在本教程中,我将讨论如何使用Python抓取无限滚动页面。
您将了解如何在Web开发工具中分析HTTP请求,并使用过滤器来帮助您快速找到获取真实数据的目标请求。
本教程还包含两个基于
Scrapy和的工作代码文件Beautifulsoup。您可以比较它们以更好地理解Python世界中顶级的两个Web抓取框架。
让我们开始吧。
背景上下文
如今,越来越多的网站开始用它infinite scrolling来取代经典的分页。当用户滚动到网页底部时,javascript会自动发送HTTP请求并加载新项目。你可以infinite scrolling在大多数电子商务网站和博客中看到。
人们抓取数据的最大问题infinite scrolling pages是找出用于获取新项目数据的URL
我将以Scraping Infinite Scrolling Pages Exercise为例向您展示如何分析页面并构建蜘蛛来获取数据。
分析网页
我会Google Chrome在这里用作一个例子。
首先,我们访问Scraping无限滚动页面练习,然后打开我们浏览器的Web开发工具,以帮助我们检查网站的网络流量。如果你是新手web dev tools,只是Right-click on any page element and select Inspect Element.。
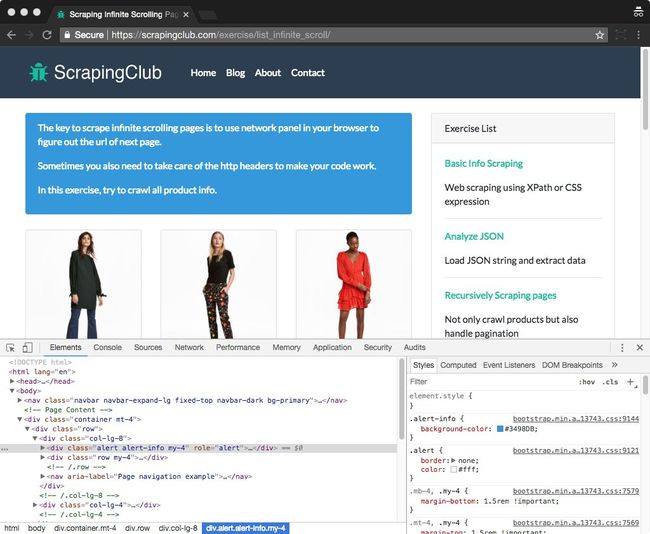
正如你所看到的,一个面板显示出来让你检查网页。您可以使用Web开发工具来帮助您检查DOM元素,调试js等。
现在我们需要找到javascript用来获取以下内容的URL,因此我们单击Network开发工具的选项卡来检查访问网页时的所有HTTP请求。
以下是您应该了解的有关网络标签的两个基本要点。
- 您可以输入一些关键字来过滤请求
- 您可以根据请求类型过滤请求,例如
image,XHR
在大多数情况下,我们关心的请求可以在XHR(XMLHttpRequest)中找到,这意味着这里有一个Ajax请求。
因此,在您设置过滤器后XHR,请尝试滚动到底部,然后您会看到发送了一个新请求,同时将新产品加载到网页中。
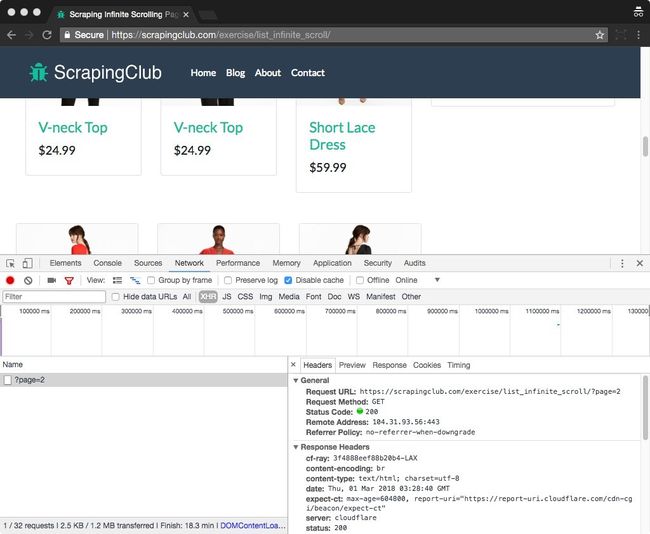
您可以检查目标请求的URL,请求标头和Cookie值
在这里,我们可以看到下一页的网址https://scrapingclub.com/exercise/list_infinite_scroll/?page=2,下面列出了HTTP标题
Referer:https:// scrapingclub 。COM / 运动/ list_infinite_scroll /
