论文阅读:Survey on Event Extraction Technology in Information Extraction Research Area综述:信息抽取研究领域的事件抽取技术
Survey on Event Extraction Technology in Information Extraction Research Area
综述:信息抽取研究领域的事件抽取技术
目录
- Survey on Event Extraction Technology in Information Extraction Research Area
- 综述:信息抽取研究领域的事件抽取技术
- 摘要
- 关键词
- I.引言
- II.事件抽取问题的描述
- A.事件抽取任务的描述
- B.事件抽取相关概念描述
- III.主要事件抽取方法
- A.基于规则和模板的事件抽取方法
- B.基于统计机器学习的事件抽取方法
- C.基于深度学习的事件抽取方法
- IV.事件抽取中的挑战
- V.事件抽取技术的发展趋势
摘要
事件抽取是信息抽取领域最具挑战性的任务之一。事件抽取技术的研究具有重要的理论意义和广泛的应用价值。本文对事件抽取技术进行了概述,描述了事件抽取的任务和相关概念,对不同领域的相关描述进行了分析,比较和归纳。然后分析,比较和总结了事件抽取的三种主要方法。这些方法各有优缺点。基于规则和模板的方法更加成熟,基于统计机器学习的方法占主导地位,基于深度学习的方法是未来的发展趋势。同时,本文还回顾了事件抽取技术的研究现状和关键技术,最后总结了事件抽取技术的当前挑战和未来的研究趋势。
关键词
事件抽取;信息抽取;模式匹配;机器学习;深度学习
I.引言
随着计算机和网络等信息技术的飞速发展,以及云计算和大数据时代的到来,信息数据呈爆炸式增长。从海量信息数据中获取有价值的信息已成为关注的焦点,信息抽取技术应运而生。信息抽取属于自然语言处理领域,随着自然语言处理的发展,已成为当前研究的热点。顾名思义,信息抽取是指从大量的文本和文档中抽取人们需要和感兴趣的信息,并对其进行结构化存储[1]。事件抽取是信息抽取的重要分支,是最具挑战性的任务之一,也是人工智能的一个问题。主要研究是从各种文本中抽取感兴趣的事件信息并以结构化的方式存储,以用于其他信息抽取业务或直接的实际应用。
事件抽取技术结合了多学科的发展成果和实际应用需求,具有重要的理论研究意义和实用价值。事件抽取是自然语言处理领域的重要组成部分,涉及信息处理、人工智能、模式匹配和数据处理。事件抽取技术的发展可以促进相关学科的融合与发展,促进自然语言处理技术的深度发展。在实际应用中,事件抽取已广泛应用于自动问答[2]、信息检索[2]、人机交互、趋势分析等领域。
II.事件抽取问题的描述
A.事件抽取任务的描述
事件抽取任务描述,不同领域具有不同的定义和不同的理解,主要体现在耶鲁大学和消息理解会议(MUC),自动内容抽取会议(ACE)和TAC KBP 2015评估会议的相关描述中。比较分析示于表I。
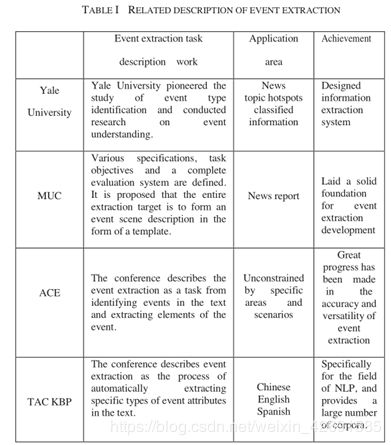
从表中可以看出,事件抽取任务的描述是一个发展中的过程,适用领域正在扩大,应用语言正在增加,评估体系也在不断完善。综上所述,事件抽取任务主要包括:事件类型识别、事件元素识别和事件元素角色分配。事件抽取的一般流程如图1所示。
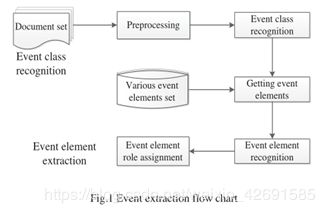
B.事件抽取相关概念描述
事件抽取的相关概念在不同领域有不同的描述。最重要的是ACE评估会议和TAC KBP评估会议,它们都描述了事件抽取的相关概念。该事件及其组件在下面分别描述。
1)事件:事件的概念尚未统一定义。它在不同领域有不同的理解。该术语起源于认知心理学,认知科学家将事件视为人类理解和记忆现实世界的基本单位。 ACE2005评估会议将事件定义为特定的人或事物在特定的时间和地点进行交互的客观事实[3]。在自然语言处理领域,事件表示在一个特定的时间或地点发生的一个或多个动作或状态变化。无论如何定义,事件都包含基本元素,例如时间、地点、人以及动词、名词或短语触发的动作。
2)触发:ACE2005评估会议也将其描述为可以触发事件的词,通常是动词或表示动作的名词和短语;也称为事件指示符。 TAC KBP评估会议将其描述为触发事件的核心词。简而言之,触发词可以确定事件的类型,并反映事件的最重要特征,通常是动词或具有动词性质的名词和短语,它们在识别事件类型中起关键作用。
3)事件元素:ACE评估会议将事件元素描述为与事件发生相关的实体和实体属性信息,包括时间、地点、人等。TAC KBP评估会议将其定义为参与者事件,主要由实体和时间等信息组成。事件元素通常指事件的各种元素,可以反映事件的主题信息。
4)事件类别:不同区域有不同的定义。 ACE2005语料库定义了8个事件类别和33个子类别。life,movement,business,contact,justice,personnel,transaction,and conflict这8个类别。TAC KBP评估会议定义了9个类别和38个子类别,其中一个主要类别(manufacture)和5个子类别比ACE多。这五个子类别是manufacture的1个子类别,interaction contact的2个子类别,movement的1个子类别以及transaction的1个子类别。
III.主要事件抽取方法
近年来,在ACE评估会议的推动下,事件抽取的研究发展迅速,取得了一些理论成果,并开发了一些实用的系统。与英文相比,尤其是英文,英文事件抽取研究起步较早,理论更成熟,但中文事件抽取研究也取得了一定成果。国内对中文事件抽取技术的研究起步较晚,但也取得了一定的成就。最初的研究主要是基于规则和模板的方法,后来发展为基于统计机器学习的方法。当前的研究主要倾向于基于深度学习的方法。
A.基于规则和模板的事件抽取方法
早期的事件抽取方法主要是基于规则的方法,后来发展成为基于模式匹配的方法。这些方法本质上是相同的,也就是说,它们需要构建规则或模板。基于模式匹配的事件抽取方法是指将要抽取的事件语句与相应的模板进行匹配的方法,其基本原理如图2所示。
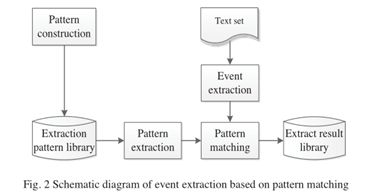
北京科技大学的Meiying Jia用模式匹配法研究军事演习信息的抽取[4]。它在抽取的不同阶段使用分层自动分类方法、基于子模式的引导方法和基于语料库的标注。其模式匹配方法侧重于模式获取和匹配算法,如图3所示。
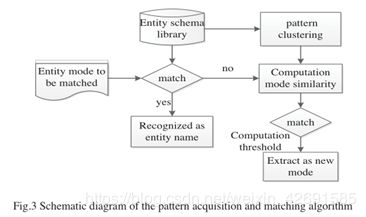
以上研究表明,模式匹配方法的核心是事件抽取模式的构建。Jifa Jiang研究了模式的自动获取[5],并提出了一种基于领域无关的概念知识库的事件抽取模型学习方法。只要定义了IE任务,他构建的系统就可以从原始语料库自动学习IE模式,而无需提供子模式和语料库的预处理,从而大大提高了效率。另一名学者Ming Luo基于有限状态机构建了层次化的词汇语义规则模型,用于自动抽取各种财务事件信息[6],具有较高的准确性。Liao et al. [7]在构造事件抽取模板时使用谓词论元模式,并通过相似性扩展原始模板。
