清华大学深度强化学习框架“天授”开源
日前,清华大学人工智能研究院基础理论研究中心发布了深度强化学习框架“天授”,代码已在GitHub开源(https://github.com/thu-ml/tianshou)。这也是继“珠算”可微分概率编程库之后,该中心推出的又一个面向复杂决策任务的编程库。
天授的核心开发者接受了新智元专访,团队成员着重强调了天授系统的5大技术优势:代码简洁、模块化、可复现性、接口灵活以及训练速度快。相较于其他PyTorch强化学习框架,天授0.2具有结构简单、二次开发友好的特点,整个框架代码1500行左右,支持主流的强化学习算法DQN、A2C等,同时设计了灵活的接口,用户可以定制自己的训练方法。针对现有平台训练速度慢的缺点,天授通过将并行采样与缓存机制相结合提高了采集数据的速度。同时,整个框架基于模块化的原则进行设计,在其上实现常见的强化学习算法仅需不到100行的代码。天授开源后引起很大关注,在GitHub上很快获得超过900个星标。
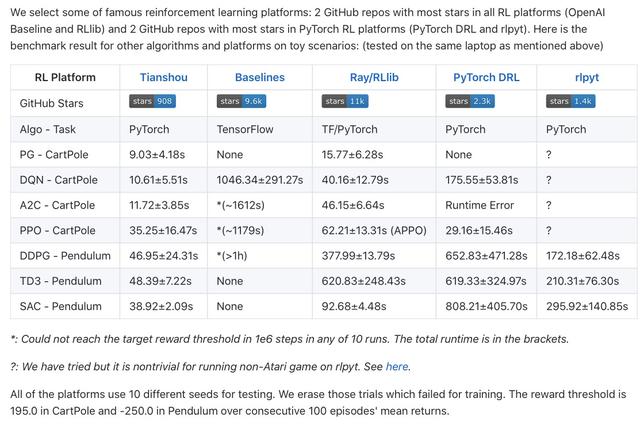
天授和几大主流强化学习框架性能对比
“天授”一词来源于《史记》,意为“取天所授而非学自人类”,刻画了强化学习通过与环境进行交互自主学习,而不需要像监督学习一样需要大量人类标注数据。清华大学团队针对目前多数既有强化学习框架(如RLLib和BaseLine)等无法支持高效、定制化的训练场景的问题,继承了首版TensorFlow“天授0.1”版在模块化等方面的优势,推出了基于PyTorch框架的“天授0.2”版本。
天授团队阎栋博士和翁家翌同学已入驻新智元小程序,欢迎大家点击下方小程序参与互动。
小升初开始写代码,大三进入Bengio实验室
在“天授”0.2的优化设计过程中,清华大学的大四学生翁家翌起到了关键作用。
说起来,翁家翌确实是履历优秀,小升初的暑假就开始写代码。高二作为全国青少年信息学奥林匹克竞赛(NOI)选手进入省队。高中时期就开始钻研微积分、线性代数,大一的基础课程轻车熟路拿高分。
“我高中的时候非常热衷于打竞赛,打竞赛用的是c++,比如说在一个公开的OJ上面刷题,然后我非常热衷于用尽量少的代码写出尽量快的程序,我一直对自己有这种写代码的要求。” 翁家翌谈到自己高中时期的爱好时如是说,正是这种深厚的积累为日后开发天授奠定了基础。
大二上学期翁家翌加入了朱军教授领导的TSAIL实验室,正式开始了RL的漫长征程。大三暑假期间更是去到加拿大图灵奖获得者Bengio教授的实验室,深入开展了RL和NLP的研究。
“我的目标就是要实现一下对方教授给的 idea,这个 idea就是有点类似于如何把人的意识给实现出来。这个有点难,其实大家都在做这个东西,只不过看谁先能做出来,虽然离实现还挺遥远,但是我们在努力。” 翁家翌告诉新智元。

翁家翌
大四科研阶段十分辛苦,经常都要忙到很晚。课余时间,翁家翌和所有人一样,喜欢听音乐,上B站看视频刷知乎。
值得一提的是,翁家翌师从的Yoshua Bengio是深度学习三巨头之一,因其在深度神经网络(deep neural network)领域的开创性贡献刚刚获得了ACM 图灵奖。
受困VizDoom,开启强化学习框架的自研之路
在2018年的 IEEE CIG 计算智能与游戏大会上,朱军教授领导的人工智能创新团队 TSAIL 在第一人称射击类游戏《毁灭战士》(Doom)AI 竞赛 VizDoom(Visual Doom AI Competition)上荣获竞赛 Track 1 的预赛和决赛冠军,及 Track 2 预赛冠军、决赛亚军,成为赛事历史上首个中国区冠军。当时翁家翌作为团队核心成员之一也参与其中。