用户- 代理:Mozilla的/ 5.0 (Macintosh上,英特尔的Mac OS X 10 _10_4 )为AppleWebKit / 537.36 (KHTML ,像壁虎)镀铬/ 64.0.3282.186 的Safari / 537.36 X - 要求- 搭配:XMLHttpRequest的
让我在这里做一个简短的分析,HTTP头中有三个值,User-Agent意味着您用来访问该页面的浏览器。我们只能专注于X-Requested-With和Referer这里。
在我们清楚了解请求的细节后,下一步就是在代码中实现它。
工作流程图
大多数网页抓取教程都会讲述更多关于代码的内容,并且不太会谈论如何分析网页,但是,我相信教人们如何分析网站比直接给他们代码行更重要。
以下是帮助您解决类似问题的工作流程图。随时下载并在必要时检查它。
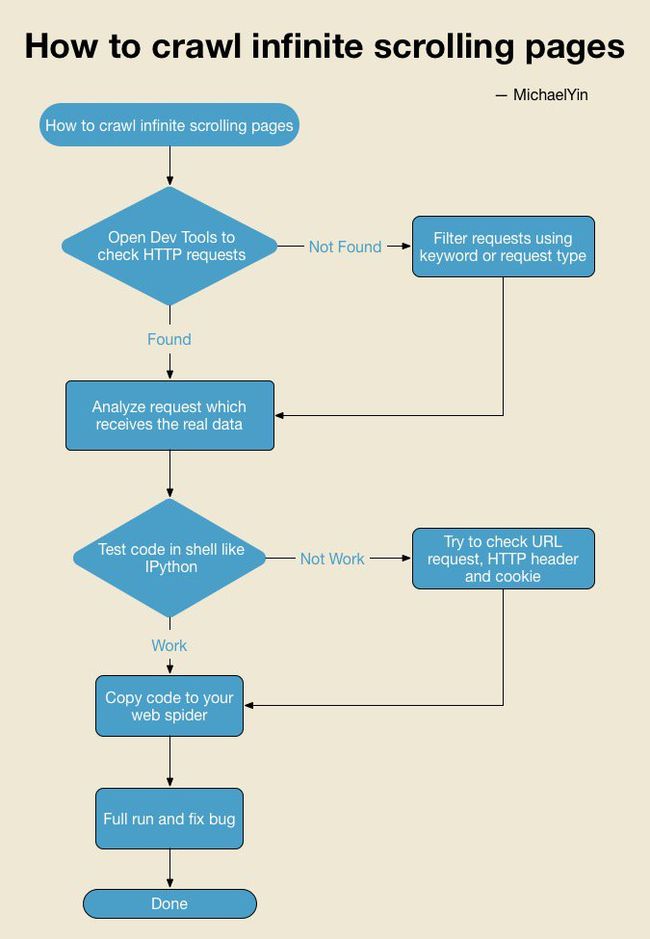
如果你看到上面的图表,你可能有点困惑Test code in shell,让我解释一下。
有些人喜欢在完成后调试并测试蜘蛛,而这种修复方法很费时费力。在Python shell中测试代码可以确保代码按预期工作并节省大量时间。
Scrapy解决方案
接下来,我将尝试向您展示如何使用爬行无限滚动页面Scrapy,这是人们在Python中开发蜘蛛的第一选项。
首先,我们使用下面的命令来创建一个scrapy项目,如果您scrapy在您的机器上安装时遇到困难,您可以查看mac,linux和win的详细安装指南
$ scrapy startproject scrapy_spider
$ cd scrapy_spider
现在我们输入scrapy shell并测试我们的代码。
$ scrapy shell https://scrapingclub.com/exercise/list_infinite_scroll/
如果你还没有安装IPython shell,那么scrapy将使用默认的python shell,但我建议你安装它IPython来为你的python shell带来更强大的功能。
>>> from scrapy.http.request import请求
>>> url ='https://scrapingclub.com/exercise/list_infinite_scroll/?page=2'
>>> req =请求(url = url)
>>> fetch(req)
已抓取(200)(引用者:无)
我内置的要求,只有下一个URL,和它的作品!该网站没有检查useragent,X-Requested-With我感觉很幸运!如果你仍然在这一步失败,你需要添加头文件,如上所述,以确保我们的蜘蛛发送的请求与发送的浏览器完全相同,这是关键!
