Hadoop初识、架构探讨
Hadoop简介:
Hadoop官网:http://hadoop.apache.org/
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop 底层用Java语言、跨平台性,可以部署在廉价的计算机集群中。
Hadoop在分布式环境下提供了海量数据的处理能力
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop。
Hadoop核心:
Hadoop组成:
- 分布式文件系统 HDFS(Hadoop Distributed File System) | 存储系统
- 分布式计算 MapReduce | 并行运算框架
Hadoop的特性:
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 持多种编程语言
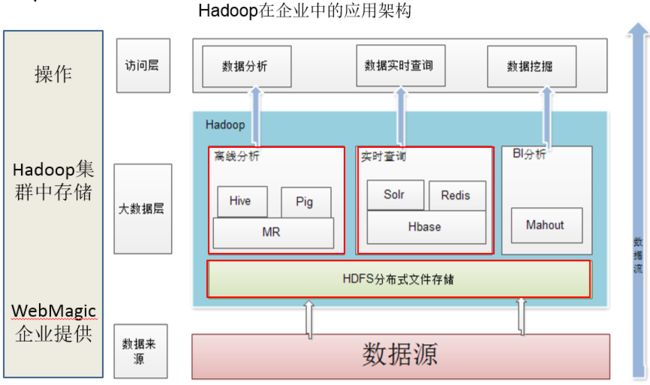
Hadoop 生态系统架构
Hadoop的项目结构不断丰富发展,已经形成一个丰富的Hadoop生态系统。
Hadoop1 生态系统架构
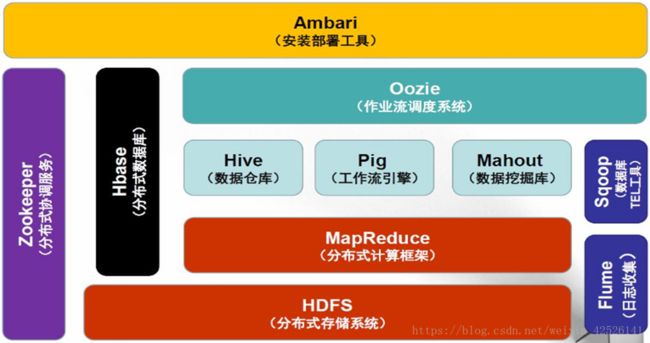
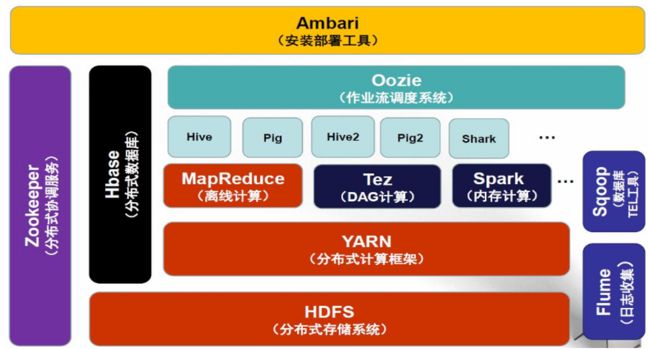
Hadoop2 生态系统架构

- HDFS:构建于廉价计算机集群之上的分布式文件系统,低成本、高可靠性、高吞吐量
- MapReduce:分布式编程模型和软件框架,用于在集群上编写对海量数据处理的并行化程序
- Common:整体架构提供基础支撑性功能,主要包括了文件系统、RPC和数据串行化库
- Hive:数据仓库工具,将结构化数据文件映射为库表,并提供强大的类SQL查询功能
- Hbase:分布式的、面向列的数据库,是一个适合于非结构化海量数据存储的数据库
- Pig:适合海量数据分析的脚本语言工具,包括了一个数据分析语言和支持的运行环境
- Sqoop:在Hadoop与传统数据库间进行数据交换的工具,支持两者之间的数据导入和导出
- Zookeeper:维护Hadoop集群的配置和命名信息,并提供分布式锁同步功能和群组管理功能
- Ambari:安装、管理和监控Hadoop集群的Web界面工具。目前已支持大部分组件的管理,就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群
Hadoop的生态圈
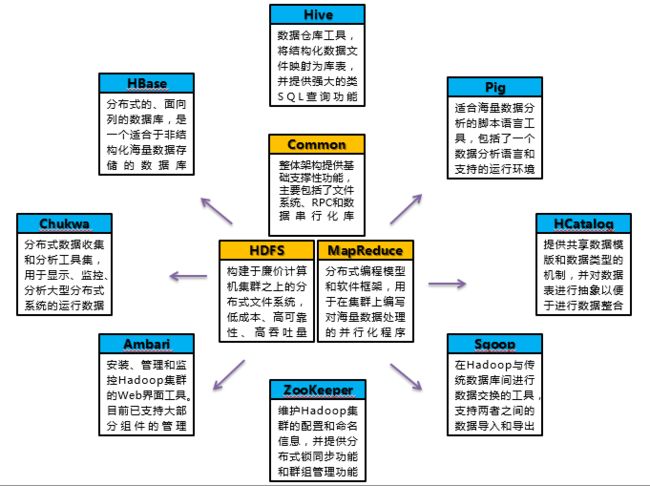
Hadoop生态系统详解:
- HDFS:分布式文件系统
- MapReduce:分布式并行编程模型
- YARN:资源管理和调度器
- Tez:运行在YARN之上的下一代Hadoop查询处理框架,它会将很多的mr任务分析优化后构建一个有向无环图,保证最高的工作效率
- Hive:Hadoop上的数据仓库
- Hbase:Hadoop上的非关系型的分布式数据库
- Pig:一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin
- Sqoop:用于在Hadoop与传统数据库之间进行数据传递
- Oozie ['u:zɪ]:Hadoop上的工作流管理系统
- Zookeeper:提供分布式协调一致性服务
