利用VGG16网络模块进行迁移学习,实操(附源码)
原文代码+Food_5K数据集,提取码:1izj
什么是迁移学习
当数据集没有大到足以训练整个CNN网络时,通常可以对预训练好的imageNet网络(如VGG16,Inception-v3等)进行调整以适应新任务。
通常来说,迁移学习有两种类型:
- 特征提取
- 微调(fine-tuning)
第一种迁移学习是将预训练的网络视为一个任意特征提取器。图片经过输入层,然后前向传播,最后在指定层停止,通过提取该指定层的输出结果作为输入图片的特征。
第二种迁移学习需要更改预训练模型的结构,具体方法为移除全连接层,添加一组自定义的全连接层来进行新的分类(不唯一)。
本文通过对第二种类型的迁移学习进行项目实操,加深读者理解。
预备知识
1. keras内置的VGG-16网络模块
先简单了解下VGG16网络结构(图1),具体包括5个卷积组和3个全连接层。5个卷积组分别有2,2,3,3,3个卷积层,因此,共有2+2+3+3+3+3=16层。
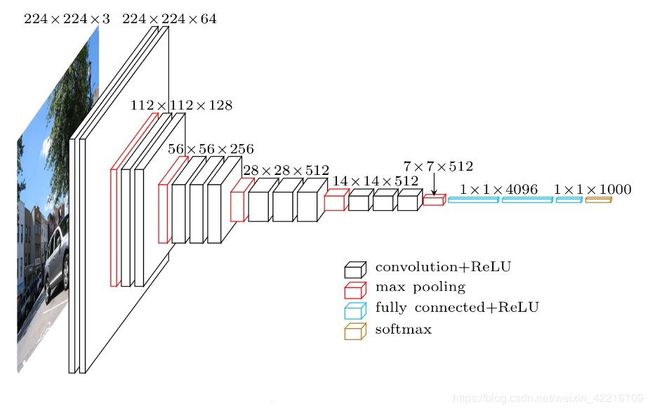 图1 VGG16网络结构
图1 VGG16网络结构
本文将通过移除顶层的3个全连接层,添加自定义全连接层来进行Food-5K数据集的分类训练。
通过如下代码预览去除全连接层后的网络结构。当模型初始化的时候权重会自动下载,这里采用的是在imageNet数据集上预训练好的权重。
from keras.applications import VGG16
model=VGG16(weights='imagenet',include_top=False)
model.summary()输出结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, None, None, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, None, None, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, None, None, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, None, None, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, None, None, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, None, None, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, None, None, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, None, None, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, None, None, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, None, None, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, None, None, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, None, None, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
2. Food-5K数据集
 图2 Food-5K
图2 Food-5K
Food-5K数据集包括training,validation,evaluation三个子包,分别有3000,1000,1000张图片,食物和非食物均占一半(图2)。
项目实践
1. 项目结构
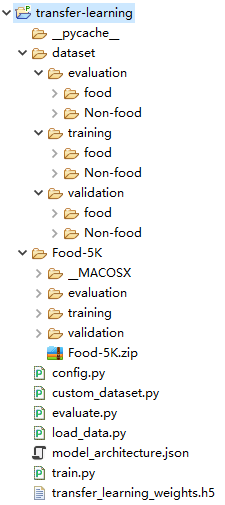 图1 项目结构
图1 项目结构
- dataset是我们自定义的数据集,初始文件夹为空,
- Food-5K为原始数据集,
- config.py完成一些基本的配置,
- custom_dataset.py文件可以获得自定义的dataset数据集,
- load_data.py返回我们所需的数据格式(images,labels)
- train.py完成迁移学习的训练,
- evaluate.py得到模型在测试集上的准确率,
- model.architecture.json为保存的模型结构(不含权重),
- transfer_learning_weights.h5为VGG16微调并重新训练后的模型权重。
2. config 文件
ORIG_DATA_PATH='Food-5K' #原始文件夹
BASE_PATH='dataset' #自定义文件夹
TRAIN='training' #训练集
VALID='validation' #验证集
TEST='evaluation' #测试集
CLASSES=['Non-food','food'] #标签类别3. 自定义数据集
import os
import config
import shutil
for split in (config.TRAIN,config.VALID,config.TEST):
print('[INFO] processing {} split:'.format(split))
imagePaths=os.listdir(os.path.join(config.ORIG_DATA_PATH,split))
for ele in imagePaths:
if not ele.endswith('.jpg'):
imagePaths.remove(ele)
for imagePath in imagePaths:
label=config.CLASSES[int(imagePath.split('_')[0])]
dst=os.path.join(config.BASE_PATH,split,label)
if not os.path.exists(dst):
os.makedirs(dst)
#复制图片
shutil.copy2(os.path.join(config.ORIG_DATA_PATH,config.TRAIN,imagePath), os.path.join(dst,imagePath))
print('[INFO] All is done' )分别完成Food-5K文件夹中三个子包的食物和非食物分类。
4. 获得训练、验证、测试所用的数据结构
from config import BASE_PATH
