安装配置Hadoop伪分布式集群(CentOS7下的Hadoop伪分布式集群的安装部署)
工具/原料:
1.hadoop 2.7.7
2.jdk1.8
下载地址:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
安装过程:
在安装hadoop伪分布式之前先检查是否安装配置好JDK,输入java -version可以看到自己的jdk版本,若未安装jdk请先安装jdk,安装方法参考上一篇文章:
https://mp.csdn.net/postedit/84400558
1.准备Hadoop的安装路径,本人喜欢将自己安装的软件放在/apps/路径下,根据自己的需求创建目录
cd /
sudo mkdir -r /apps/hadoop
2.切换到下载好的hadoop路径下,我这里的hadoop压缩包存放在/data目录下,解压hadoop
cd /data
sudo tar -zxvf hadoop-2.7.7.tar.gz
3.将解压好的hadoop拷贝到安装路径/apps下,并重命名为hadoop
sudo cp -r hadoop-2.7.7 /apps/hadoop/
4.修改用户环境变量,将hadoop的路径添加到path中。先打开用户环境变量文件。
sudo vim ~/.bashrc
5.将以下内容追加到环境变量~/.bashrc文件中。
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH

执行source命令,让java环境变量生效。
source ~/.bashrc
6.验证hadoop环境变量配置是否正常,本人计算机中安装的为hadoop2.7.6
hadoop version

7.下面来修改hadoop本身相关的配置。首先切换到hadoop配置目录下。
cd /apps/hadoop/etc/hadoop
8.输入vim /apps/hadoop/etc/hadoop/hadoop-env.sh,打开hadoop-env.sh配置文件。
vim /apps/hadoop/etc/hadoop/hadoop-env.sh
9.确认JAVA_HOME路径是否正确
export JAVA_HOME=/apps/java

10.输入vim /apps/hadoop/etc/hadoop/core-site.xml,打开core-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/core-site.xml
修改
hadoop.tmp.dir
/data/tmp/hadoop/tmp
fs.defaultFS
hdfs://0.0.0.0:9000
配置项说明:
hadoop.tmp.dir :配置hadoop处理过程中,临时文件的存储位置。这里的目录/data/tmp/hadoop/tmp需要提前创建。
fs.defaultFS :配置hadoop HDFS文件系统的地址。
下面创建临时文件存储位置:
mkdir -p /data/tmp/hadoop/hdfs
11.输入vim /apps/hadoop/etc/hadoop/hdfs-site.xml,打开hdfs-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/hdfs-site.xml
修改
dfs.namenode.name.dir
/data/tmp/hadoop/hdfs/name
dfs.datanode.data.dir
/data/tmp/hadoop/hdfs/data
dfs.replication
1
dfs.permissions.enabled
false
配置项说明:
dfs.namenode.name.dir : 配置元数据信息存储位置;
dfs.datanode.data.dir : 配置具体数据存储位置,这里路径需要提前创建;
dfs.replication : 配置每个数据库备份数,由于目前我们使用1台节点,所以,设置为1。
dfs.replications.enabled : 配置hdfs是否启用权限认证
下面创建数据存储位置:
mkdir -p /data/tmp/hadoop/hdfs
12.输入vim /apps/hadoop/etc/hadoop/slaves,打开slaves配置文件。
vim /apps/hadoop/etc/hadoop/slaves
将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,所以slaves文件内容为:
localhost
13.下面格式化HDFS文件系统。执行:
hadoop namenode -format
14.下面来配置MapReduce相关配置。下面将mapreduce的配置文件mapred-site.xml.template,重命名为mapred-site.xml.
mv /apps/hadoop/etc/hadoop/mapred-site.xml.template /apps/hadoop/etc/hadoop/mapred-site.xml
输入vim /apps/hadoop/etc/hadoop/mapred-site.xml,打开mapred-site.xml配置文件.
vim /apps/hadoop/etc/hadoop/mapred-site.xml
修改
mapreduce.framework.name
yarn
15.输入vim /apps/hadoop/etc/hadoop/yarn-site.xml,打开yarn-site.xml配置文件
vim /apps/hadoop/etc/hadoop/yarn-site.xml
将yarn相关配置,添加到
yarn.nodemanager.aux-services
mapreduce_shuffle
16.下面来启动计算层面相关进程,切换到hadoop启动目录
cd /apps/hadoop/sbin
执行命令./start-all.sh,启动hadoop,
./start-all.sh
若没有配置SSH免密登陆,中途可能需要输入多次密码,密码为当前用户的密码。
PS:SSH相关配置连接:
17.输入jps,查看当前运行的进程,如下图
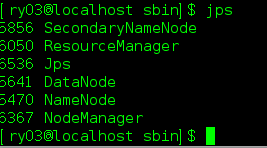
至此,Hadoop 伪分布模式已经安装完成!