强化学习、联邦学习、图神经网络,飞桨全新工具组件详解
2019-12-05 14:55:36
机器之心发布
机器之心编辑部
11 月 5 日,在 Wave Summit+2019 秋季深度学习开发者峰会上,飞桨全新发布和重要升级了最新的 21 项进展,在深度学习开发者社区引起了巨大的反响。
很多未到场的开发者觉得遗憾,希望可以了解飞桨发布会背后的更多技术细节,因此我们特别策划了一个系列稿件,分别从核心框架、基础模型库、端到端开发套件、工具组件和服务平台五个层面分别详细解读飞桨的核心技术与最新进展,敬请关注。
今天给大家带来的是系列文章之飞桨工具组件解读。
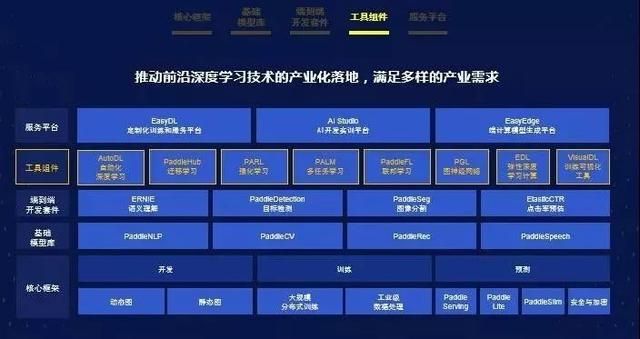
飞桨深度学习平台工具组件,包括 PaddleHub 迁移学习、PARL 强化学习、PALM 多任务学习、PaddleFL 联邦学习、PGL 图神经网络、EDL 弹性深度学习计算、AutoDL 自动化深度学习、VisualDL 训练可视化工具等,旨在推动前沿深度学习技术的产业化落地,满足多样的产业需求。下面带来飞桨深度学习平台工具组件详细解读,核心内容 3993 字,预计阅读时间 4 分钟。
PaddleHub 迁移学习
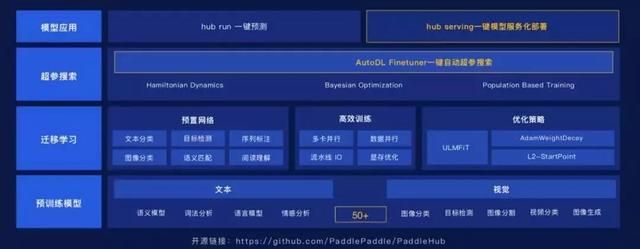
PaddleHub 是预训练模型管理和迁移学习工具。开发者通过使用预训练模型,可以更便捷地开展迁移学习工作。PaddleHub 主要有以下特点:
丰富的预训练模型库
飞桨的预训练模型库,目前主要覆盖自然语言处理和计算机视觉两个方向,包含图像分类、目标检测、词法分析、语义模型、情感分析、语言模型、视频分类、图像生成、图像分割等 70 多个技术领先的而且经过长期的产业实践验证的优质模型,可以帮助开发者快速开始。
少量代码即可完成迁移学习
PaddleHub Fine-tune API 的开发,目的是帮助开发者降低迁移学习的门槛。在预训练模型的领域,我们可以认为模型都是标准化的,有标准化的输入,也有标准化的输出,跟软件是样的模块化。通过自定义数据集,再加上 Fine-tune API,组网的工作可以通过一行代码搞定,而且 PaddleHub 集成了工业级简单实用的策略,包括数据的预处理等,可供开发者尝试。同时,引入『模型即软件』的设计理念,通过 Python API 或者命令行实现一键预测,更方便地应用飞桨模型库。

支持超参优化,自动搜索超参数
PaddleHub AutoDL Finetuner 提供一个黑盒优化的策略,目标是用尽可能少的次数来找到一个更好的超参,使得我们的模型在验证集上的指标更好。这个问题没有很明确的公式描述,因此需要通过黑盒优化的技术来求解:通过定义一个超参的类型和范围,让机器来自动搜索,而且对于任意的机器学习的代码都可以使用黑盒优化,可以帮助开发者提高整个超参优化的效率。
通过 Hub Serving,实现一键 Module 服务化部署
Hub Serving 是为用户端到端体验打造的,从预训练模型快速的生成 API 的服务,可以实现安全可控、支持私有化的部署。开发者可以基于 PaddleHub 开放的模型在自己的企业内部搭建起预训练模型和服务,并通过 API 调用的方式快速接入。客户端的应用方式非常简单,通过我们最经典的 HTTP 的方式,可以快速的使用这些预训练模型,让更多的人能够用到预训练模型的效果。
更多内容,请参考:https://github.com/PaddlePaddle/PaddleHub
