小目标检测算法Stitcher | Stitcher: Feedback-driven Data Provider for Object Detection
刚出来的小目标检测论文
论文地址:https://arxiv.org/pdf/2004.12432.pdf

Abstract:
目标检测器通常会根据尺寸具有不同质量,其中小物体的性能最不令人满意。在本文中,我们研究了这种现象,并发现:在大多数训练迭代中,小目标的损失对总损失几乎没有贡献,导致优化不平衡导致性能下降。受此启发,我们提出Stitcher,它是一种反馈驱动的数据提供者,旨在以平衡的方式训练目标检测器。在Stitcher中,将图像调整为较小的分量,然后将其拼接为与常规图像相同的尺寸。拼接图像不可避免的包含较小目标,这对于我们的核心思想将是有益的,以利用损失统计信息作为反馈来指导下一次迭代更新。已经对各种检测器,主干网络,训练周期,数据集甚至实例分割进行了实验。在所有设置中,尤其是对于小型目标,Stitcher稳定地大幅提高了性能,而在训练和测试阶段几乎没有引入任何额外的计算。
Introduction:
小目标检测一直是个难题,论文对问题的原因进行了分析:
1.Image level Analysis

目标检测COCO数据集中,小目标占据了41.4%的比例,远多于中大型目标,这个应该是有利于小目标检测的。然而,数据集中只有52.3%的图片包含小目标。意味着接近一半的图像是不包含小目标的。这种严重的失衡阻碍了模型的训练过程。

如果将常规图像调整为较小的尺寸,则内部的中型或大型目标也将变为较小的目标,但是其轮廓或细节仍然比原始的小型目标更清晰。从图4中可以看出,原图中的小目标和经过resize后的目标尺寸分别为29 x 31和30 x 30,大小基本一致,但是后者图像更清晰。
2.Training Level Analysis
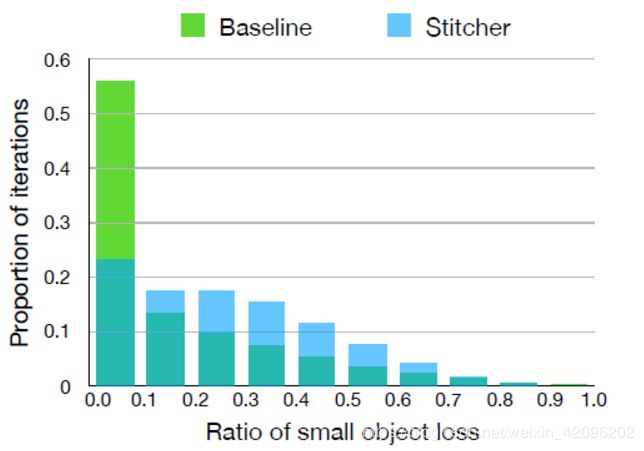
小物体在图像上的分布不均匀,因此使训练遭受进一步的失衡问题。 即使某些图像中包含小物体,它们仍然有机会在训练过程中被忽略。 图1说明,在超过50%的迭代中,小目标损失占总数的不到10%。 训练损失主要是大中型物体。 因此,用于小物体的监督信号不足,严重损害了小物体的准确性甚至整体性能。
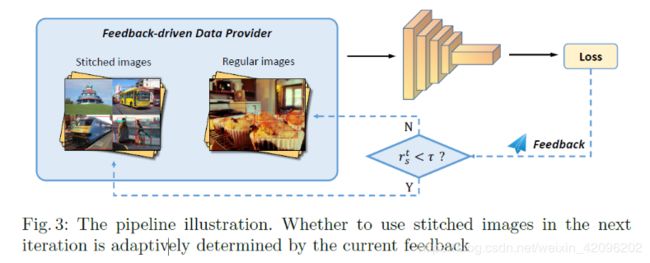
因此,本文提出了一种Stitcher,一种反馈驱动的数据提供者,它通过以反馈的方式利用训练损失来增强对象检测的性能。在Stitcher中,我们引入的拼接图像大小与常规图像相同。 核心思想是利用当前迭代中的损耗统计信息作为反馈,以自适应地确定下一次的输入选择。
具体如下图所示,如果在当前迭代t中小对象rts的损失比可忽略不计,则迭代t +1的输入是拼接图像,其中拼接图像中较小的对象不可避免地会更加丰富。 否则,输入将在默认设置下保留常规图像。
Stitcher:
主要包含Image Level Operations与Training Level Module两个阶段:
1.Image Level Operations - Component Stitching