from imutils import paths
import numpy as np
import random
import cv2
import os
#定义图像载入函数
def load_images(x):
image=cv2.imread(x)
image=cv2.resize(image,(224,224))
return image
#获得模型用数据结构
def load_data_split(datapath):
imagePaths=list(paths.list_images(os.path.join(BASE_PATH,datapath)))
random.shuffle(imagePaths)
labels=[int(i.split('\\')[-1][0]) for i in imagePaths]
images=np.array([load_images(i) for i in imagePaths])
return (images,labels)5. VGG16网络的微调及训练
from keras.layers import Flatten,Dense,Dropout,Input
from keras.applications import VGG16
from load_data import load_data_split
from keras.optimizers import SGD
from keras.models import Model
from keras.utils import np_utils
import config
print('[INFO] loading dataset......')
(x_train,y_train)=load_data_split(config.TRAIN)
(x_valid,y_valid)=load_data_split(config.VALID)
y_train=np_utils.to_categorical(y_train,2)
y_valid=np_utils.to_categorical(y_valid,2)
print('[INFO] initializing model......')
base_model=VGG16(weights='imagenet',include_top=False,input_tensor=Input(shape=(224,224,3)))
#微调
head_model=base_model.output
head_model=Flatten(name="flatten")(head_model)
head_model = Dense(512, activation="relu")(head_model)
head_model = Dropout(0.5)(head_model)
head_model=Dense(64,activation='relu')(head_model)
head_model = Dense(len(config.CLASSES), activation="softmax")(head_model)
model=Model(base_model.input,head_model)
#冻结前面的5个卷积组,只训练自定义的全连接层
for layer in base_model.layers:
layer.trainable=False
print('[INFO] compiling model')
sgd=SGD(lr=0.0001,momentum=0.9)
model.compile(loss='categorical_crossentropy',metrics=['accuracy'],optimizer=sgd)
print('[INFO] training model')
model.fit(x_train, y_train, batch_size=32, epochs=2, validation_data=(x_valid,y_valid))
print('[INFO] saving model and weights')
#保存模型(不含权重)
model_json=model.to_json()
open('model_architecture.json','w').write(model_json)
#保存权重
model.save_weights('transfer_learning_weights.h5', overwrite=True)冻结去除了顶层的VGG16网络的权重参数,只训练自定义的全连接层。最后将新的模型和权重分别保存。
经过两轮的训练,训练集上准确率就已经达到了96.13%,验证集上99.2%。结果如下:
- loss: 0.4639 - acc: 0.9613 - val_loss: 0.1036 - val_acc: 0.9920
6.测试集上的准确率
from keras.models import model_from_json
from keras.utils import np_utils
from load_data import load_data_split
from keras.optimizers import SGD
import config
#载入模型和权重
loaded_model_json = open('model_architecture.json', 'r').read()
model=model_from_json(loaded_model_json)
model.load_weights('transfer_learning_weights.h5')
print('[INFO] loading dataset...')
(x_test,y_test)=load_data_split(config.TEST)
y_test=np_utils.to_categorical(y_test,2)
sgd=SGD(lr=0.0001,momentum=0.9)
model.compile(loss='categorical_crossentropy',metrics=['accuracy'],optimizer=sgd)
print('[INFO] evaluating...')
score=model.evaluate(x_test,y_test,batch_size=32)
print('test score: {}'.format(score[0]))
print('test accuracy:{}'.format(score[1]))输出结果如下:
test score: 0.08451384264268018
test accuracy:0.992
可以发现通过迁移学习,经过两轮的训练后在测试集上同样达到99.2%的准确率。