解释一个典型事实——杠杆效应, 该效应本质上指的是波动性在困难时期(衰退市场)中上升, 而在牛市(上升市场)时下降。
S0 = 100.
r = 0.05
v0 = 0.1
kappa = 3.0
theta = 0.25
sigma = 0.1
rho = 0.6
T = 1.0
# 为了说明两个随机过程之间的相关性,我们需要确定相关矩阵的柯列斯基分解:
corr_mat = np.zeros((2, 2))
corr_mat[0, :] = [1.0, rho]
corr_mat[1, :] = [rho, 1.0]
cho_mat = np.linalg.cholesky(corr_mat)
cho_mat
# array([[ 1. , 0. ],
# [ 0.6, 0.8]])
# 在开始模拟随机过程之前, 我们为两个过程生成整组随机数, 指数过程使用第0组,波动性过程使用第1组:
M = 50
I = 10000
ran_num = random.standard_normal((2, M + 1, I))
# 对于以平方根扩散过程类型建模的波动性过程, 我们使用欧拉格式, 考虑相关性参数:
dt = T / M
v = np.zeros_like(ran_num[0])
vh = np.zeros_like(v)
v[0] = v0
vh[0] = v0
for t in range(1, M + 1):
ran = np.dot(cho_mat, ran_num[:, t, :])
vh[t] = (vh[t - 1] + kappa * (theta - np.maximum(vh[t - 1], 0)) * dt
+ sigma * np.sqrt(np.maximum(vh[t - 1], 0)) * np.sqrt(dt)
* ran[1])
v = np.maximum(vh, 0)
# 对于指数水平过程, 我们也考虑相关性,使用几何布朗运动的精确欧拉格式:
S = np.zeros_like(ran_num[0])
S[0] = S0
for t in range(1, M + 1):
ran = np.dot(cho_mat, ran_num[:, t, :])
S[t] = S[t - 1] * np.exp((r - 0.5 * v[t]) * dt +
np.sqrt(v[t]) * ran[0] * np.sqrt(dt))
# 这说明了平方根扩散中使用欧拉格式的另一项优势:相关性很容易一致性地处理, 因为我们只提取标准正态随机数。 没有一种棍合方法(对指数使用欧拉格式, 对波动性过程使用基于非中心卡方分布的精确方法)能够实现相同的效果。
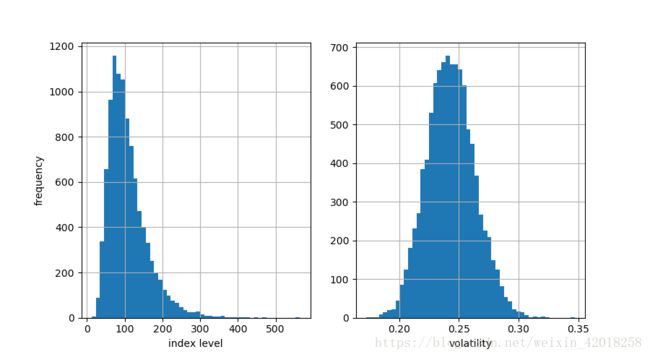
# 用直方图展了指数水平过程和波动性过程的模拟结果
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(9, 5))
ax1.hist(S[-1], bins=50)
ax1.set_xlabel('index level')
ax1.set_ylabel('frequency')
ax1.grid(True)
ax2.hist(v[-1], bins=50)
ax2.set_xlabel('volatility')
ax2.grid(True)
到期日的模拟随机波动率模型
fig, (ax1, ax2) = plt.subplots(2,1,sharex=True, figsize=(7, 6))
ax1.plot(S[:,:10],lw=1.5)
ax1.set_ylabel('index level')
ax1.grid(True)
ax2.plot(v[:,:10],lw=1.5)
ax2.set_xlabel('time')
ax2.set_ylabel('volatility')
ax2.grid(True)模拟随机波动率模型路径

对每个过程的前10条模拟路径的检查表明, 波动性过程的平均漂移值为正数, 和预期的一样收敛于 θv=0.25 θ v = 0.25
最后, 我们简短地看着两个数据集最后一个时间点的统计数字,该时点显示指数水平过程有一个相当高的最大值。实际上,在其他条件不变的情况下,这个最大值远大于固定披动率下几何布朗运动所能达到的最大值:
print_statistics(S[-1], v[-1])
# statistic data set 1 data set 2
# ---------------------------------------------
# size 10000.000 10000.000
# min 12.331 0.173
# max 564.115 0.347
# mean 108.235 0.243
# std 52.066 0.020
# skew 1.592 0.160
# kurtosis 4.572 0.059
跳跃扩散