首先在Python shell中测试代码是最有效的方法,你应该学会如何去做
恭喜!您已经掌握了在Python shell中分析网页和测试代码的技巧。下面我添加了整个Scrapy蜘蛛代码,以便您可以了解您是否感兴趣。你可以把文件放在scrapy_spider/spiders/infinite_scroll.py,然后运行命令scrapy crawl infinite_scroll来运行Scrapy蜘蛛。
# - * - 编码:utf-8 - * -
from __future__ import print_function
import json
import re
import logging
进口 scrapy
从 scrapy.http.request 进口 请求
从 spider_project.items 进口 SpiderProjectItem
来自 six.moves.urllib 导入 分析
类 List_infinite_scroll_Spider (scrapy 。蜘蛛):
名称 = “infinite_scroll”
DEF start_requests (自):
产率 请求(
URL = “https://scrapingclub.com/exercise/list_infinite_scroll/” ,
回调= 自我。parse_list_page
)
def parse_list_page (self , response ):
“”“
下一页的网址就像
https://scrapingclub.com/exercise/list_infinite_scroll/?page=2
它可以在a.next页中找到
“”“
#First,检查是否下一个页面可用,如果发现,产率请求
next_link = 响应。的xpath (
” //一个[@类=‘页面链接下一页’] / @ href“ )。extract_first ()
if next_link :
#如果网站有严格的策略,你应该在这里做更多的工作
#比如修改HTTP头
#连结网址
url = 回应。url
next_link = url [:url 。找到('?' ) + next_link
产量 请求(
URL = next_link ,
回调= 自我。parse_list_page
)
#找产品链接和产量要求背
的 REQ 的 自我。extract_product (response ):
yield req
def extract_product (self , response ):
links = response 。xpath (“// div [@ class ='col-lg-8'] // div [@ class ='card'] / a / @ href” )。提取()
为 URL 在 链接:
结果 = 解析。里urlparse (响应。URL )
BASE_URL = 解析。urlunparse (
(结果。方案, 结果。netloc , “” , “” , “” , “” )
)
url = parse 。urljoin (BASE_URL , URL )
产率 请求(
URL = URL ,
回调= 自我。parse_product_page
)
def parse_product_page (self , response ):
“”“
产品页面使用ajax获取数据,尝试分析并
自行完成 。
”“”
日志记录。信息(“处理” + 响应。URL )
得到 无
BeautifulSoup解决方案
由于BeautifulSoup在Python世界非常流行,所以在这里我还添加了使用BeautifulSoup的代码,供您进行比较和学习。最有趣的部分是,如果你的模式是这样的,你可以发现你可以轻松地将你的代码迁移到Scrapy。您可以将此文件保存为infinite_scroll.py和python infinite_scroll.py
#!/ usr / bin / env python
# - * - coding:utf-8 - * -
#vim:fenc = utf-8
“””
BeautifulSoup默认不支持XPath表达式,因此我们
在这里
使用CSS 表达式,但是您可以使用https://github.com/scrapy/parsel来编写XPath以便根据需要提取数据
“””
从 __future__ 进口 print_function
从 BS4 进口 BeautifulSoup
进口 要求
从 six.moves.urllib 进口 解析
START_PAGE = “https://scrapingclub.com/exercise/list_infinite_scroll/”
QUEUE = []
def parse_list_page (url ):
r = 请求。得到(URL )
汤 = BeautifulSoup ([R ,文本, “LXML” )
链接 = 汤。如果链接:next_link = links [ 0 ],则选择('a [class =“page-link next-page”]' )
。attrs [ 'href' ] next_link = url [:url 。find ('?' )] + next_link QUEUE 。追加((parse_list_page ,next_link ))
链接 = 汤。选择('div.col-LG-8 div.card A' )
用于 链接 在 链接:
product_url = 链接。attrs [ 'href' ]
result = parse 。urlparse (url )
base_url = 解析。urlunparse (
(结果。方案, 结果。netloc , “” ,“” , “” , “” )
)
product_url = 解析。urljoin (base_url , product_url )
QUEUE 。append (
(parse_detail_page , product_url )
)
def parse_detail_page (url ):
#r = requests.get(url)
#soup = BeautifulSoup(r.text,“lxml”)
print (“processing” + url )
def main ():
“”“
推回调方法和URL排队
”“”
QUEUE 。追加(
(parse_list_page , START_PAGE )
)
而 len (QUEUE ):
call_back , url = QUEUE 。pop (0 )
call_back (url )
如果 __name__ == ' __main__ ' :
main ()
下一步是什么,你学到了什么?
在本文中,我们使用Python构建一个蜘蛛来抓取无限滚动页面。我们学会了如何web dev tools帮助我们分析网络流量,以及如何测试代码,Scrapy shell这是我们开发蜘蛛的有效方式。
加群:731233835 可获取10本 Python电子书