基于模式匹配的方法较好地应用于特定领域,但该方法的可移植性和灵活性较差。当它是跨域的时,它需要重建模型。模型的构建需要大量时间和人力。使用机器学习和其他方法可以加快模式的获取,但是会带来不同模式之间的冲突。
B.基于统计机器学习的事件抽取方法
通过机器学习抽取事件本质上是将事件抽取视为分类问题。主要任务是选择合适的特征并构造合适的分类器。与模式匹配方法相比,机器学习方法可应用于不同领域,具有较高的可移植性和灵活性,并已被广泛使用。分类器通常是基于统计模型构建的。事件抽取中的主要统计模型主要包括最大熵模型、隐马尔可夫模型、条件随机场模型和支持向量机模型。
例如,2002年,Chieu et al.在事件元素的识别中首次应用最大熵模型,并抽取了演讲公告和人员管理事件。另一位学者H. Llorens在语义角色注释中引入了条件随机字段模型(CRF),并将其应用于TimeML事件抽取中,以提高系统的性能。国内Jiangde Yu et al. [8]提出了中文文本,基于隐马尔可夫模型(HMM)的事件抽取方法。当抽取每种类型的事件元素时,此方法将构造一个独立的隐马尔可夫模型。
为了提高事件抽取的效果,有时会结合使用多种机器学习算法。 2006年,David Ahn [2]集成了MegaM和Timbl机器学习方法来识别事件类别和事件元素。事件类型识别存在向后依赖事件元素识别的问题。 2012年,Bolei Hu et al. [9]解决这个问题很好。他们将事件抽取视为序列标注,并构建了改进的条件随机域联合标注模型。主要思想是在图模型中同时标注事件类型和事件元素。改进的CRF模型如图4所示。
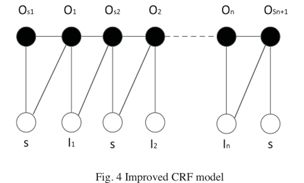
许多机器学习方法都是基于触发词进行事件识别的。基于触发词的方法在训练中引入了大量的负例,导致正例与负例之间失衡。为了解决这个问题,哈尔滨工业大学的Yanyan Zhao [10]通过结合触发词扩展和二进制分类来识别事件类别。另外,Honglei Xu提出了一种基于事件实例的事件类型识别方法[11]。该方法通过使用句子代替词作为识别示例,克服了正负大小写不平衡和数据稀疏的问题。
当前在事件抽取研究中的主导作用是基于机器学习的方法,但是该方法需要大规模的标注训练语料库。如果训练语料不足或类别单一,将严重影响事件的抽取效果,语料库的建设成为一项重要任务。但是,语料库的建设需要大量的人力和时间。为了减轻这个问题,学者们进一步探索了深度学习的方法。
C.基于深度学习的事件抽取方法
深度学习是机器学习研究领域中的一个新方向。与浅层神经网络相比,深层神经网络(DNN)具有更好的特征学习能力,其抽象数学的无监督逐层预训练。可以更有效地表征原始数据基本特征的特征。Yajun Zhang et al. [12]建立了基于深度学习的事件识别模型,并利用BP神经网络对事件进行识别,通过深度信念网络抽取词的深度语义信息。同时,文献还提出了一种混合式监督深度信念网络,将监督和非监督学习方法相结合,可以提高识别效果,控制训练时间。
传统的基于特征的事件抽取方法需要大量的特征设计工作,并且需要复杂的自然语言处理工具,这会消耗大量的人力和时间,并且会产生数据稀疏的问题。在这方面,Kai Wang[13]提出了一种基于递归神经网络(RNN)的事件抽取方法,该方法可以自动学习句子中的特征,而无需进行大量的人工特征设计工作,并克服了复杂的特征工程。