- Storm:流计算框架
- Flume:一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
- Ambari:Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控
- Kafka:一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据
- Spark:类似于Hadoop MapReduce的通用并行框架
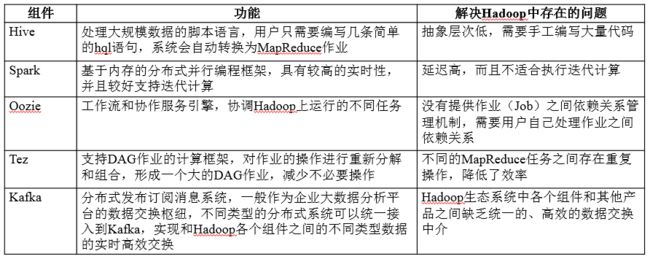
Hadoop项目结构
| 组件 |
功能 |
| HDFS |
分布式文件系统 |
| MapReduce |
分布式并行编程模型 |
| YARN |
资源管理和调度器 |
| Tez |
运行在YARN之上的下一代Hadoop查询处理框架,它会将很多的mr任务分析优化后构建一个有向无环图,保证最高的工作效率 |
| Hive |
Hadoop上的数据仓库 |
| HBase |
Hadoop上的非关系型的分布式数据库 |
| Pig |
一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop |
用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie |
Hadoop上的工作流管理系统 |
| Zookeeper |
提供分布式协调一致性服务 |
| Storm |
流计算框架 |
| Flume |
一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari |
Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka |
一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark |
类似于Hadoop MapReduce的通用并行框架 |
Hadoop2新特性详解:HDFS HA和HDFS Federation
HDFS HA
Hadoop1组件及功能:
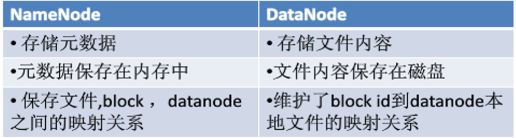
名称节点保存元数据:
- 在磁盘上:FsImage和EditLog
- 在内存中:映射信息,即文件包含哪些块,每个块存储在哪个数据节点
HDFS 1.0存在单点故障问题,第二名称节点(SecondaryNameNode)无法解决单点故障问题
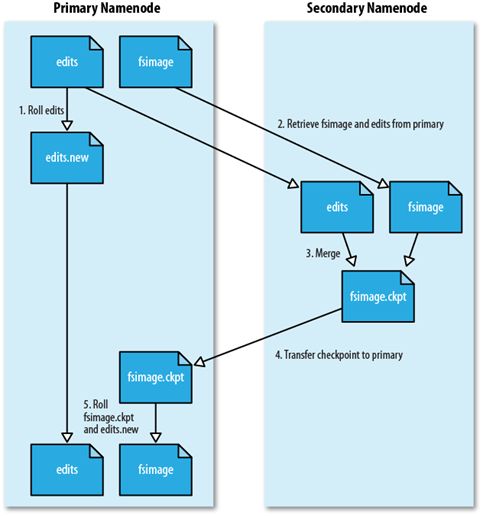
- SecondaryNameNode会定期和NameNode通信
- 从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下
- 执行EditLog和FsImage文件合并
- 将新的FsImage文件发送到NameNode节点上
- NameNode使用新的FsImage和EditLog(缩小了)
第二名称节点用途:
- 不是热备份
- 主要是防止日志文件EditLog过大,导致名称节点失败恢复时消耗过多时间
- 附带起到冷备份功能
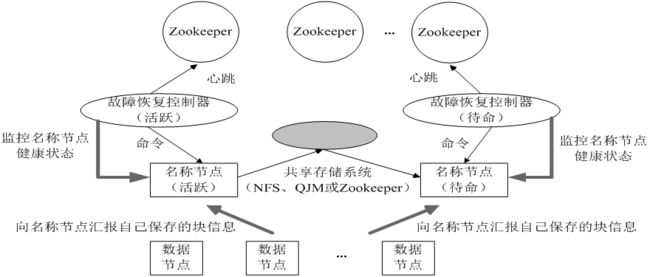