随机波动率和杠杆效应是在许多市场上都能发现的典型(经验主义)事实。另一种典型的经验主义事实是资产价格和波动率的跳跃。1976年, Meron发布了他的跳跃扩散模型, 模型的一个部分以对数正态分布生成跳跃, 改进了Black-Scholes-Merton设置。
风险中立SDE如下:
公式 Meron跳跃扩散模型的随分方程
St S t :t日的指数水平
r:恒定无风险短期利率
rJ≡λ⋅(eμJ+δ2/2−1) r J ≡ λ ⋅ ( e μ J + δ 2 / 2 − 1 ) 维持风险中立性的跳跃漂移校正
σ σ :S的恒定波动率
Zt Z t :标准布朗运动
Jt J t :t日呈……分布的跳跃
log(1+Jt)≈N(log(1+μJ)−δ22,δ2) l o g ( 1 + J t ) ≈ N ( l o g ( 1 + μ J ) − δ 2 2 , δ 2 )
N是标准正态随机变量的累积分布函数
Nt N t :密度为 λ λ 的泊松分布
下面公式介绍一种用于跳跃扩散的欧拉离散化公式,其中 znt z t n 呈标准正态分布,yt呈密度为λ的泊松分布。
公式 Meron跳跃扩散模型的欧拉离散化
S0 = 100.
r = 0.05
sigma = 0.2
lamb = 0.75
mu = -0.6
delta = 0.25
T = 1.0
# 为了模拟跳跃扩散,需要生成3组(独立)随机数:
M=50
I=10000
rj=lamb*(np.exp(mu+0.5*delta**2)-1)
S=np.zeros((M+1,I))
S[0]=S0
sn1=random.standard_normal((M+1,I))
sn2=random.standard_normal((M+1,I))
poi=random.poisson(lamb*dt,(M+1,I))
for t in range(1,M+1,1):
S[t]=S[t-1]*(np.exp((r-rj-0.5*sigma**2)*dt
+sigma*np.sqrt(dt)*sn1[t])
+(np.exp(mu+delta*sn2[t])-1)
*poi[t])
S[t]=np.maximum(S[t],0)
plt.hist(S[-1], bins=50)
plt.xlabel('value')
plt.ylabel('frequency')
plt.grid(True)到期日的模拟跳跃扩散

由于我们已经假定跳跃的均值为很大的负数, 最终的模拟指数水平与典型正态分布相比更向右倾斜也就不足为奇了。
plt.plot(S[:, :10], lw=1.5)
plt.xlabel('time')
plt.ylabel('index level')
plt.grid(True)模拟跳跃扩散路径

在前10 条模拟指数水平路径中也可以看到负数的跳跃均值
10.2.3 方差缩减
目前为止, 我们得到的结果表现出来的统计数值和预期/理想值并不足够接近, 这不仅是因为使用的Python函数生成的是伪随机数。还因为提取的样本大小各不相同。例如,你可能预期一组标准正态分布随机数的均值为0,标准差为1。我们来看看不同组随机
数的统计数字。为了实现逼真的比较,我们修改随机数生成器的种子值:
print("%15s %15s" %('Mean','Std.Deviation'))
print(31*"-")
for i in range(1,31,2):
random.seed(1000)
sn=random.standard_normal(i**2*10000)
print("%15.12f %15.12f" %(sn.mean(),sn.std()))
# Mean Std.Deviation
# -------------------------------
# -0.011870394558 1.008752430725
# -0.002815667298 1.002729536352
# -0.003847776704 1.000594044165
# -0.003058113374 1.001086345326
# -0.001685126538 1.001630849589
# -0.001175212007 1.001347684642
# -0.000803969036 1.000159081432
# -0.000601970954 0.999506522127
# -0.000147787693 0.999571756099
# -0.000313035581 0.999646153704
# -0.000178447061 0.999677277878
# 0.000096501709 0.999684346792
# -0.000135677013 0.999823841902
i**2*10000
