(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)
和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务.
它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。
决策树也是随机森林的基本组成部分(见第7章),而随机森林是当今最强大的机器学习算法之一。
在本章中,我们将首先讨论如何使用决策树进行训练,可视化和预测。
然后我们会学习在 Scikit-learn 上面使用 CART 算法,并且探讨如何调整决策树让它可以用于执行回归任务。
最后,我们当然也需要讨论一下决策树目前存在的一些局限性。
决策树的训练和可视化
为了理解决策树,我们需要先构建一个决策树并亲身体验它到底如何进行预测。
接下来的代码就是在我们熟知的鸢尾花数据集上进行一个决策树分类器的训练。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
你可以通过使用export_graphviz()方法,通过生成一个叫做iris_tree.dot的图形定义文件将一个训练好的决策树模型可视化。
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=image_path("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
然后,我们可以利用graphviz package [1] 中的dot命令行,将.dot文件转换成 PDF 或 PNG 等多种数据格式。例如,使用命令行将.dot文件转换成.png文件的命令如下:
[1] Graphviz是一款开源图形可视化软件包,http://www.graphviz.org/。
$ dot -Tpng iris_tree.dot -o iris_tree.png
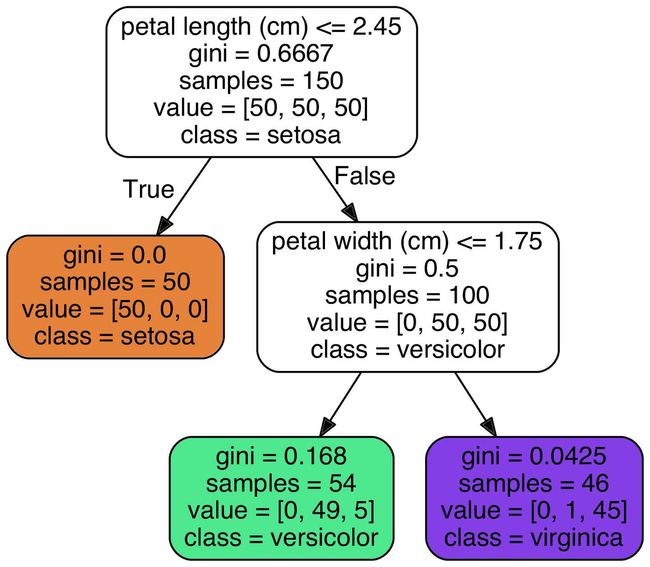
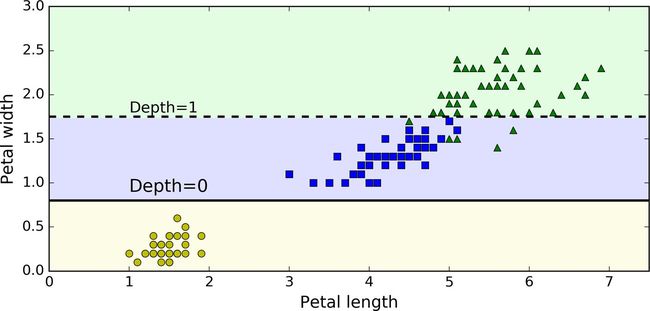
我们的第一个决策树如图 6-1。
开始预测
现在让我们来看看在图 6-1 中的树是如何进行预测的。假设你找到了一朵鸢尾花并且想对它进行分类,你从根节点开始(深度为 0,顶部):该节点询问花朵的花瓣长度是否小于 2.45 厘米。如果是,您将向下移动到根的左侧子节点(深度为 1,左侧)。 在这种情况下,它是一片叶子节点(即它没有任何子节点),所以它不会问任何问题:你可以方便地查看该节点的预测类别,决策树预测你的花是 Iris-Setosa(class = setosa)。
现在假设你找到了另一朵花,但这次的花瓣长度是大于 2.45 厘米的。你必须向下移动到根的右侧子节点(深度为 1,右侧),而这个节点不是叶节点,所以它会问另一个问题:花瓣宽度是否小于 1.75 厘米? 如果是,那么你的花很可能是一个 Iris-Versicolor(深度为 2,左)。 如果不是,那很可能一个 Iris-Virginica(深度为 2,右),真的是太简单了,对吧!
