Ceph分布式存储混合硬件架构方案
笔者在为容器云做存储支持时开始接触、使用、研究ceph分布式存储系统。Ceph能够同时提供对象存储、文件存储以及块存储,为基于云的海量数据存储提供了较优的解决方案。
具体了解ceph相关内容请参考ceph官网[1]及论文[2]。本文主要讲基于ssd和hdd混合硬件的三种架构方案以及大致步骤,力求在硬件价格成本与存储服务性能之间找到一个最佳平衡点。目前ceph的osd主要可以基于SSD或者HDD的裸盘进行构建,如果全部基于SSD进行构建,毫无疑问其性能一定会最优,但是SSD价格昂贵,出于成本考虑,不可能全部采用SSD进行构建,那么SSD与HDD混合硬件架构就显得很有必要。下面我们根据ceph的功能特点来讲三种架构方案,以及实现的大致步骤。
方案1:主本在SSD其余副本在HDD:

ceph写时先写primary,成功后primary写向其余副本,其余副本写成功才会向ceph客户端响应写成功,而ceph读时直接从primary读取。综合考虑,将primary放在基于SSD的OSD上,其余副本放在基于HDD的OSD上,步骤大体如下:
1.1 设置ceph.conf 主副本倾向性选择性为true
[mon]
…
monosd allow primary affinity = true
…
修改配置后强制同步到集群的其它机器,重启mon。
1.2 将hdd被选为primary的概率设置为0:
ceph osd primary-affinity osd.
1.3 编写新的crush rule 使得主副本一定落在ssd上,假设bucket只有host:
rule ssd-primary-rule{
ruleset 1
typereplicated
min_size 2
max_size 3
step take default class ssd
step chooseleaf firstn 1 type host
step emit
step take default class hdd
step chooseleaf firstn -1 type host
step emit
}
1.4 编译crush rule:
1.4.1 获取ceph集群crush map:
ceph osd getcrushmap -o{compiled-crushmap-filename}
1.4.2 反编译获取的map二进制文件:
crushtool -d{compiled-crushmap-filename} -o {decompiled-crushmap-filename}
1.4.3 将1.3中编写的rule添加到反编译可编辑文件的rule集合中;
1.4.4 重新编译生成crush map二进制文件:
crushtool -c {decompiled-crushmap-filename}-o {compiled-crushmap-filename}
1.4.5 将新的crush map注入进ceph集群中:
ceph osdsetcrushmap -i {compiled-crushmap-filename}
1.5 创建pool并指定该pool所用crush rule 为1.3的rule:
ceph osd pool create ssdprimary_pool 128 128
ceph osd poolset ssdprimary_pool crush_rule ssd-primary-rule
至此,对于存储池ssdprimary_pool的主副本一定会落在ssd上,其余副本在hdd上。
方案2:为用户存储池分优先级:
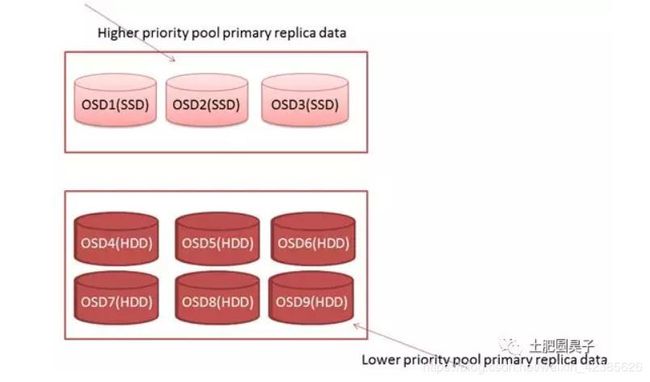
用户优先级高的所有副本指定到ssd,优先级低的所有副本指定到hdd,也是通过编写crush rule来实现,具体可模仿1.3 的crush rule 。crush rule的理解请参考论文[3]。
方案3:分层存储

分层存储利用ceph的缓存代理技术,将ssd作为hdd的缓存层,把客户端对hdd的写与读全部引到对ssd的写与读,而用户本身不用关心其实现细节及后端配置。实现这样的功能,需要进行如下配置:
3.1 创建两个crush rule, 使得cache pool能够全部选择ssd,storage pool能够全部选择hdd:
rule high-priority{
id 2
type replicated
min_size 2
max_size 3
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}
rule low-priority{
id 3
type replicated
min_size 2
max_size 3
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
3.2. 分别创建后端存储池和前端缓存池:
ceph osd pool create test_storage 64 64 low-priority
ceph osd pool create test_cache 64 64 high-priority
3.3. 设置缓存池为存储池的tier:
ceph osd tier add test_storage test_cache
3.4. 设置缓存模式:
ceph osd tier cache-mode test_cachewriteback
3.5. 打通客户端从存储池到缓存池的交互:
ceph osd tier set-overlay test_storage test_cache
至此,之后客户端对真正后端存储池的所有操作将被透明化到前端缓存池,当然,由于缓存的存在,缓存刷写参数的配置将会很大程度上影响性能。
三种混合硬件存储架构方案,具体哪一种能将存储性能发挥到最优,还需要不断测试对比以及根据实际业务进行配置与调整,没有绝对的好与坏。
[1]. https://ceph.com/
[2]. Sage A.Weil, Andrew W.Leung,Scott A. Brandt, Carlos Maltzahn. RADOS:A Scalable,Reliable Storage Service for Petabyte-scale Storage Clusters.
[3]. Sage A.Weil, Andrew W.Leung, Ethan L.Miller, CarlosMaltzahn. CRUSH: Controlled, Scalable, Decentralized Placement of ReplicatedData.