HDFS HA(High Availability)是为了解决单点故障问题:
- HA集群设置两个名称节点,“活跃(Active)”和“待命(Standby)”
- 两种名称节点的状态同步,可以借助于一个共享存储系统来实现
- 一旦活跃名称节点出现故障,就可以立即切换到待命名称节点
- Zookeeper确保一个名称节点在对外服务
- 名称节点维护映射信息,数据节点同时向两个名称节点汇报信息
HDFS Federation
1.HDFS1.0中存在的问题
- 单点故障问题
- 不可以水平扩展(是否可以通过纵向扩展来解决?)
- 系统整体性能受限于单个名称节点的吞吐量
- 单个名称节点难以提供不同程序之间的隔离性
- HDFS HA是热备份,提供高可用性,但是无法解决可扩展性、系统性能和隔离性
2.HDFS Federation的设计
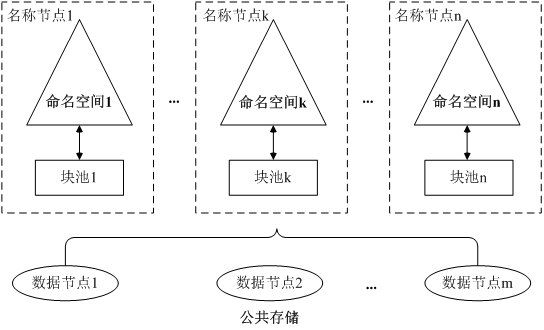 HDFS Federation架构
HDFS Federation架构
- 在HDFS Federation中,设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟(Federation)关系,不需要彼此协调。并且向后兼容
- HDFS Federation中,所有名称节点会共享底层的数据节点存储资源,数据节点向所有名称节点汇报
- 属于同一个命名空间的块构成一个“块池”
3. HDFS Federation的访问方式
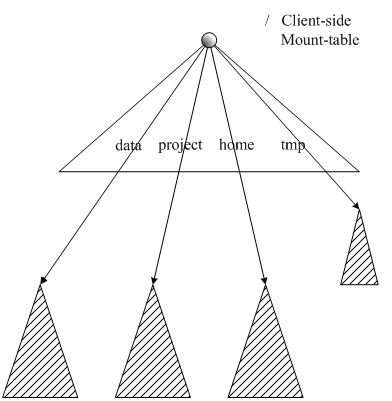 每个阴影三角形代表一个独立的命名空间
每个阴影三角形代表一个独立的命名空间
名称节点1维护的命名空间
名称节点2维护的命名空间
客户端挂载表方式访问多个命名空间
- 对于Federation中的多个命名空间,可以采用客户端挂载表(Client Side Mount Table)方式进行数据共享和访问
- 客户可以访问不同的挂载点来访问不同的子命名空间
- 把各个命名空间挂载到全局“挂载表”(mount-table)中,实现数据全局共享
- 同样的命名空间挂载到个人的挂载表中,就成为应用程序可见的命名空间
4.HDFS Federation相对于HDFS1.0的优势
HDFS Federation设计可解决单名称节点存在的以下几个问题:
(1)HDFS集群扩展性。多个名称节点各自分管一部分目录,使得一个集群可以扩展到更多节点,不再像HDFS1.0中那样由于内存的限制制约文件存储数目
(2)性能更高效。多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点管理,这样不同业务之间影响很小
需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每个名称节点都存在在单点故障问题,需要为每个名称节点部署一个后备名称节点,以应对名称节点挂掉对业务产生的影响
Yarn—资源管理调度框架
MapReduce1.0的缺陷:
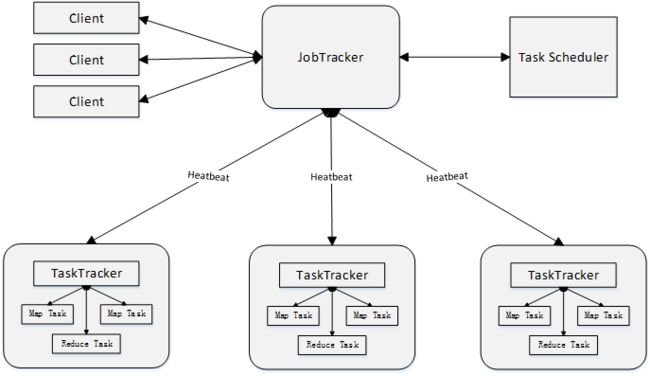 MapReduce1.0体系结构
MapReduce1.0体系结构
- (1)存在单点故障
- (2)JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
- (3)容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
- (4)资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
Yarn设计思路:
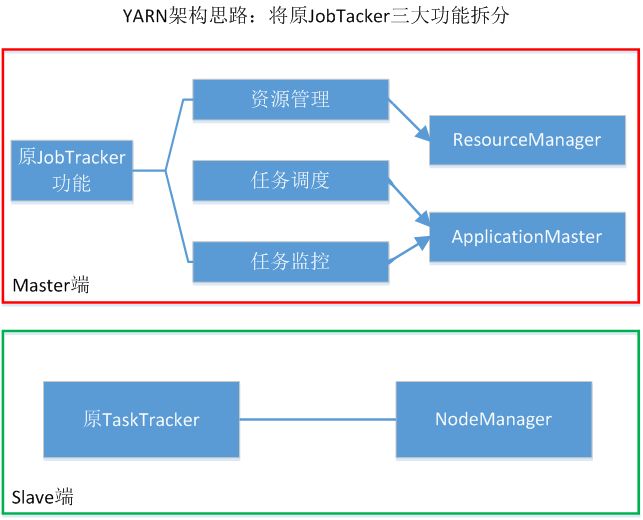
- MapReduce1.0既是一个计算框架,也是一个资源管理调度框架
- 到了Hadoop2.0以后,MapReduce1.0中的资源管理调度功能,被单独分离出来形成了YARN,它是一个纯粹的资源管理调度框架,而不是一个计算框架
- 被剥离了资源管理调度功能的MapReduce 框架就变成了MapReduce2.0,它是运行在YARN之上的一个纯粹的计算框架,不再自己负责资源调度管理服务,而是由YARN为其提供资源管理调度服务
Yarn体系结构:
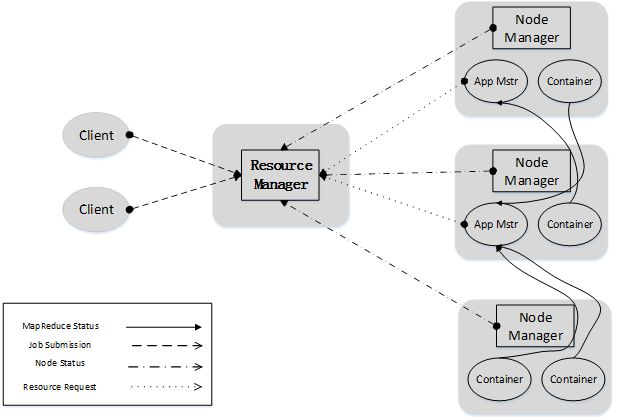
ResourceManager
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
- ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)
- 调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”
- 容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量
- 调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器
- 应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动等
NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManger的命令
- 处理来自ApplicationMaster的命令
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
- 容器生命周期管理
- 监控每个容器的资源(CPU、内存等)使用情况
- 跟踪节点健康状况
- 以“心跳”的方式与ResourceManager保持通信
- 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
- 接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的执行状态
ApplicationMaster
- 为应用程序申请资源,并分配给内部任务
- 任务调度、监控与容错
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。
ApplicationMaster的主要功能是:
(1)当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源;
(2)把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”;
(3)与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);