VizDoom AI竞赛
“从17到18年,我们积累了两年的比赛经验,除了成绩上的进步,我们对强化学习算法在实践中的表现,及其背后的数学机制都有了更深入的了解,我们把这些经验和教训放在了天授0.1和0.2里面。”团队成员阎栋博士告诉新智元。“也正是在比赛过程中,我们产生了做天授的动力,我们发现对于这种高度特化的复杂强学习的训练场景,像baseline、RLlib这样现有的框架很难满足我们的要求。”
在老师和同学的评价中,翁家翌不论是在比赛还是天授开发过程中都起到了非常核心的作用。苏航老师评价说,“他是一个科研能力很出色,动手能力很强的学生。”
“我们清华大学TSAIL团队,希望能够在不确定性、不完全信息的决策方面能够做出贡献,推动以强化学习为代表的智能决策方法的发展。” 苏航老师说。

关于未来的工作,团队负责人朱军教授表示,将在既有工作基础上,从三个维度拓展“天授”框架,从算法层面来讲,将对目前主流强化学习算法进行更加全面的支持,包括model-based RL, imitation learning等;从任务层面来讲,将进一步支持包括Atari、VizDoom等复杂任务;从性能上来讲,将进一步提升框架在模型性能、训练速度、鲁棒性等方面的核心指标,更好地为学术界服务。
天授0.1到天授0.2 ,1500行代码实现所有功能
天授从16年开始迭代,2017年底正式开发0.1版本,项目的初衷是发现当时现存的强化学习框架用起来很不方便:不够模块化,很难在其上做修改和二次开发,所以0.1版本开发的核心宗旨是模块化。
“天授0.1的主要工作是将不同论文中共用的infrastructure,比如memory、optimizer,都给抽象出来,在结构设计和工程实践上做了很多考虑,2017年的时候PyTorch还不成熟,所以团队选择的是Tensorflow。” 阎栋说。
强化学习社区是一个非常丰富的社区,他们所要解决的不同任务和场景之间差异巨大,比图像分类等任务要复杂得多,所以说它的模块化更加困难,天授0.1解决了部分挑战,但并没有完全解决。
天授0.1可以同时支持四个算法,它们的核心组件是相同的比如replay memory,以及optimizer。只需给每个算法设置自己的损失函数,然后去指定自己的网络结构就可以了。
开发过程远非一蹴而就,天授0.1的代码编写的过程可谓是“批阅十稿,增删五次”。在之前的天授版本中,实验室成员阎栋、邹昊晟、任桐正都做出了大量贡献,经过多次的删减打磨出了天授0.1。“第1版的时候我提交了17,000行代码,删去了8000多行。” 阎栋表示。最终优化后的天授0.2,1500行代码就实现了现存几乎所有的强化学习的流行的算法。
天授0.2继承了天授0.1的模块化特性。相比之下,最主要的改变是家翌使用了PyTorch。从去年以来PyTorch底层框架逐渐变得非常成熟,它更灵活,跟Python绑定的更多,具有更多动态支持,便于调试,于是他用PyTorch继承了天授0.1的模块化设计,然后在0.2中用PyTorch重新实现了底层的基本组成模块,对replay memory积累数据、多个环境并行训练,以及trainer从环境中采样策略等多个部分都进行了优化。
在所测试的典型任务中,天授平均来说会比其他框架快一个量级。翁家翌凭借着他丰富的实践经验对天授0.1进行了重新设计和实现,使其在训练速度和性能上实现了大幅提升。
翁家翌强调,“我借鉴了之前一版天授的设计理念,比如说把各种replay buffer全部并成一起,还有比如用collector来统一各个数据,各个策略跟环境交互的过程等等。这些给我开发天授第2版带来了很大的启发,让我少走很多弯路。”
说到AI方向的理想,翁家翌说,“我想在计算机领域多实现一些能够改变我们日常生活方式的一些项目,然后真正能够应用到千家万户。” 目前他已经收到卡内基梅隆大学(CMU)的录取通知书。