AI系列一:机器学习介绍
https://www.toutiao.com/a6649573887778488846/
2019-01-23 14:29:50
在介绍一些机器学习技术前,先拿一个应用场景让大家有个感知。我在2006年初开始涉猎机器学习工作,当初加入的公司叫IronPort,中文名铁口(至今不知道谁翻译的,个人感觉很奇怪,后来公司被Cisco收购),IronPort成立之初集中在一个领域:反垃圾邮件,后来进军到了整个安全领域。IronPort有很多和数据有关的职位,我开始的工作叫TDA,Threat Data Analyst,主要的职责是每天分析全球大量邮件数据,人工打分类组合标签: S(Spam), H(Ham), R(need to be reviewed), T(kinda difficult to categorize),写匹配规则优化机器学习引擎,团队是一个集合了多文化、多语言(每人至少会说3种语言)的全球技术团队。以下是来自Cisco IronPort的垃圾邮件深度防御架构图:
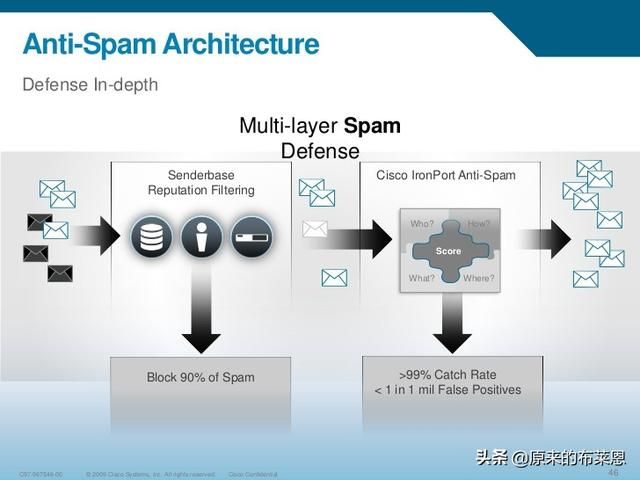
核心几大组件如上图所示:
- Senderbase:全球部署的Senderbase是一个reputation中心,大部分发出的邮件都会首先进入Senderbase进行评估,最后得到一个分数(-10到10)来判断是否进入下一环节,越往负值走意味着更有可能是垃圾邮件Spam,90%的Spam在这一层被捕获。
- Anti-Spam Engine:核心反垃圾邮件引擎,Spam捕获率超过99%,当时没那么高,但也做到了98%,核心的机器学习算法也在这一层实现,主要用了贝叶斯算法,该算法是分类算法的一种,主要实现:
- 为每封邮件打上标签,如:Spam、Ham
- 为每封邮件打分,越高说明越可能是Spam,邮件头、内容体、附件等都是计算依据
什么是机器学习?
机器学习是人工智能的基础,简单来说是用数据产生软件训练模型的技术,拿上面的例子来说,邮件分类是典型的机器学习中的一种,喂大量的训练数据给反垃圾邮件引擎,即贝叶斯算法分类器,通过该分类器来预测新数据的分类。
机器学习又可分为监督学习和无监督学习两大类。
回归(Regression)
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。学过统计学的读者对这个定义一定不陌生,特别是这个表达式:
Y = w1X1 + w2X2 + b
这个只是回归技术的一种,称作线性回归,以下描述几种用的比较多的用于预测的回归技术:
线性回归(Linear Regression)
线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。多元线性回归可表示为:
Y = w1X1 + w2X2 + b
b表示截距,w1,w2表示直线的斜率,也可以称为权重值,训练的过程其实就是确定w值的过程。下图是典型的一元线性回归模型。

图中的空心圆点是真实数据点,红线是一元线性回归模型用来做数据预测,如:Y = wX + b,根据给定的X值通过方程式来计算Y值,通过该图可以直观的得出结论:该一元线性回归模型可以被用来很好的做预测。刚才提到直观,那有没有更好的客观方法用来评估模型的好坏呢?这里介绍几种方法:
- 相对平方误差(Relative Squared Error,RSE)是一个衡量回归模型误差率的常用公式,误差平方方法,可以比较误差是不同单位的模型。

- 相对绝对误差(Relative Absolute Error,RAE)是一个衡量回归模型误差率的常用公式,误差绝对值方法,可以比较误差是不同单位的模型。
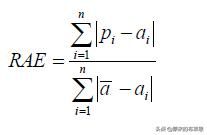
线性回归一个典型的应用场景是健身卡路里燃烧估计:
输入:年龄、性别、身高、体重、健身心跳、健身持久时间
输出:燃烧掉的卡路里
逻辑回归(Logistic Regression)
逻辑回归是用来计算“事件=Success”和“事件=Failure”的概率。当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,就应该使用逻辑回归。这里,Y的值为0或1,可以用以下方程表示:
odds = p / (1-p)
ln(odds) = ln(p / (1-p))
在方程式中使用对数log是有原因的,这个后续详细说明。
多项式回归(Polynomial Regression)
对于一个回归方程,如果自变量的指数大于1,那么它就是多项式回归方程。如下方程所示:
y = a + bχ2
在这种回归技术中,最佳拟合线不是直线。而是一个用于拟合数据点的曲线。
其它
还有很多其它回归技术,如:逐步回归(Stepwise Regression),岭回归(Ridge Regression),套索回归(Lasso Regression),ElasticNet回归等,但很多情况下笔者发现越简单的越好用,主要还是取决于场景。
分类(Classification)
回归模型解决了预测数值的问题,那如何为某事某物分类呢?那就要求助分类(Classification)来帮忙了,最简单的分类是二分类,即预测一个实体属于两类之一,例如预测一封电邮是Spam,还是非Spam的True or False问题。二分类器也可以是一个产生0到1之间数值的函数,通过设定的阈值来判断是True or False。
分类是监督学习,因此测试数据通过已知标签来验证模型。那如何判断分类模型的好坏呢?以下是实践中经常使用到的方法:

该方法称为误差矩阵(Confusion Matrix),名词解释如下:
- FP:预测是Yes,真实情况No
- FN:预测是No,真实情况Yes
- TP:预测是Yes,真实情况也是Yes
- TN:预测是No,真实情况也是No
误差矩阵能够直观的表达数值,以便计算模型表现,模型表现情况可以由上图所示的几个标准衡量,也可以由类似下图所示的ROC曲线表达,具体细节在以后机器学习章节介绍。

聚类(Clustering)
类似分类那样的监督学习是在已知标签下进行的,如Spam是垃圾邮件的标签,通过训练分类器,新来的数据可以被划分为Spam或Not Spam。但很多情况下是无法知道数据标签的,这时无监督学习就很有用了,无监督学习的本质是寻找数据之间的相似性,进而可以划分数据进入不同的类(组),这样的方法称为聚类,“物以类聚,人以群分”。
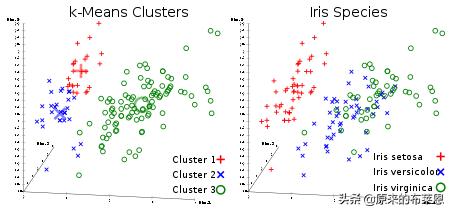
上图显示了经典聚类算法K-Means用在Iris数据集上的效果,Iris也是一个经典数据集合,包含四维特征空间,Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度),很多教科书都用它来作为聚类实践展示,具体细节在后续机器学习章节介绍。
主成分分析(Principal Component Analysis,PCA), 是一种用来评估聚类的统计方法,通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分,具体细节在后续机器学习章节介绍。