PALM 多任务学习
PaddlePALM (PAddLe for Multi-task) 是一个强大快速、灵活易用的任务级(task level)多任务学习框架,用户仅需书写极少量代码即可完成复杂的多任务训练与推理。PALM 框架实现了简洁易懂的任务实例创建与管理机制,强大易用的参数管理与复用接口,以及高效稳定的多任务调度算法。此外,框架提供了定制化接口,若内置工具、主干网络和任务无法满足需求,开发者可以轻松完成相关组件的自定义。框架中内置了丰富的主干网络及其预训练模型(BERT、ERNIE 等)、常见的任务范式(分类、匹配、机器阅读理解等)和相应的数据集读取与处理工具。框架运行的基本原理图如下图所示:
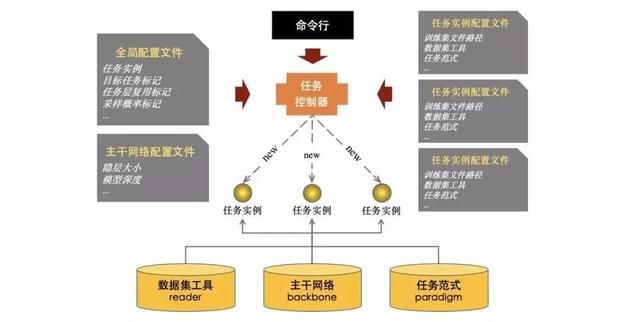
框架支持基于配置和基于 API 这两种使用方式。对于典型的多任务学习场景,用户可以从内置的 reader、backbone 和 paradigm 池中自由组合出任务实例,而后基于参数管理机制指定任务实例之间的参数复用关系,最后创建任务控制器,启动多任务训练或推理。
这里举一个实际应用场景的例子。假如有一个目标任务机器阅读理解 MRC,为了提升模型的泛化能力(获得更佳的测试集表现和模型鲁棒性),我们可以设置两个辅助任务掩码语言模型任务 MLM 和问答匹配任务 MATCH。通过 PaddlePALM 我们可以很轻松的完成这个较为复杂的多任务学习过程。
首先,我们为三个任务选取合适的共享参数的主干网络用于文本特征抽取与学习(例如 BERT、ERNIE 等),主干网络可以写入全局配置文件或由用户手动实例化。而后,我们为每个任务选取合适的数据处理工具和任务输出层,进而创建任务控制器,启动三个任务的联合训练。
为了提升易用性,PALM 多任务学习目前已经进行了一个很好的封装,只需要 20 行左右的代码,就可以同时训练多个任务来提升模型效果。基于这个模块,今年百度自研的 D-NET 的模型,实现了 EMNLP2019 阅读理解的十项冠军。
更多内容可参考:https://github.com/PaddlePaddle/PALM
PGL 图神经网络

近几年来,深度神经网络的成功推动了人工智能的发展,然而,在实际场景中,有大量的数据是在非欧式空间的,这限制了深度神经网络的应用。而图神经网络在这类数据上有着出色的处理能力,使得最近一段时间图神经网络在学界与工业界上大放光彩。
百度顺应潮流发布的 PGL 充分利用飞桨独有的 Lod Tensor 特性,实现了高度并行的图神经网络消息传递机制,在性能上超越了 DGL 等现有图学习框架 13 倍。依托于飞桨核心框架以及自研的分布式图引擎,PGL 可支持十亿节点百亿边的巨图训练。此外,PGL 原生支持异构图 Meta Path 采样以及 Message Passing 双模式,预置了 13 种业界主流图学习算法,方便开发者熟悉和使用图神经网络领域模型,包括以下技术特色:
高效:通用消息聚合性能超越业内主流框架 DGL 13 倍
图神经网络模型的独特优势在于充分捕捉数据中的结构信息。PGL 采用消息传递范式(Message Passing)构建图神经网络的接口,用户只需要简单地编写 send 和 recv 函数就能够轻松的实现一个简单的 GCN 网络:其中 send 函数被定义在节点之间的边上,负责将消息从源点发送到目标节点;recv 函数则负责将这些消息聚合起来。目前,PGL 提供两套聚合方式,一套是 Scatter-Gather 用于解决常见如求和聚合的方式,而另外一套则是基于飞桨 Lod Tensor 特性实现的并行通用的消息聚合方法。得益于并行的消息聚合能力,PGL 的速度能够达到 DGL 的 13 倍。
