CV领域常用的注意力机制模块(SE、CBAM)
一、SE模块(Squeeze-and-Excitation)
更详细内容推荐博客:最后一届ImageNet冠军模型:SENet
SENet网络的创新点:在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。

1、SE结构能说一说么?
一个SEblock的过程分为 Squeeze(压缩) 和 Excitation(激发) 两个步骤:
Squeeze(压缩) 通过在Feature Map层上执行Global Average Pooling,得到当前Feature Map的全局压缩特征量;
Excitation(激发) 通过两层全连接的bottleneck结构得到Feature Map中每个通道的权值,并将加权后的Feature Map作为下一层网络的输入。
2、SE结构的应用

3、SE的代码实现
SE模块实现的 Pytorch版:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
SE-ResNet模型的 Pytorch版:
class SEBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
二、CBAM模块(Convolutional Block Attention Module)

该注意力模块( CBAM ),可以在通道和空间维度上进行 Attention 。其包含两个子模块 Channel Attention Module(CAM) 和 Spartial Attention Module(SAM)。
1、CAM的结构是怎样的?与SE有何区别?
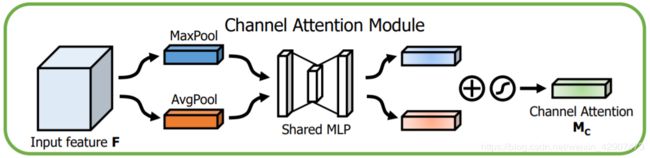
其结构如上图所示,相比SE,只是多了一个并行的Max Pooling层。那为什么加个并行的呢?结果导向,作者通过实验说明这样的效果好一些,我感觉其好一些的原因应该是多一种信息编码方式,使得获得的信息更加全面了吧,可能再加一些其他并行操作效果会更好?
2、SAM的结构

将CAM模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。下图是原文描述:

3、组合方式
通道注意力和空间注意力这两个模块可以以并行或者顺序的方式组合在一起,但是作者发现顺序组合并且将通道注意力放在前面可以取得更好的效果。而且是先CAM再SAM效果会更好。论文还将结果可视化,对比发现添加了 CBAM 后,模型会更加关注识别物体:
4、CBAM的代码实现
CBAM的 Pytorch 实现:
class Channel_Attention(nn.Module):
def __init__(self, channel, r):
super(Channel_Attention, self).__init__()
self.__avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.__max_pool = nn.AdaptiveMaxPool2d((1, 1))
self.__fc = nn.Sequential(
nn.Conv2d(channel, channel//r, 1, bias=False),
nn.ReLU(True),
nn.Conv2d(channel//r, channel, 1, bias=False),
)
self.__sigmoid = nn.Sigmoid()
def forward(self, x):
y1 = self.__avg_pool(x)
y1 = self.__fc(y1)
y2 = self.__max_pool(x)
y2 = self.__fc(y2)
y = self.__sigmoid(y1+y2)
return x * y
class Spartial_Attention(nn.Module):
def __init__(self, kernel_size):
super(Spartial_Attention, self).__init__()
assert kernel_size % 2 == 1, "kernel_size = {}".format(kernel_size)
padding = (kernel_size - 1) // 2
self.__layer = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=kernel_size, padding=padding),
nn.Sigmoid(),
)
def forward(self, x):
avg_mask = torch.mean(x, dim=1, keepdim=True)
max_mask, _ = torch.max(x, dim=1, keepdim=True)
mask = torch.cat([avg_mask, max_mask], dim=1)
mask = self.__layer(mask)
return x * mask