决策树的众多特性之一就是, 它不需要太多的数据预处理, 尤其是不需要进行特征的缩放或者归一化。
节点的samples属性统计出它应用于多少个训练样本实例。
例如,我们有一百个训练实例是花瓣长度大于 2.45 里面的(深度为 1, 右侧),在这 100 个样例中又有 54 个花瓣宽度小于 1.75cm(深度为 2,左侧)。
节点的value属性告诉你这个节点对于每一个类别的样例有多少个。
例如:右下角的节点中包含 0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica。
最后,节点的Gini属性用于测量它的纯度:如果一个节点包含的所有训练样例全都是同一类别的,我们就说这个节点是纯的(Gini=0)。
例如,深度为 1 的左侧节点只包含 Iris-Setosa 训练实例,它就是一个纯节点,Gini 指数为 0。
公式 6-1 显示了训练算法如何计算第i个节点的 gini 分数 。例如, 深度为 2 的左侧节点基尼指数为:。另外一个纯度指数也将在后文很快提到。
公式6-1. Gini分数
- 是第
i个节点中训练实例为的k类实例的比例
Scikit-Learn 用的是 CART 算法, CART 算法仅产生二叉树:每一个非叶节点总是只有两个子节点(只有是或否两个结果)。然而,像 ID3 这样的算法可以产生超过两个子节点的决策树模型。
图 6-2 显示了决策树的决策边界。粗的垂直线代表根节点(深度为 0)的决策边界:花瓣长度为 2.45 厘米。由于左侧区域是纯的(只有 Iris-Setosa),所以不能再进一步分裂。然而,右边的区域是不纯的,所以深度为 1 的右边节点在花瓣宽度为 1.75 厘米处分裂(用虚线表示)。又由于max_depth设置为 2,决策树在那里停了下来。但是,如果将max_depth设置为 3,两个深度为 2 的节点,每个都将会添加另一个决策边界(用虚线表示)。

模型小知识:白盒与黑盒
正如我们看到的一样,决策树非常直观,它的决策很容易解释。这种模型通常被称为白盒模型。相反,随机森林或神经网络通常被认为是黑盒模型。他们能做出很好的预测,并且您可以轻松检查它们做出这些预测过程中计算的执行过程。然而,人们通常很难用简单的术语来解释为什么模型会做出这样的预测。例如,如果一个神经网络说一个特定的人出现在图片上,我们很难知道究竟是什么导致了这一个预测的出现:
模型是否认出了那个人的眼睛? 她的嘴? 她的鼻子?她的鞋?或者是否坐在沙发上? 相反,决策树提供良好的、简单的分类规则,甚至可以根据需要手动操作(例如鸢尾花分类)。
估计分类概率
决策树还可以估计某个实例属于特定类k的概率:首先遍历树来查找此实例的叶节点,然后它返回此节点中类k的训练实例的比例。
例如,假设你发现了一个花瓣长 5 厘米,宽 1.5 厘米的花朵。相应的叶节点是深度为 2 的左节点,因此决策树应该输出以下概率:Iris-Setosa 为 0%(0/54),Iris-Versicolor 为 90.7%(49/54),Iris-Virginica 为 9.3%(5/54)。当然,如果你要求它预测具体的类,它应该输出 Iris-Versicolor(类别 1),因为它具有最高的概率。我们了测试一下:
>>> tree_clf.predict_proba([[5, 1.5]])
array([[ 0. , 0.90740741, 0.09259259]])
>>> tree_clf.predict([[5, 1.5]])
array([1])
完美!请注意,估计概率在任何地方都是相同的, 除了图 6-2 中右下角的矩形部分,例如花瓣长 6 厘米和宽 1.5 厘米(尽管在这种情况下它看起来很可能是 Iris-Virginica)。