规模:支持十亿节点百亿边的超大规模图训练
依托于分布式图引擎以及大规模参数服务器 Paddle Fleet,PGL 可以轻松在 MPI 集群上搭建分布式超大规模图学习算法。超大规模图会以切分形式在分布式图引擎中存储,此外还提供诸如图信息访问、子图采样、游走等操作算子。在此之上则是 PGL 构建的分布式图训练模块,该模块会与参数服务器 Paddle Fleet 进行联动训练,满足用户数十亿节点 Embedding 学习需求。
易用:轻松搭建异构图学习算法
在工业应用中,许多的图网络是异构。PGL 针对异构图包含多种节点类型和多种边类型的特点进行建模,旨在为用户提供方便易用的异构图框架,让用户可以快速构建自定义的异构图模型。目前,PGL 支持异构图的 Meta Path 采样以及异构图的 Message Passing 机制。异构图存在不同类型的节点和边,为了融入 Message Passing 机制,PGL 可以在异构图中分别对不同类型的边进行消息传递。最后将同一个节点在不同边类型的表示融合在一起。
丰富:预置 13 种业界主流图学习模型
为了便于用户熟悉和使用图神经网络领域的模型,PGL 预置了 13 种主流的图学习模型。这些模型涵盖了同构与异构、图表示学习与图神经网络、分布式训练等样例,可以赋能推荐系统、知识图谱、用户画像、金融风控、智能地图等多个场景。用户可以方便地根据自己的需要选择不同的样例进行复现、修改、上线等。
更多内容,请参考:https://github.com/PaddlePaddle/PGL
PARL 强化学习

PARL(PAddle Reinfocement Learning)是高性能、灵活的强化学习框架,提供可复现性保证,大规模并行支持能力,复用性强且具有良好扩展性。
通过复用通用算法库里面已经实现好的算法,开发者可以很快地在不同算法间切换,保持了高效的迭代频率。PARL 的算法库涵盖了从经典的 DDPG,PPO, TD3 等算法,到并行的 A2C, GA3C, IMPALA 以及并行的 Evolutionary Strategy 等算法。尽管算法库包含了各种类型的复杂算法,但是其接口是相当简单的,基本上是 import 即可用的方式。
同时,基于 PARL 提供的高效灵活的并行化训练能力进行强化学习训练,可以使得训练效率得以数百倍地提升。PARL 的并行接口的设计思想是用 python 的多线程代码实现真正意义上的高并发,参赛选手只需要写多线程级别的代码,然后加上 PARL 的并行修饰符就可以调度不同机器的计算资源,达到高并发的性能。
PARL 应用了百度多年来在强化学习领域的技术深耕和产品应用经验,具有更高的可扩展性、可复现性和可复用性,强大的大规模并行化支持能力。开发者可以通过 PARL 用数行代码定制自己的模型,一个修饰符就能实现并行。此外,PARL 代码风格统一,包含了多个入门级别的强化学习算法,对初学者相当友好。
特别值得一提的,在机器学习领域顶级会议 NeurIPS 2019 主办的 Learn to Move 强化学习比赛中,百度继 2018 年夺得冠军后再度蝉联冠军。本次比赛的难度非常大,在参赛的近 300 支队伍中,仅有 3 支队伍完成了最后挑战。百度基于飞桨的强化学习框架 PARL 不仅成功完成挑战,还大幅领先第二名 143 分。显而易见,百度在强化学习领域占据了明显的优势,冠军含金量颇高。