为了解决数据集中小物体监督信号不足的问题,使用Stitching动态地生成拼接图像或常规图像来丰富小目标。具体操作为,给定输入图像resize到统一的尺寸,然后利用参数k个图像进行拼接,并保留了原有图像的宽高比。保持宽高比的原因是可以保留原始对象的属性。 当将k设为1时,将自然图像引入到拼接图像中。将k的缝合顺序指定为4,我们可以看到图5(b)中的示例。 在图像拼接的帮助下,通过制造更多的小物体,图像批处理(充当最小训练实体)的比例失衡得到缓解。 由于拼接图像的大小与常规图像相同,因此不会在网络传播中引入其他计算。
2.Training Level Module - Selection Paradigm
图1中已经分析出在网络的训练过程中,超过50%的迭代小目标损失占比低于0.1。为了避免这种不希望的趋势,论文提出了一种正确的范例,根据当前遍历的反馈确定下一次迭代的输入。 如果小目标象的损失在迭代t中可以忽略不计(低于阈值y),则我们认为关于小对象的知识还远远不够。 为了弥补信息的不足,我们采用拼接图像作为迭代t + 1的输入。否则,将选择常规图像。
如何计算小目标损失占比呢?论文采用以下公式:
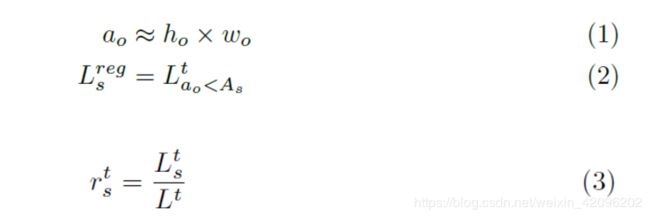
即box的面积定义为h x w,当面积 < 1024时(32 x 32),则该Box的回归损失定义小目标损失(后续的消融实验分析了损失部分的选取),就可算出其比例。
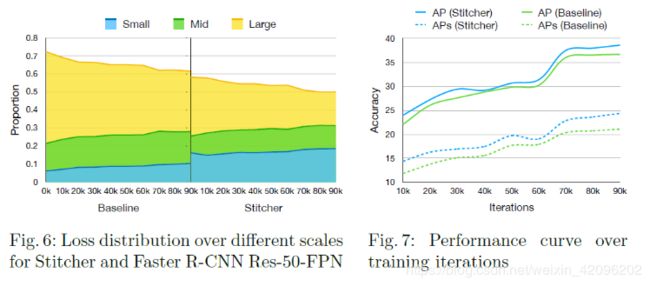
论文将图6中的损失分布比较和图7中的性能差异可视化。每10k次迭代测量一次统计数据,并平滑地进行说明。 它表明,使用Stitcher,各种规模的损失分布更加平衡,从而提高了精度。
Time Complexity分析:

上图可以看出,总训练时间而言,用ResNet-50-FPN主干训练基线,更快的RCNN大约需要8.7个小时。 如果在相同的GPU上计时,则Stitcher的时间会延长约一刻钟。 当应用较大的主干网络时,此间隙会缩小。
In Context of Literature:
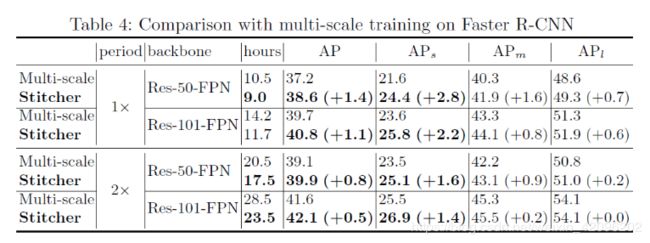
1.Multi-scale Image Pyramid:类似于多尺度训练,Stitcher还被设计为针对尺度变化更强大地渲染特征。 但是,有两个本质区别:
(1)STITCHER既不需要图像金字塔结构,也不需要调整输入大小。 拼接图像仍具有与常规图像相同的大小,从而极大地减轻了图像金字塔中不可避免的计算负担。
(2)STITCHER中的目标尺寸由训练迭代中的损失分布自适应确定。 相反,在图像金字塔中,在每次迭代中随机选择不同大小的图像。 与多尺度训练相比,这将显着提高性能。
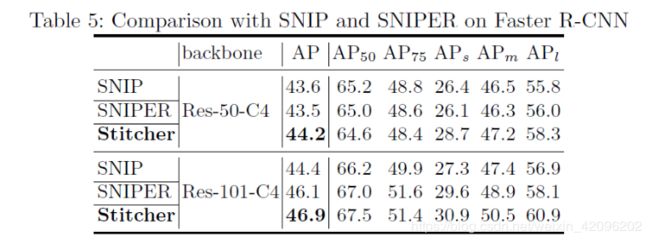
2.SNIP and SNIPER:Stitcher的操作与SNIPER的操作本质上不同。 SNIPER中的截取操作要复杂得多,这就需要计算gt box与crops之间的重叠量(IoU),以便进行标签分配。 但是,Stitcher中的操作仅涉及插值和拼接。 此外,由于SNIP和SNIPER依赖于多尺度测试。
3.Mixup and Auto Augmentation:Stitcher效果更优
Experiments:
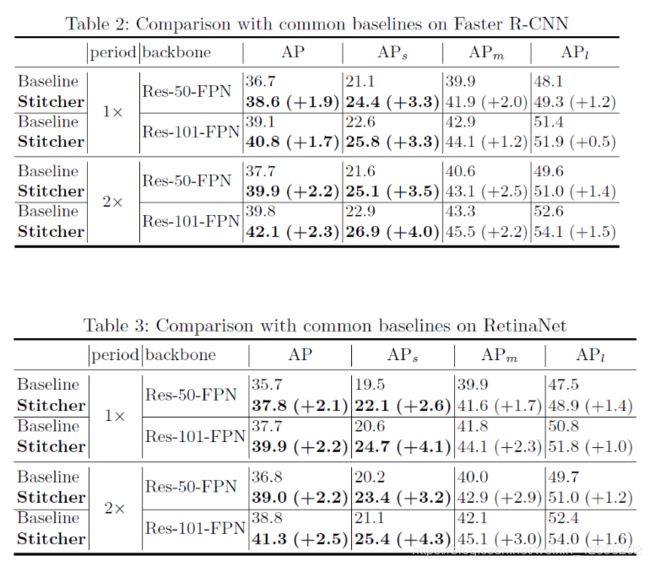
1.Faster-RCNN与RetinaNet比较:
2.vs multi-scale training:
3.vs SNIP and SNIPER:
4.Ablation study: