用python制作一个千千音乐的简单爬虫
-环境:python3.6-模块:requests,发送http请求,安装:pip install requests-ide:pycharm-浏览器:chrome.分析网页
主要内容:
获取千千音乐的url:
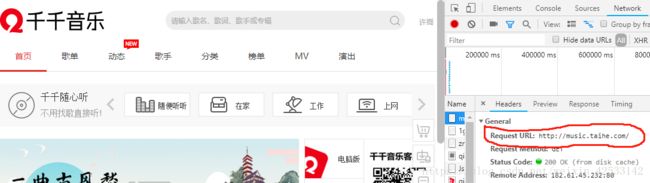
分析MP3的url的下载url:
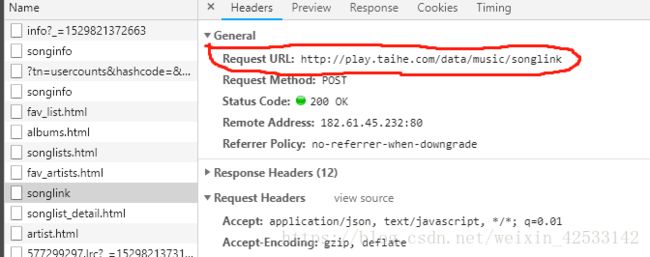
分析MP3的From data:

song_api = 'http://play.taihe.com/data/music/songlink' data = {'songIds': ','.join(song_ids), 'hq': 0, 'type': 'mp3', 'pt': 0, 'flag': 1, 's2p': 650, 'prerate': 128, 'bwt': 266, 'dur': 231000, 'bat': 266, 'bp': 100, 'pos': 65833, 'auto': 0}
通过正则表达式批量获取songids:
song_ids = re.findall(
r'sid":(\d+),', search_html)
代码实操:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import re
# 搜索歌曲
from requests import Response
data = {'key': '周杰伦'}
音乐搜索的URL
search_url = 'http://music.taihe.com/search'
# 发送http请求
search_responset = requests.get(search_url, params=data)
# 设置编码属性
search_responset.encoding = 'utf-8'
search_html = search_responset.text
song_ids = re.findall(r'sid":(\d+),', search_html)
song_api = 'http://play.taihe.com/data/music/songlink'
data = {'songIds': ','.join(song_ids), 'hq': 0, 'type': 'mp3', 'pt': 0, 'flag': 1, 's2p': 650, 'prerate': 128,
'bwt': 266, 'dur': 231000, 'bat': 266, 'bp': 100, 'pos': 65833, 'auto': 0}
# 发送请求
song_response = requests.post(song_api, data=data)
# 将返回来的数据转换为字典
song_info = song_response.json()
song_info = song_info['data']['songList']
# 遍历下载
for song in song_info:
song_name = song['songName']
with open('%s.mp3' % song_name, 'wb')as f:
# 下载MP3
print(song['songLink'])
response = requests.get(song['songLink'])
f.write(response.content)
运行结果:

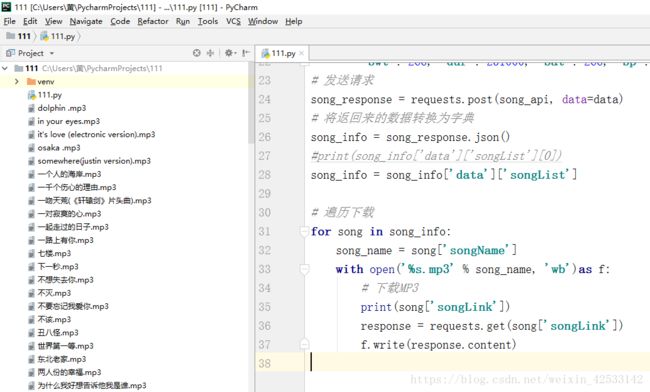
可通过不同key 下载不同歌手的歌曲,python小白,有什么不足希望大家指出。