# 8410000结果显示, 提取随机数的个数越多, 统计数值就 “莫名其妙” 地变得越好。但即使在最大的样本(超过 800 万个随机数)中, 统计数值也不等于理想的数字。
幸运的是, 可以使用易于实现的通用方差缩减方法,改善(标准)正态分布前两个统计的匹配。第 一种技术是使用对偶变量,这种方法只提取理想数量一半的随机数,并在之后加人同 一组随机数的相反数,例如, 如果随机数生成器(即对应的 Python
函数)提取 0.5。则在数据集中加入另 一个值-0.5。这里描述的方只适用于对称中位为0的随机变量,比如标准正态分布随机变量。
print("%15s %15s" %('Mean','Std.Deviation'))
print(31*"-")
for i in range(1,31,2):
random.seed(1000)
sn=random.standard_normal(i**2*5000)
sn=np.concatenate((sn,-sn))
print("%15.12f %15.12f" %(sn.mean(),sn.std()))
# Mean Std.Deviation
# -------------------------------
# 0.000000000000 1.009653753942
# -0.000000000000 1.000413716783
# 0.000000000000 1.002925061201
# -0.000000000000 1.000755212673
# 0.000000000000 1.001636910076
# -0.000000000000 1.000726758438
# -0.000000000000 1.001621265149
# 0.000000000000 1.001203722778
# -0.000000000000 1.000556669784
# 0.000000000000 1.000113464185
# -0.000000000000 0.999435175324
# 0.000000000000 0.999356961431
# -0.000000000000 0.999641436845
# -0.000000000000 0.999642768905
# -0.000000000000 0.999638303451立刻就会注意到, 这种方法完美地更正了第一个统计矩一这并不令人惊讶, 原因在于每当提取敬n时,就加人-n。因为我们有了这样的配对,整组随机数的均值就会等于0。然而, 这种方法对第二个统计矩一一准差没有任何影响。
使用另一种方差缩减技术一一矩匹配, 有助于在一个步骤中更正第一个和第二个统计矩。从每个随机数中减去均值并将每个随机数除以标准差, 就可以得到一组匹配随机数 ,(几乎)完美地匹配理想的标准正态分布第一和第二统计矩:
sn = random.standard_normal(10000)
sn.mean()
# -0.001165998295162494
sn.std()
# 0.99125592020460496
sn_new = (sn - sn.mean()) / sn.std()
sn_new.mean()
# -2.3803181647963357e-17
sn_new.std()
# 0.99999999999999989下面的函数利用对方差缩减技术的认识, 用两种 、 一种或者不用方差缩减技术生成用于过程模拟的标准正态随机数:
def gen_sn(M, I, anti_paths=True, mo_math=True):
"""
Function to generate random numbers for simulation
:param M: number of time intervals for discretization
:param I: number of paths to be simulated
:param anti_paths: use of antithetic variates
:param mo_math: use of moment matching
:return:
"""
if anti_paths is True:
sn = random.standard_normal((M + 1, int(I / 2)))
sn = np.concatenate((sn, -sn), axis=1)
else:
sn = random.standard_normal((M + 1, I))
if mo_math is True:
sn = (sn - sn.mean()) / sn.std()
return sn未完待续……