更多内容请参考,PARL:https://github.com/PaddlePaddle/PARL
PaddleFL 联邦学习
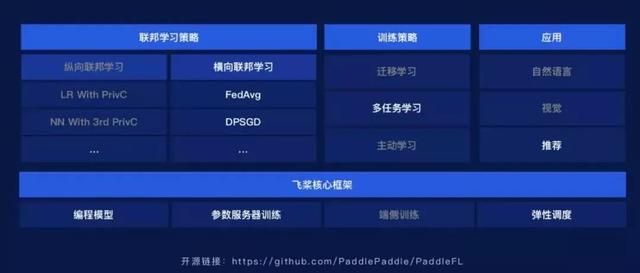
PaddleFL(Paddle Federateddeep Learning)是开源联邦学习框架,可轻松地复制、比较不同联邦学习算法,提供众多联邦学习策略及在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,PaddleFL 还将提供传统机器学习训练策略的应用,例如多任务学习、联邦学习环境下的迁移学习。依靠着飞桨的大规模分布式训练和 Kubernetes 对训练任务的弹性调度能力,PaddleFL 可以基于全栈开源软件轻松地部署。
更多内容可参考:https://github.com/PaddlePaddle/PaddleFL
AutoDL 自动化深度学习
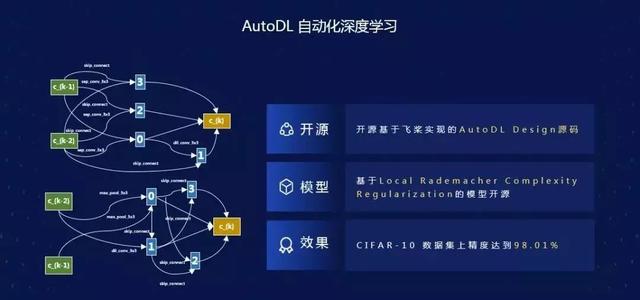
AutoDL 包含自动网络结构设计、迁移小数据建模和适配边缘计算三部分。开源 AutoDL 设计的图像分类网络在 CIFAR10 数据集正确率达到 98%,效果优于目前已公开的 10 类人类专家设计的网络,居于业内领先位置。
更多内容可参考:https://github.com/PaddlePaddle/AutoDL
VisualDL 训练可视化工具
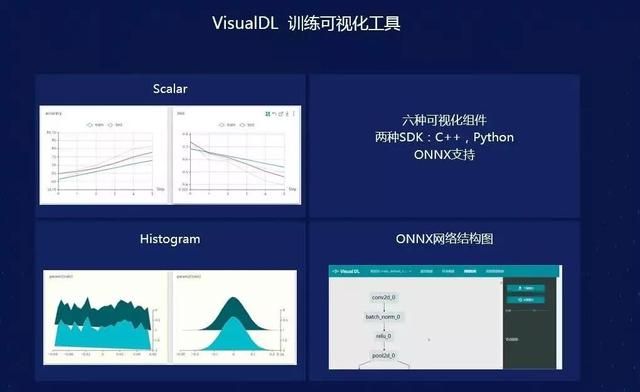
VisualDL 是面向深度学习任务设计的可视化工具,包含 scalar、参数分布、模型结构、图像可视化等功能。该项目正处于高速迭代中,不断增加新组件。目前,大多数 DNN 平台使用 Python 作为配置语言。VisualDL 原生支持 python 使用,在模型 Python 配置中添加几行代码,便可为训练过程提供丰富的可视化支持。
更多内容可参考:https://github.com/PaddlePaddle/VisualDL
想与更多的深度学习开发者交流,请加入飞桨官方 QQ 群:796771754。
如果您想详细了解更多飞桨 PaddlePaddle 的相关内容,请参阅以下文档。
官网地址:
- https://www.paddlepaddle.org.cn/
项目地址:
- PaddleHub:https://github.com/PaddlePaddle/PaddleHub
- PALM:https://github.com/PaddlePaddle/PALM
- PGL:https://github.com/PaddlePaddle/PGL
- PARL: https://github.com/PaddlePaddle/PARL
- PaddleFL:https://github.com/PaddlePaddle/PaddleFL
- AutoDL:https://github.com/PaddlePaddle/AutoDL
- VisualDL: https://github.com/PaddlePaddle/VisualDL
- 飞桨系列文章之核心框架揭秘
- 飞桨系列文章之基础模型库解读
- 飞桨系列文章之端到端开发套件揭秘
- 飞桨系列文章之服务平台解读