递归神经网络(RNN)广泛用于自然语言处理领域。它主要用于解决序列问题,对事件抽取有很好的效果。这是因为递归神经网络模型的结构由三层组成,即输入层x、隐藏层h和输出层y,其中隐藏层h表示递归神经的内部状态网络,如图5所示。
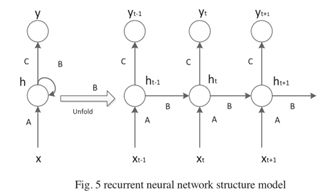
在时间t,隐藏层的输入h(t)由当前时间的输入x(t)和上一次隐藏层的输出h(t-1)组成,而h(t-1 )包含前一瞬间的输入信息和上一隐藏层中的信息。这样,通过添加前一时刻输入的隐藏层,添加了序列的历史信息,从而可以利用距离更长的信息。
另外,为避免复杂的特征工程,相关学者构建了联合学习的神经网络模型,并提出了基于联合模型的神经网络事件抽取方法。例如,Nguyen et al.提出了一种基于RNN模型的联合学习,用于事件类型识别和事件元素识别。北京邮电大学的Zhengkuan Zhang [14]设计了一种新的事件抽取框架,结合了window-winding卷积神经网络和递归神经网络,形成了一种连通学习方法,可以同时抽取事件触发词和事件元素,不仅避免了复杂的特征工程,而且还解决了错误传播的问题。
深度学习方法克服了浅层机器学习的局限性,可以学习更多抽象的数学特征,并使数据具有更好的特征表达,从而实现文本事件的有效抽取。与浅层机器学习相比,深度学习框架可以有效地指数捕获数据特征,已应用于事件抽取领域。
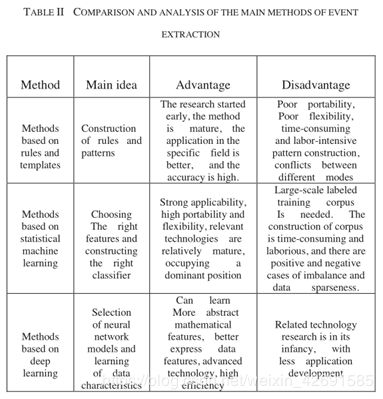
回顾了以上三个主要类别的主要事件抽取方法,每种方法都有其优点和缺点,比较分析如表II所示。
IV.事件抽取中的挑战
随着事件抽取研究的深入发展,事件抽取在理论和应用上都取得了长足的进步。然而,人工智能和大数据技术的发展对事件抽取的准确性提出了更高的要求。研发仍面临许多挑战,主要表现在以下几个方面:
1)对实体、关系识别、语法分析等相关技术的研究还不够成熟,导致级联错误。事件抽取是在实体和关系识别的基础上发展起来的。它在某种程度上取决于实体、关系识别和文本预处理的效果,但是这些基础技术仍然不够成熟。
2)事件抽取系统的现场可伸缩性和便携性并不理想。例如,有关中文事件抽取的相关研究主要集中在生物医学、微博、新闻、紧急情况等方面。其他领域和开放领域的研究很少。关于领域和跨语言事件抽取技术的研究很少。
3)缺乏大规模成熟的语料和标注语料,需要进一步完善。手动标注语料库既费时又费力,而且缺少语料库限制了事件抽取技术研究的发展。因此,大型语料库的自动构建技术方法需要进一步研究。
V.事件抽取技术的发展趋势
随着研究的深入和人工智能、大数据等先进技术的广泛应用,可以预见事件抽取技术将在未来的研究中迅速发展,并呈现出以下发展趋势:
1)随着相关技术的不断发展实体、关系识别和语法分析等技术将进一步提高事件抽取的准确性和召回率,并且深度学习等新的技术方法将得到广泛使用。
2)随着跨文本语义理解和多语言文本处理技术的发展,跨文本和跨语言事件抽取的研究将更加广泛,相关的应用系统将不断发展。
3)未来事件抽取研究将集中在应用程序上,并且该领域将继续扩展,不再局限于特定领域,而是更加面向开放领域,并且系统的可移植性将得到进一步改善。
4)相关的语料库自动构建技术将取得突破,不再需要大量的人工能量,而语料库的丰富将极大地促进事件抽取技术的发展。