CART 训练算法
Scikit-Learn 用分类回归树(Classification And Regression Tree,简称 CART)算法训练决策树(也叫“增长树”)。这种算法思想真的非常简单:
首先使用单个特征k和阈值 (例如,“花瓣长度≤2.45cm”)将训练集分成两个子集。它如何选择k和 呢?它寻找一对 ,能够产生最纯粹的子集(通过子集大小加权计算)。算法尝试最小化的损失函数,如公式 6-2所示。

当它成功的将训练集分成两部分之后, 它将会继续使用相同的递归式逻辑继续的分割子集,然后是子集的子集。当达到预定的最大深度之后将会停止分裂(由max_depth超参数决定),或者是它找不到可以继续降低不纯度的分裂方法的时候。几个其他超参数(之后介绍)控制了其他的停止生长条件(min_samples_split,min_samples_leaf,min_weight_fraction_leaf,max_leaf_nodes)。
警告
正如所见,CART 算法是一种贪婪算法:它贪婪地搜索最高级别的最佳分割方式,然后在每个深度重复该过程。 它不检查分割是否能够在几个级别中的全部分割可能中找到最佳方法。贪婪算法通常会产生一个相当好的解决方法,但它不保证这是全局中的最佳解决方案。
不幸的是,找到最优树是一个 NP 完全问题:它需要 时间,即使对于相当小的训练集也会使问题变得棘手。 这就是为什么我们必须设置一个“合理的”(而不是最佳的)解决方案。
计算复杂度
在建立好决策树模型后, 做出预测需要遍历决策树, 从根节点一直到叶节点。决策树通常近似左右平衡,因此遍历决策树需要经历大致 个节点。由于每个节点只需要检查一个特征的值,因此总体预测复杂度仅为 ,与特征的数量无关。 所以即使在处理大型训练集时,预测速度也非常快。
然而,训练算法的时候(训练和预测不同)需要比较所有特征(如果设置了max_features会更少一些)。这就使得训练复杂度为 。对于小训练集(少于几千例),Scikit-Learn 可以通过预先设置数据(presort = True)来加速训练,但是这对于较大训练集来说会显着减慢训练速度。
Gini不纯度或信息熵
通常,算法使用 Gini 不纯度来进行检测, 但是你也可以通过将标准超参数设置为"entropy"来使用熵不纯度进行检测。这里熵的概念是源于热力学中分子混乱程度的概念,当分子井然有序的时候,熵值接近于 0。
熵这个概念后来逐渐被扩展到了各个领域,其中包括香农的信息理论,这个理论被用于测算一段信息中的平均信息密度(熵的减少通常称为信息增益)。当所有信息相同的时候熵被定义为零。
在机器学习中,熵经常被用作不纯度的衡量方式,当一个集合内只包含一类实例时, 我们称为数据集的熵为 0。
公式 6-3 显示了第i个节点的熵的定义,例如,在图 6-1 中, 深度为 2 左节点的熵为 。

那么我们到底应该使用 Gini 指数还是熵呢? 事实上大部分情况都没有多大的差别:它们会生成类似的决策树。
基尼指数计算稍微快一点,所以这是一个很好的默认值。但是,也有的时候它们会产生不同的树,基尼指数会趋于在树的分支中将最多的类隔离出来,而熵指数趋向于产生略微平衡一些的决策树模型。
正则化超参数
决策树几乎不对训练数据做任何假设(与此相反的是线性回归等模型,这类模型通常会假设数据是符合线性关系的)。
如果不添加约束,树结构模型通常将根据训练数据调整自己,使自身能够很好的拟合数据,而这种情况下大多数会导致模型过拟合。
这一类的模型通常会被称为非参数模型,这不是因为它没有任何参数(通常也有很多),而是因为在训练之前没有确定参数的具体数量,所以模型结构可以根据数据的特性自由生长。
与此相反的是,像线性回归这样的参数模型有事先设定好的参数数量,所以自由度是受限的,这就减少了过拟合的风险(但是增加了欠拟合的风险)。
DecisionTreeClassifier类还有一些其他的参数用于限制树模型的形状: min_samples_split(节点在被分裂之前必须具有的最小样本数),min_samples_leaf(叶节点必须具有的最小样本数),min_weight_fraction_leaf(和min_samples_leaf相同,但表示为加权总数的一小部分实例),max_leaf_nodes(叶节点的最大数量)和max_features(在每个节点被评估是否分裂的时候,具有的最大特征数量)。增加min_* hyperparameters或者减少max_* hyperparameters会使模型正则化。
笔记
一些其他算法的工作原理是在没有任何约束条件下训练决策树模型,让模型自由生长,然后再对不需要的节点进行剪枝。
当一个节点的全部子节点都是叶节点时,如果它对纯度的提升不具有统计学意义,我们就认为这个分支是不必要的。
标准的假设检验,例如卡方检测,通常会被用于评估一个概率值 -- 即改进是否纯粹是偶然性的结果(也叫原假设)
如果 p 值比给定的阈值更高(通常设定为 5%,也就是 95% 置信度,通过超参数设置),那么节点就被认为是非必要的,它的子节点会被删除。
这种剪枝方式将会一直进行,直到所有的非必要节点都被删光。
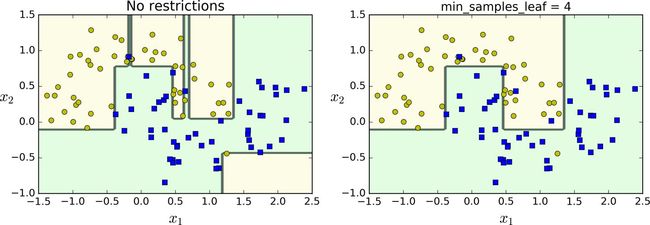
图 6-3 显示了对moons数据集(在第 5 章介绍过)进行训练生成的两个决策树模型,左侧的图形对应的决策树使用默认超参数生成(没有限制生长条件),右边的决策树模型设置为min_samples_leaf=4。很明显,左边的模型过拟合了,而右边的模型泛用性更好。
回归
决策树也能够执行回归任务,让我们使用 Scikit-Learn 的DecisionTreeRegressor类构建一个回归树,让我们用max_depth = 2在具有噪声的二次项数据集上进行训练。
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
结果如图 6-4 所示
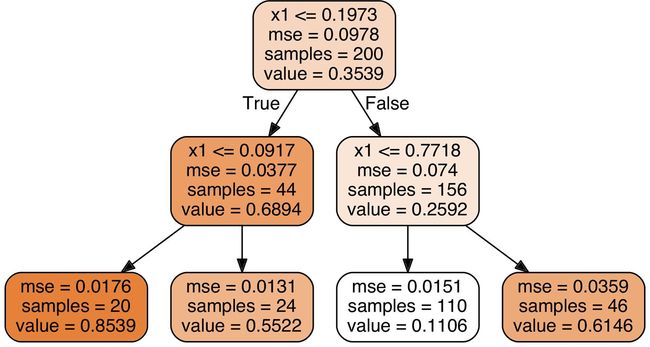
这棵树看起来非常类似于你之前建立的分类树,它的主要区别在于,它不是预测每个节点中的样本所属的分类,而是预测一个具体的数值。例如,假设你想对 的新实例进行预测。从根开始遍历树,最终到达预测值等于 0.1106 的叶节点。该预测仅仅是与该叶节点相关的 110 个训练实例的平均目标值。而这个预测结果在对应的 110 个实例上的均方误差(MSE)等于 0.0151。
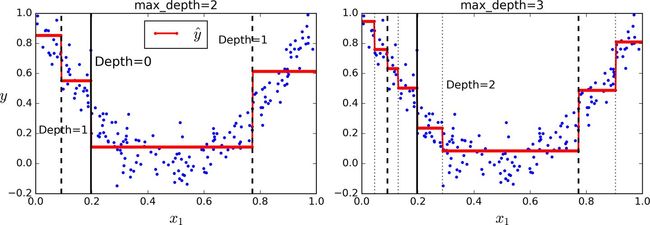
在图 6-5 的左侧显示的是模型的预测结果,如果你将max_depth=3设置为 3,模型就会如 6-5 图右侧显示的那样.注意每个区域的预测值总是该区域中实例的平均目标值。算法以一种使大多数训练实例尽可能接近该预测值的方式分割每个区域。
译者注:图里面的红线就是训练实例的平均目标值,对应上图中的
value
CART 算法的工作方式与之前处理分类模型基本一样,不同之处在于,现在不再以最小化不纯度的方式分割训练集,而是试图以最小化 MSE 的方式分割训练集。
公式 6-4 显示了该算法试图最小化的损失函数。

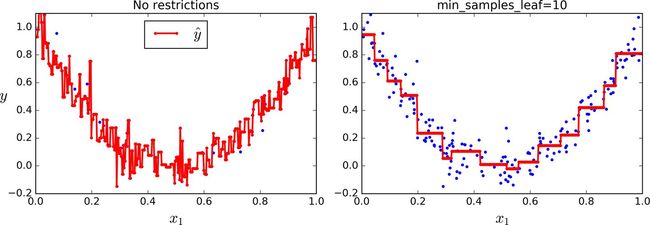
和处理分类任务时一样,决策树在处理回归问题的时候也容易过拟合。如果不添加任何正则化(默认的超参数),你就会得到图 6-6 左侧的预测结果,显然,过度拟合的程度非常严重。而当我们设置了min_samples_leaf = 10,相对就会产生一个更加合适的模型了,就如图 6-6 所示的那样。
