darknet框架YOLOv3训练数据
////本文只列出需要注意的点,其他过程所附链接总结更全面。在此对本文所有引用链接表示感谢!
- 环境
win10+opencv3.4+cuda10.0+vs2017
本人安装的VS2017但是darket好像不支持V141的工具集,然后需要下载V140工具集.OPENCV不要超过3.4版本。
2下载学习框架与数据集制作
下载地址:https://github.com/AlexeyAB/darknet
(1) 进入\darknet-master\build\darknet目录,由于darknet.vcxproj 中默认cuda10.0,,所以需要利用编辑器(记事本即可)打开darknet.vcxproj ,修改成个人所安装版本,因为本人是10.0并没有修改。
(2)其他部分参考https://blog.csdn.net/kk123k/article/details/86696540
(3)数据制作更多是参考https://blog.csdn.net/lixiaoyu101/article/details/86537128
(4)对于自己下载的图片,标注之前需要规范命名,在此给出opencv程序
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
int main() {
string pattern_jpg = "你的图片文件夹地址*.*";
vector image_files;
glob(pattern_jpg, image_files);
if (image_files.size() == 0) {
cout << "No image files[jpg]" << endl;
return 0;
}
for (unsigned int frame = 0; frame < image_files.size(); ++frame) {//image_file.size()代表文件中总共的图片个数
Mat image = cv::imread(image_files[frame]);
string s = to_string(frame);
string name = "D:\\my_picture\\2019_"+string(6 - s.size(), '0') + s + ".jpg";//根据个人习惯设置个年份,保持和VOC数据集一致
imwrite(name, image);
cout << "已处理" << frame + 1 << "张照片" << endl;
waitKey(30);
}
}
对于下载他人数据,仅需要对其某一类图片进行提取,可以使用以下程序提取,当然是用整个数据集也不耽误某一类的训练,这一步当初个人对训练理解不透彻。
# -*- coding: utf-8 -*-
# @Function:There are 20 classes in VOC data set. If you need to extract specific classes, you can use this program to extract them.
import os
import shutil
ann_filepath='你的位置/Annotations/'
img_filepath='你的位置JPEGImages/'
img_savepath='你的位置/JPEGImages_out/'
ann_savepath='你的位置Annotations_plane_out/'
if not os.path.exists(img_savepath):
os.mkdir(img_savepath)
if not os.path.exists(ann_savepath):
os.mkdir(ann_savepath)
names = locals()
classes = ['aeroplane','bicycle','bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow','diningtable',
'dog', 'horse', 'motorbike', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor', 'person']
for file in os.listdir(ann_filepath):
print(file)
fp = open(ann_filepath + '\\' + file)
ann_savefile=ann_savepath+file
fp_w = open(ann_savefile, 'w')
lines = fp.readlines()
ind_start = []
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
classes1 = '\t\taeroplane \n'
#classes2 = '\t\tmotorbike \n'
#classes3 = '\t\tbus \n'
# classes4 = '\t\tcar \n'
#classes5 = '\t\tperson \n'//根据个人需要填写类别,并修改下方判断语句。
#在xml中找到object块,并将其记录下来
while "\t\n")
ind_end.append(b)
lines_id_end[b] = "delete"
#names中存放所有的object块
i = 0
for k in range(0, len(ind_start)):
names['block%d' % k] = []
for j in range(0, len(classes)):
if classes[j] in lines[ind_start[i] + 1]:
a = ind_start[i]
for o in range(ind_end[i] - ind_start[i] + 1):
names['block%d' % k].append(lines[a + o])
break
i += 1
#print(names['block%d' % k])
#xml头
string_start = lines[0:ind_start[0]]
#xml尾
string_end = [lines[len(lines) - 1]]
#在给定的类中搜索,若存在则,写入object块信息
a = 0
for k in range(0, len(ind_start)):
if classes1 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
# if classes2 in names['block%d' % k]:
# a += 1
# string_start += names['block%d' % k]
# if classes3 in names['block%d' % k]:
# a += 1
# string_start += names['block%d' % k]
# if classes4 in names['block%d' % k]:
# a += 1
# string_start += names['block%d' % k]
# if classes5 in names['block%d' % k]:
# a += 1
# string_start += names['block%d' % k]
string_start += string_end
for c in range(0, len(string_start)):
fp_w.write(string_start[c])
fp_w.close()
#如果没有我们寻找的模块,则删除此xml,有的话拷贝图片
if a == 0:
os.remove(ann_savepath+file)
else:
name_img = img_filepath + os.path.splitext(file)[0] + ".jpg"
shutil.copy(name_img, img_savepath)
fp.close()
3 训练
(1) 训练的大部分操作前面链接都给出,现在要注意的在yolov3-dbj.cfg中最好修改MAXbatch,默认太大,要不然训练时输出不明显,大约每一类按照2000来改。当然这个大一点也没啥,主要是好看。训练开始后会在命令窗打印出训练日志和loss
(2)对于我们可能要把训日志保存下来,用来和其他算法进行对比,此时我们需要在运行训练时加入一句
darknet.exe detector train data/obj.data cfg/yolov3-obj.cfg weights/yolov3-obj_2000.weights**>>tee_visualization/train_yolov3.log** 其中 >>tee_visualization/train_yolov3.log是需要加入的,tee_visualization是在darknet/X64文件夹下穿件的文件夹,可能你会注意到前边我用的yolov3-obj_2000.weights,是的!我是在训练2000轮候停止过,然后接着输出的权重继续训练的。此时的命令窗没有打印训练日志而是保存在了tee_visualization/train_yolov3.log下
(3)保存的训练日志,可以绘制其LOSS函数,IOU,mAP等,请参考这两位博主。
https://blog.csdn.net/yudiemiaomiao/article/details/72469135
https://blog.csdn.net/qq_33614902/article/details/83418441
在此向他们再次表示感谢。
在opencv4,1中直接调用训练好的模型,出现了一些问题,抛出了异常,如图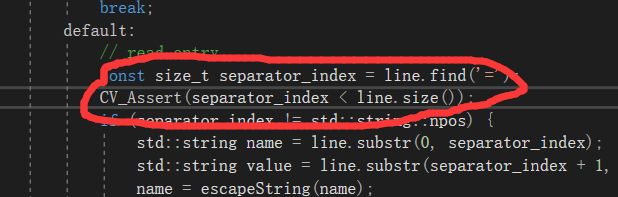
查看了一下,是配置文件的问题,应该修改成和官方配置文件一样的格式,当时在训练的时候对配置文件进行了修改,主要是这里
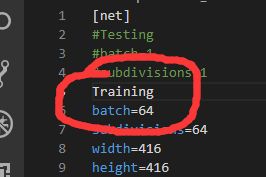
训练时打开了train字符串,但是这个地方和官网训练的配置文件的格式不太一样,opencv4.1解析文件出错,把train注释掉就可以,当然训练的时候没有注意打开,直接使用也不会有什么问题,也不影响训练,看来训练时打开这个字符多此一举。