(4)定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息;
(5)当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
在集群部署方面,YARN的各个组件是和Hadoop集群中的其他组件进行统一部署的:
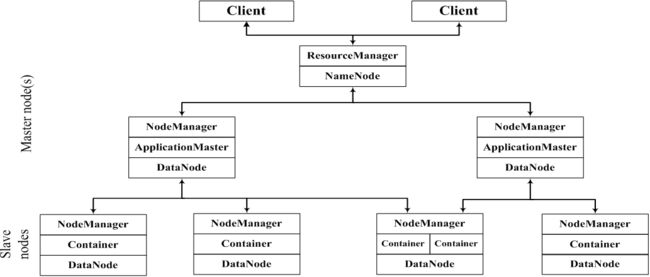
Yarn工作流程:
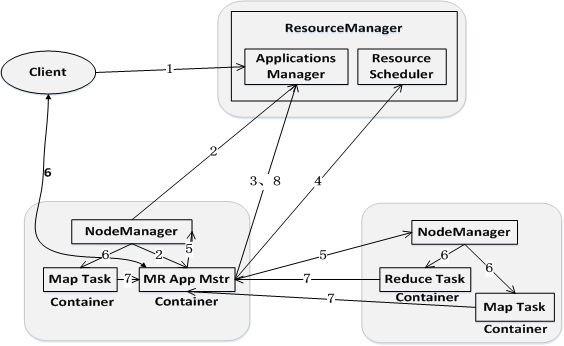
步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
步骤2:YARN中的ResourceManager负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个ApplicationMaster
步骤3:ApplicationMaster被创建后会首先向ResourceManager注册
步骤4:ApplicationMaster采用轮询的方式向ResourceManager申请资源
步骤5:ResourceManager以“容器”的形式向提出申请的ApplicationMaster分配资源
步骤6:在容器中启动任务(运行环境、脚本)
步骤7:各个任务向ApplicationMaster汇报自己的状态和进度
步骤8:应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己
Yarn框架与MapReduce1.0框架的对比分析:
从MapReduce1.0框架发展到YARN框架,客户端并没有发生变化,其大部分调用API及接口都保持兼容,因此,原来针对Hadoop1.0开发的代码不用做大的改动,就可以直接放到Hadoop2.0平台上运行。
总体而言,YARN相对于MapReduce1.0来说具有以下优势:
- 大大减少了承担中心服务功能的ResourceManager的资源消耗
- ApplicationMaster来完成需要大量资源消耗的任务调度和监控
- 多个作业对应多个ApplicationMaster,实现了监控分布化
- MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是,只能支持MapReduce编程模型。而YARN则是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架,只要编程实现相应的ApplicationMaster
- YARN中的资源管理比MapReduce1.0更加高效
- 以容器为单位,而不是以slot为单位
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架:
- MapReduce实现离线批处理
- 使用Impala实现实时交互式查询分析
- 使用Storm实现流式数据实时分析
- 使用Spark实现迭代计算
这些产品通常来自不同的开发团队,具有各自的资源调度管理机制。
为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,即“一个框架一个集群”。
导致问题:
- 集群资源利用率低
- 数据无法共享
- 维护代价高
YARN的目标就是实现“一个集群多个框架”。