tensorflow实战—VGGNET16–迁移学习训练自己的数据集
tensorflow实战—VGGNET16–迁移学习训练自己的数据集
本文参考----https://blog.csdn.net/wangds000/article/details/99670777
先介绍一下自己的电脑配置环境吧。这次试验用cpu跑的,电脑内存24g,没用gpu显卡就不介绍了。64位操作系统,处理器i7.
数据集采用的是ISIC-2018任务三中皮肤镜数据集。
在参考的博主迁移学习vggnet16的网络模型失效了,我在网上找了个,存放在百度云了,有需要的朋友可以下载。
链接:https://pan.baidu.com/s/1ojhtxjX-XVb2ONBAp-ozQA
提取码:ykim
数据介绍
下面的是自己的数据集存放位置。(0 AKIEC 1 BCC 2 BKL 3 DF 4 MEL 5 NV 6 VASC)七个病种数据
-DATA
----0
----1
----2
----3
----4
----5
----6
-logs
-model
-test
creat_tfrecords.py
test.py
train.py
VGG16.py
vgg16.npy(vgg16网络模型)
数据转换
将七类数据集转化为tfrecord格式,imgpath为你训练数据的路径,代码如下
import os
import tensorflow as tf
from PIL import Image
import sys
import matplotlib.pyplot as plt
def creat_tf(imgpath):
cwd = os.getcwd()
classes = os.listdir(cwd + imgpath)
# 此处定义tfrecords文件存放
writer = tf.python_io.TFRecordWriter("train.tfrecords")
for index, name in enumerate(classes):
class_path = cwd + imgpath + name + "/"
print(class_path)
if os.path.isdir(class_path):
for img_name in os.listdir(class_path):
img_path = class_path + img_name
img = Image.open(img_path)
img = img.resize((224, 224))
img_raw = img.tobytes()
example = tf.train.Example(features=tf.train.Features(feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[int(name)])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
writer.write(example.SerializeToString())
print(img_name)
writer.close()
def read_example():
#简单的读取例子:
for serialized_example in tf.python_io.tf_record_iterator("train.tfrecords"):
example = tf.train.Example()
example.ParseFromString(serialized_example)
#image = example.features.feature['img_raw'].bytes_list.value
label = example.features.feature['label'].int64_list.value
# 可以做一些预处理之类的
# print(label)
if __name__ == '__main__':
imgpath = 'DATA/'
creat_tf(imgpath)
加载vggnet16迁移学习模型
可能存在tensorflow版本问题,tf.reset_default_graph()模块引用不正确,读者可以百度一下自己tensorflow的版本信息,选用正确的模块书写格式。
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
# 加载预训练模型
data_dict = np.load('vgg16.npy', encoding='latin1').item()
# 打印每层信息
def print_layer(t):
print(t.op.name, ' ', t.get_shape().as_list(), '\n')
# 定义卷积层
"""
此处权重初始化定义了3种方式:
1.预训练模型参数
2.截尾正态,参考书上采用该方式
3.xavier,网上blog有采用该方式
通过参数finetrun和xavier控制选择哪种方式,有兴趣的可以都试试
"""
def conv(x, d_out, name, fineturn=False, xavier=False):
d_in = x.get_shape()[-1].value
with tf.name_scope(name) as scope:
# Fine-tuning
if fineturn:
kernel = tf.constant(data_dict[name][0], name="weights")
bias = tf.constant(data_dict[name][1], name="bias")
#print("fineturn")
elif not xavier:
kernel = tf.Variable(tf.truncated_normal([3, 3, d_in, d_out], stddev=0.1), name='weights')
bias = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[d_out]),
trainable=True,
name='bias')
#print("truncated_normal")
else:
kernel = tf.get_variable(scope+'weights', shape=[3, 3, d_in, d_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
bias = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[d_out]),
trainable=True,
name='bias')
#print("xavier")
conv = tf.nn.conv2d(x, kernel,[1, 1, 1, 1], padding='SAME')
activation = tf.nn.relu(conv + bias, name=scope)
#print_layer(activation)
return activation
# 最大池化层
def maxpool(x, name):