不稳定性
我希望你现在了解了决策树到底有哪些特点:
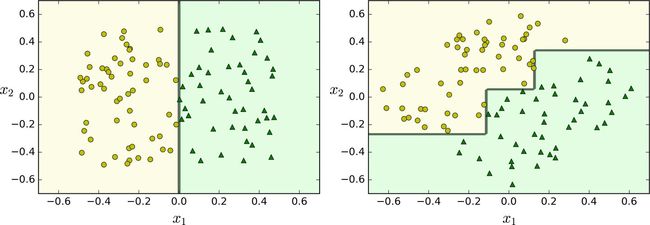
它很容易理解和解释,易于使用且功能丰富而强大。然而,它也有一些限制,首先,你可能已经注意到了,决策树很喜欢设定正交化的决策边界,(所有边界都是和某一个轴相垂直的),这使得它对训练数据集的旋转很敏感,例如图 6-7 显示了一个简单的线性可分数据集。在左图中,决策树可以轻易的将数据分隔开,但是在右图中,当我们把数据旋转了 45° 之后,决策树的边界看起来变的格外复杂。尽管两个决策树都完美的拟合了训练数据,右边模型的泛化能力很可能非常差。
解决这个难题的一种方式是使用 PCA 主成分分析(第八章),这样通常能使训练结果变得更好一些。
更加通俗的讲,决策时的主要问题是它对训练数据的微小变化非常敏感,举例来说,我们仅仅从鸢尾花训练数据中将最宽的 Iris-Versicolor 拿掉(花瓣长 4.8 厘米,宽 1.8 厘米),然后重新训练决策树模型,你可能就会得到图 6-8 中的模型。正如我们看到的那样,决策树有了非常大的变化(原来的如图 6-2),事实上,由于 Scikit-Learn 的训练算法是非常随机的,即使是相同的训练数据你也可能得到差别很大的模型(除非你设置了随机数种子)。
我们下一章中将会看到,随机森林可以通过多棵树的平均预测值限制这种不稳定性。
练习
在 有100 万个实例的训练集上训练(没有限制)的决策树的深度大概是多少?
节点的基尼指数比起它的父节点是更高还是更低?它是通常情况下更高/更低,还是永远更高/更低?
如果决策树过拟合了,减少最大深度是一个好的方法吗?
如果决策树对训练集欠拟合了,尝试缩放输入特征是否是一个好主意?
如果对包含 100 万个实例的数据集训练决策树模型需要一个小时,在包含 1000 万个实例的培训集上训练另一个决策树大概需要多少时间呢?
如果你的训练集包含 100,000 个实例,设置
presort=True会加快训练的速度吗?-
对
moons数据集进行决策树训练并优化模型。通过语句
make_moons(n_samples=10000, noise=0.4)生成moons数据集通过
train_test_split()将数据集分割为训练集和测试集。-
进行交叉验证,并使用网格搜索法寻找最好的超参数值(使用
GridSearchCV类的帮助文档)提示: 尝试各种各样的
max_leaf_nodes值 使用这些超参数训练全部的训练集数据,并在测试集上测量模型的表现。你应该获得大约 85% 到 87% 的准确度。
-
生成森林
接着前边的练习,现在,让我们生成 1,000 个训练集的子集,每个子集包含 100 个随机选择的实例。提示:你可以使用 Scikit-Learn 的
ShuffleSplit类。使用上面找到的最佳超参数值,在每个子集上训练一个决策树。在测试集上测试这 1000 个决策树。由于它们是在较小的集合上进行了训练,因此这些决策树可能会比第一个决策树效果更差,只能达到约 80% 的准确度。
见证奇迹的时刻到了!对于每个测试集实例,生成 1,000 个决策树的预测结果,然后只保留出现次数最多的预测结果(您可以使用 SciPy 的
mode()函数)。这个函数使你可以对测试集进行多数投票预测。在测试集上评估这些预测结果,你应该获得了一个比第一个模型高一点的准确率,(大约 0.5% 到 1.5%),恭喜,你已经弄出了一个随机森林分类器模型!
(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)