activation = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID', name=name)
#print_layer(activation)
return activation
# 定义全连接层
"""
此处权重初始化定义了3种方式:
1.预训练模型参数
2.截尾正态,参考书上采用该方式
3.xavier,网上blog有采用该方式
通过参数finetrun和xavier控制选择哪种方式,有兴趣的可以都试试
"""
def fc(x, n_out, name, fineturn=False, xavier=False):
n_in = x.get_shape()[-1].value
with tf.name_scope(name) as scope:
if fineturn:
weight = tf.constant(data_dict[name][0], name="weights")
bias = tf.constant(data_dict[name][1], name="bias")
#print("fineturn")
elif not xavier:
weight = tf.Variable(tf.truncated_normal([n_in, n_out], stddev=0.01), name='weights')
bias = tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[n_out]),
trainable=True,
name='bias')
#print("truncated_normal")
else:
weight = tf.get_variable(scope+'weights', shape=[n_in, n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
bias = tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[n_out]),
trainable=True,
name='bias')
#print("xavier")
# 全连接层可以使用relu_layer函数比较方便,不用像卷积层使用relu函数
activation = tf.nn.relu_layer(x, weight, bias, name=name)
#print_layer(activation)
return activation
def VGG_16(images, _dropout, n_cls):
"""
此处权重初始化方式采用的是:
卷积层使用预训练模型中的参数
全连接层使用xavier类型初始化
"""
conv1_1 = conv(images, 64, 'conv1_1', fineturn=True)
conv1_2 = conv(conv1_1, 64, 'conv1_2', fineturn=True)
pool1 = maxpool(conv1_2, 'pool1')
conv2_1 = conv(pool1, 128, 'conv2_1', fineturn=True)
conv2_2 = conv(conv2_1, 128, 'conv2_2', fineturn=True)
pool2 = maxpool(conv2_2, 'pool2')
conv3_1 = conv(pool2, 256, 'conv3_1', fineturn=True)
conv3_2 = conv(conv3_1, 256, 'conv3_2', fineturn=True)
conv3_3 = conv(conv3_2, 256, 'conv3_3', fineturn=True)
pool3 = maxpool(conv3_3, 'pool3')
conv4_1 = conv(pool3, 512, 'conv4_1', fineturn=True)
conv4_2 = conv(conv4_1, 512, 'conv4_2', fineturn=True)
conv4_3 = conv(conv4_2, 512, 'conv4_3', fineturn=True)
pool4 = maxpool(conv4_3, 'pool4')
conv5_1 = conv(pool4, 512, 'conv5_1', fineturn=True)
conv5_2 = conv(conv5_1, 512, 'conv5_2', fineturn=True)
conv5_3 = conv(conv5_2, 512, 'conv5_3', fineturn=True)
pool5 = maxpool(conv5_3, 'pool5')
'''
因为训练自己的数据,全连接层最好不要使用预训练参数
'''
flatten = tf.reshape(pool5, [-1, 7*7*512])
fc6 = fc(flatten, 4096, 'fc6', xavier=True)
dropout1 = tf.nn.dropout(fc6, _dropout)
fc7 = fc(dropout1, 4096, 'fc7', xavier=True)
dropout2 = tf.nn.dropout(fc7, _dropout)
fc8 = fc(dropout2, n_cls, 'fc8', xavier=True)
return fc8
训练
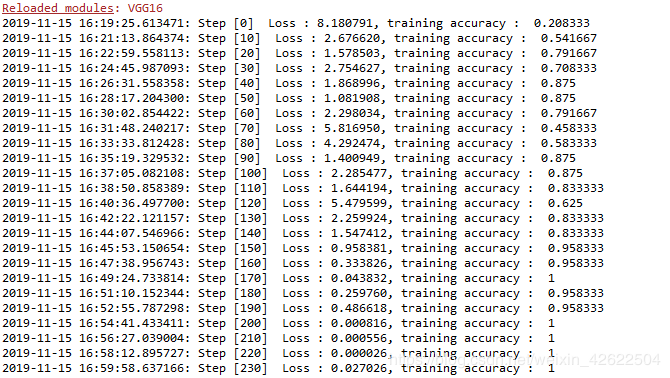
博主训练次数采用15000次,我实验的时候没有改,发生keyboardinterrupt错误,百度了下可能是线程中断问题,我猜想可能与我训练次数太多,cpu处理器处理失败,线程中断,所以我把训练次数改成了400
import tensorflow as tf
#import numpy as np
#import pdb
from datetime import datetime
#from VGG16 import *
import VGG16
#tf.reset_default_graph()
batch_size = 24
lr = 0.0001
n_cls = 29 #训练时根据自己的类别数更改
max_steps = 400
def read_and_decode(filename):
#根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue) #返回文件名和文件
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw' : tf.FixedLenFeature([], tf.string),
})
img = tf.decode_raw(features['img_raw'], tf.uint8)
img = tf.reshape(img, [224, 224, 3])
# 转换为float32类型,并做归一化处理
img = tf.cast(img, tf.float32)# * (1. / 255)
label = tf.cast(features['label'], tf.int64)
return img, label
def train():
x = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name='input')
y = tf.placeholder(dtype=tf.float32, shape=[None, n_cls], name='label')
keep_prob = tf.placeholder(tf.float32)
output = VGG16.VGG_16(x, keep_prob, n_cls)
#probs = tf.nn.softmax(output)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output, labels=y))
#train_step = tf.train.AdamOptimizer(learning_rate=0.1).minimize(loss)
train_step = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(output,1), tf.argmax(y, 1)), tf.float32))
images, labels = read_and_decode('train.tfrecords')
img_batch, label_batch = tf.train.shuffle_batch([images, labels],
batch_size=batch_size,
capacity=392,
min_after_dequeue=200)
label_batch = tf.one_hot(label_batch, n_cls, 1, 0)
# log汇总记录
summary_op = tf.summary.merge_all()
init = tf.global_variables_initializer()
#saver = tf.train.Saver()
saver = tf.train.Saver(max_to_keep=3)
max_acc = 0
with tf.Session() as sess:
sess.run(init)
train_writer = tf.summary.FileWriter('logs',sess.graph)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(max_steps):
batch_x, batch_y = sess.run([img_batch, label_batch])
# print batch_x, batch_x.shape
# print batch_y
# pdb.set_trace()
_, loss_val = sess.run([train_step, loss], feed_dict={x:batch_x, y:batch_y, keep_prob:0.8})
if i%10 == 0:
train_arr = accuracy.eval(feed_dict={x:batch_x, y: batch_y, keep_prob: 1.0})
print("%s: Step [%d] Loss : %f, training accuracy : %g" % (datetime.now(), i, loss_val, train_arr))
# 只指定了训练结束后保存模型,可以修改为每迭代多少次后保存模型
#if (i + 1) == max_steps:
#checkpoint_path = os.path.join(FLAGS.train_dir, './model/model.ckpt')
#saver.save(sess, './model/model.ckpt', global_step=i)
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str,i)
# 保存最近的3个模型参数
if train_arr > max_acc:
saver.save(sess, 'model/model.ckpt', global_step=i + 1)
coord.request_stop()
coord.join(threads)
#saver.save(sess, 'model/model.ckpt')
if __name__ == '__main__':
train()
测试
测试需要用到opencv,此时需要安装opencv库
命令:pip install opencv-python
注意:
saver.restore(sess, ‘model/model.ckpt-442’)
这个加载你的最后一次训练结果的模型(我是训练的400次,出来442我也不清楚了)
import tensorflow as tf
import numpy as np
import pdb
from datetime import datetime
from VGG16 import *
import cv2
import os
#import matplotlib.pyplot as plt
def test(path):
x = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name='input')
keep_prob = tf.placeholder(tf.float32)
# 注意更改自己的类别数,此处输出为29类
output = VGG_16(x, keep_prob, 7)
score = tf.nn.softmax(output)
# 返回每一行最大置信度所在的索引数组
f_cls = tf.argmax(score, 1)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
# 训练好的模型位置
saver.restore(sess, 'model/model.ckpt-442')
for i in os.listdir(path):
imgpath = os.path.join(path, i)
im = cv2.imread(imgpath)
im = cv2.resize(im, (224 , 224))# * (1. / 255)
im = np.expand_dims(im, axis=0)
# 测试时,keep_prob设置为1.0
pred, _score = sess.run([f_cls, score], feed_dict={x:im, keep_prob:1.0})
prob = round(np.max(_score), 4)
# 打印测试图片所属类别的索引号和置信度
print("{} rubbing class is: {}, score: {}".format(i, int(pred), prob))
# plt.imshow(im)
# plt.imshow(im1)
# plt.title(u'预测值:%i' % pred)
# plt.show()
sess.close()
if __name__ == '__main__':
# 测试图片保存在文件夹中了,图片前面数字为所属类别
path = 'C:/Users/Administrator/Desktop/vggnet19/test/'
test(path)
结果
训练结果截图:
测试结果截图: