ELK+Kafka+Filebeat分析Nginx日志
目录
- 一、基本架构
- 二、安装Nginx
- 三、安装并配置Filebeat
- 四、配置zookeeper集群
- 五、配置Kafka集群
- 六、安装Logstash
- 七、配置ES集群:
- 八、安装Kibana
- 九、Kibana可视化界面使用
一、基本架构
| 主机名 | IP | 应用 | 角色 |
|---|---|---|---|
| nginx | 10.1.1.3 | Nginx | |
| nginx | 10.1.1.3 | Filebeat | |
| kafka1 | 10.1.1.4 | zookeeper | |
| kafka1 | 10.1.1.4 | Kafka1 | |
| kafka2 | 10.1.1.5 | Kafka2 | |
| logstash | 10.1.1.6 | Logstash | |
| es1 | 10.1.1.7 | ES1 | data/master |
| es2 | 10.1.1.8 | ES2+Kibana | data/master |
| es3 | 10.1.1.9 | ES3 | data |
整体思路:
Nginx->Filebeat->Kafka->Logstash->ES,最终展示在Kibana上
二、安装Nginx
下载Nginx并安装:
[root@nginx ~]# cd /usr/local/src/
[root@nginx src]# wget http://nginx.org/download/nginx-1.16.1.tar.gz
[root@nginx src]# tar -zxf nginx-1.16.1.tar.gz
[root@nginx src]# cd nginx-1.16.1
[root@nginx nginx-1.16.1]# yum install -y zlib-devel pcre-devel gcc-c++
[root@nginx nginx-1.16.1]# ./config --prefix=/usr/local/nginx
[root@nginx nginx-1.16.1]# make && make install
安装完成后,修改Nginx日志格式为JSON,加入以下内容即可:
[root@nginx nginx-1.16.1]# vim /usr/local/nginx/conf/nginx.conf
log_format json '{"requesttime":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log logs/access.log json;
启动Nginx:
[root@nginx nginx-1.16.1]# /usr/local/nginx/sbin/nginx
三、安装并配置Filebeat
[root@nginx ~]# rpm -ivh filebeat-7.6.0-x86_64.rpm
filebeat.inputs:
- type: log
#将enabled: false改为enabled: true
enabled: true
paths:
#此处配置好Nginx日志路径
- /usr/local/nginx/logs/access.log
#加上三行JSON相关配置
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
#------- Elasticsearch output -----------------------
#把output.elasticsearch这段注释掉,
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
#此处新增输出到Kafka的相关配置
output.kafka:
enabled: true
#Kafka集群的IP和端口
hosts: ["10.1.1.4:9092","10.1.1.5:9092"]
#这个topic要记住,后面Logstash配置要用到
topic: nginx
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
配置完成后启动即可。
四、配置zookeeper集群
下载并解压至指定目录:
[root@kafka1 ~]# cd /usr/local/src
[root@kafka1 src]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
[root@kafka1 src]# tar -zxf kafka_2.11-2.4.0.tgz -C /usr/local
[root@kafka1 src]# mv /usr/local/kafka_2.11-2.4.0 /usr/local/kafka
[root@kafka1 src]# tar -zxf apache-zookeeper-3.5.7-bin.tar.gz -C /usr/local
[root@kafka1 src]# mv /usr/local/apache-zookeeper-3.5.7-bin /usr/local/zookeeper
配置zookeeper集群:
[root@centos8 src]# cd /usr/local
[root@centos8 local]# mv zookeeper zookeeper1
[root@centos8 local]# cp -rf zookeeper1 zookeeper2
[root@centos8 local]# cp -rf zookeeper1 zookeeper3
创建zookeeper集群的数据目录和日志目录:
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/data/zookeeper1
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/data/zookeeper2
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/data/zookeeper3
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/datalog/zookeeper3
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/datalog/zookeeper2
[root@kafka1 local]# mkdir -p /data/apache/zookeeper/datalog/zookeeper1
区分到底是第几个实例呢,就要有个id文件,且名字必须是myid:
[root@kafka1 local]# echo 0 >/data/apache/zookeeper/data/zookeeper1/myid
[root@kafka1 local]# echo 1 >/data/apache/zookeeper/data/zookeeper2/myid
[root@kafka1 local]# echo 2 >/data/apache/zookeeper/data/zookeeper3/myid
修改配置文件:
zookeeper1:
[root@kafka1 conf]# cd zookeeper1/conf/
[root@kafka1 local]# cp zoo_sample.cfg zoo.cfg
[root@kafka1 local]# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/data/apache/zookeeper/data/zookeeper1/
dataLogDir=/data/apache/zookeeper/datalog/zookeeper1/
server.0=10.1.1.4:2888:2889
server.1=10.1.1.4:2890:2891
server.2=10.1.1.4:2892:2893
zookeeper2:
[root@kafka1 local]# cd /usr/local/zookeeper2/conf/
[root@kafka1 local]# cp zoo_sample.cfg zoo.cfg
[root@kafka1 local]# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2182
dataDir=/data/apache/zookeeper/data/zookeeper2/
dataLogDir=/data/apache/zookeeper/datalog/zookeeper2/
server.0=10.1.1.4:2888:2889
server.1=10.1.1.4:2890:2891
server.2=10.1.1.4:2892:2893
zookeeper3:
[root@kafka1 local]# cd /usr/local/zookeeper3/conf/
[root@kafka1 local]# cp zoo_sample.cfg zoo.cfg
[root@kafka1 local]# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2183
dataDir=/data/apache/zookeeper/data/zookeeper3/
dataLogDir=/data/apache/zookeeper/datalog/zookeeper3/
server.0=10.1.1.4:2888:2889
server.1=10.1.1.4:2890:2891
server.2=10.1.1.4:2892:2893
然后启动三个zookeeper:
[root@kafka1 local]# zookeeper1/bin/zkServer.sh start
[root@kafka1 local]# zookeeper2/bin/zkServer.sh start
[root@kafka1 local]# zookeeper3/bin/zkServer.sh start
查看集群中各节点状态:
zookeeper1为从节点
[root@kafka1 local]# zookeeper1/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper1/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
zookeeper2为主节点
[root@kafka1 local]# zookeeper2/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper2/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: leader
zookeeper3为从节点
[root@kafka1 local]# zookeeper3/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper3/bin/../conf/zoo.cfg
Client port found: 2183. Client address: localhost.
Mode: follower
五、配置Kafka集群
先在10.1.1.4上操作:
下载并解压至指定目录:
[root@kafka1 ~]# cd /usr/local/src
[root@kafka1 src]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/kafka_2.11-2.4.0.tgz
[root@kafka1 src]# tar -zxf kafka_2.11-2.4.0.tgz -C /usr/local
[root@kafka1 src]# mv /usr/local/kafka_2.11-2.4.0 /usr/local/kafka
修改配置文件:
[root@kafka1 local]# cat kafka/config/server.properties
#集群id号,每一个broker在集群中的唯一标示,要求是正数。在改变IP地址,不改变broker.id的话不会影响consumers
broker.id=1
#提供给客户端响应的端口
port=9092
#本机ip
host.name=10.1.1.4
#broker 处理消息的最大线程数,一般情况下不需要去修改
num.network.threads=3
# broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数
num.io.threads=8
# socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.send.buffer.bytes=102400
# socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.receive.buffer.bytes=102400
# socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
socket.request.max.bytes=104857600
#kafka数据的存放地址,多个地址的话用逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dirs=/usr/local/kafka/kafka-logs
# 每个topic的分区个数,会被topic创建时的指定参数覆盖
num.partitions=4
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=1
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zookeeper集群地址
zookeeper.connect=10.1.1.4:2181,10.1.1.4:2182,10.1.1.4:2183
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
在10.1.1.5上配置Kafka2节点,步骤同kafka1一样,只不过配置文件中需要修改broker.id和host.name,如下:
[root@kafka2 local]# cat kafka/config/server.properties
#集群id号,每一个broker在集群中的唯一标示,要求是正数。在改变IP地址,不改变broker.id的话不会影响consumers
broker.id=2
#提供给客户端响应的端口
port=9092
#本机ip
host.name=10.1.1.5
#broker 处理消息的最大线程数,一般情况下不需要去修改
num.network.threads=3
# broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数
num.io.threads=8
# socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.send.buffer.bytes=102400
# socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.receive.buffer.bytes=102400
# socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
socket.request.max.bytes=104857600
#kafka数据的存放地址,多个地址的话用逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dirs=/usr/local/kafka/kafka-logs
# 每个topic的分区个数,会被topic创建时的指定参数覆盖
num.partitions=4
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=1
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zookeeper集群地址
zookeeper.connect=10.1.1.4:2181,10.1.1.4:2182,10.1.1.4:2183
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
启动Kafka集群,需要在Kafka1和Kafka2上执行以下命令,无报错即成功:
[root@kafka1 local]# kafka/bin/kafka-server-start.sh kafka/config/server.properties
另外简单说一下replication-factor也就是topic的副本这个参数,当我们创建的topic有4个分区partition时并且replication-factor为1,基本上1个broker上2个分区。当一个broker宕机了,该topic就无法使用了,因为4个分区只有2个能用:
[root@kafka1 kafka]# bin/kafka-topics.sh --describe --zookeeper 10.1.1.4:2181 --topic nginx
Topic: nginx PartitionCount: 4 ReplicationFactor: 1 Configs:
Topic: nginx Partition: 0 Leader: none Replicas: 2 Isr: 2
Topic: nginx Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: nginx Partition: 2 Leader: none Replicas: 2 Isr: 2
Topic: nginx Partition: 3 Leader: 1 Replicas: 1 Isr: 1
以上面的为例,replicas对应的指的是broker.id,设想一下,如果broker.id=1这个节点挂掉,那整个集群就只有partion0和2可用,所以系统就会出现宕机或数据丢失的情况。
所以我们应该在创建topic的时候,合理配置partion和replication数量,让他们均匀分布,以免造成一个节点宕机,整个集群挂掉甚至是数据丢失的情况。这种情况下,要对上面的集群进行replications扩容,也就是增加副本数量,可以使用kafka/bin/kafka-reassign-partitions.sh这个脚本,步骤如下:
先创建一个rep-add.json文件:
[root@kafka1 config]# vim rep-add.json
{"version":1,
"partitions":[{"topic":"nginx","partition":0,"replicas":[1,2]},{"topic":"nginx","partition":1,"replicas":[1,2]},{"topic":"nginx","partition":2,"replicas":[1,2]},{"topic":"nginx","partition":3,"replicas":[1,2]}]}
注意的是,topic一定是你要扩容的那个topic,partion一定要跟实际数量一样,replicas一定是kafka集群中各个节点的broker.id。创建完成后,确保kafka集群都是启动的状态,然后执行脚本:
[root@kafka1 config]# ../bin/kafka-reassign-partitions.sh --zookeeper 10.1.1.4:2181 --reassignment-json-file rep.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"nginx","partition":2,"replicas":[2],"log_dirs":["any"]},{"topic":"nginx","partition":1,"replicas":[1],"log_dirs":["any"]},{"topic":"nginx","partition":0,"replicas":[2],"log_dirs":["any"]},{"topic":"nginx","partition":3,"replicas":[1],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
再次检查一下nginx这个topic的副本:
[root@kafka1 kafka]# bin/kafka-topics.sh --describe --zookeeper 10.1.1.4:2181 --topic nginx
Topic: nginx PartitionCount: 4 ReplicationFactor: 2 Configs:
Topic: nginx Partition: 0 Leader: 2 Replicas: 1,2 Isr: 2,1
Topic: nginx Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: nginx Partition: 2 Leader: 2 Replicas: 1,2 Isr: 2,1
Topic: nginx Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2
上面可以看到,4个partion在每个replicas上都均匀分布着,即使关掉一个Kafka节点,也不会影响整个集群的使用。
六、安装Logstash
安装JDK和Logstash
[root@logstash ~]# rpm -ivh jdk-8u241-linux-x64.rpm
[root@logstash ~]# rpm -ivh logstash-7.6.0.rpm
创建logstash配置文件:
[root@logstash ~]# cat /etc/logstash/conf.d/kafka-es.conf
input {
kafka {
codec => "json"
#此处的topics_pattern => "nginx"应该是需要和filebeat中配置的topic一致。
topics_pattern => "nginx"
#此处配置Kafka服务器集群地址
bootstrap_servers => "10.1.1.4:9092,10.1.1.5:9092"
auto_offset_reset => "latest"
}
}
filter {
# 将Nginx日志中的requesttime时间转换成北京时间,并赋值给@timestamp,确保日志的时间和@timestamp保持一致
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z +08:00"]
target => "@timestamp"
}
#引入第三个时间参数timestamp,并将上面的@timestamp时间加8小时,赋值给timestamp,防止ES把时间减去8小时后,导致两个时间相差8小时
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.utc+8*60*60)"
}
mutate {
convert => ["timestamp", "string"]
gsub => ["timestamp", "T([\S\s]*?)Z", ""]
gsub => ["timestamp", "-", "."]
}
}
output {
elasticsearch {
hosts => ["10.1.1.7:9200","10.1.1.8:9200","10.1.1.9:9200"]
index => "%{timestamp}"
}
}
启动logstash:
[root@logstash ~]# systemctl start logstash
七、配置ES集群:
ES1\ES2\ES3上操作以下内容:
新建用户elk,用于启动es集群,es官方规定,不能以root账号启动,所以我们需要创建用户和用户组,设置密码,并加入到sudoers中:
[root@es1 ~]# useradd elk
[root@es1 ~]# passwd elk
[root@es1 ~]# vim /etc/sudoers
root ALL=(ALL) ALL
elk ALL=(ALL) ALL
在三台服务器创建目录,压缩包放置目录:/opt/zip,安装软件目录:/opt/soft,es数据存放目录:/var/es/data,es日志存放目录:/var/es/logs:
[root@es1 ~]# mkdir -p /opt/soft /opt/zip
[root@es1 ~]# mkdir -p /var/es/{data,logs}
[root@es1 ~]# chown -R elk:elk /var/es/{data,logs}
安装JDK和ES:
[root@es1 ~]# rpm -ivh jdk-8u241-linux-x64.rpm
[root@es1 ~]# tar -xvf /opt/zip/elasticsearch-7.6.0-linux-x86_64.tar.gz -C /opt/soft/
[root@es1 ~]# chown -R elk:elk /opt/soft/elasticsearch-7.6.0
在三台服务器修改系统配置文件:
加大线程数限制,Elasticsearch通过将请求分解为多个阶段并将这些阶段交给不同的线程池执行程序来执行请求。Elasticsearch中的各种任务有不同的线程池执行程序。因此,Elasticsearch需要能够创建大量线程。检查的最大线程数确保Elasticsearch进程有权在正常使用下创建足够的线程,至少需要4096个线程
[root@mb ~]# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
修改虚拟内存大小:
[root@es1 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144
使修改后的配置生效:
[root@es1 ~]# sysctl -p
vm.max_map_count = 262144
ES单节点配置文件:
path.data: /var/es/data
path.logs: /var/es/logs
network.host: 10.1.1.7
http.port: 9200
discovery.type: single-node
ES集群配置如下:
ES1节点配置:
[root@es1 ~]# cat /opt/soft/elasticsearch-7.6.0/elasticsearch.yml
#集群名称
cluster.name: my-app
#节点名称
node.name: es1
#是否为管理节点
node.master: true
#是否为数据节点
node.data: true
#数据存放路径
path.data: /var/es/data
#日志存放路径
path.logs: /var/es/logs
#当前节点的IP
network.host: 10.1.1.7
#当前节点工作的端口
http.port: 9200
#通信端口
transport.tcp.port: 9300
#选择使用哪个主节点来初始化集群,并去主动发现其他节点,必须和node.name一致
cluster.initial_master_nodes: ["es1"]
#集群初始化时自动发现的IP和通信端口
discovery.zen.ping.unicast.hosts: ["10.1.1.7:9300","10.1.1.8:9300", "10.1.1.9:9300"]
#该属性定义的是为了形成一个集群,有主节点资格(node.master)并互相连接的节点的最小数目为(N/2)+1,以防止集群脑裂出现多个master节点
discovery.zen.minimum_master_nodes: 2
ES2节点配置:
[root@es2 ~]# cat /opt/soft/elasticsearch-7.6.0/elasticsearch.yml
cluster.name: my-app
node.name: es2
node.master: true
node.data: true
path.data: /var/es/data
path.logs: /var/es/logs
network.host: 10.1.1.8
http.port: 9200
transport.tcp.port: 9300
cluster.initial_master_nodes: ["es1"]
discovery.zen.ping.unicast.hosts: ["10.1.1.7:9300","10.1.1.8:9300", "10.1.1.9:9300"]
discovery.zen.minimum_master_nodes: 2
ES3节点配置:
[root@es3 ~]# cat /opt/soft/elasticsearch-7.6.0/elasticsearch.yml
cluster.name: my-app
node.name: es3
node.master: false
node.data: true
path.data: /var/es/data
path.logs: /var/es/logs
network.host: 10.1.1.9
http.port: 9200
transport.tcp.port: 9300
cluster.initial_master_nodes: ["es1"]
discovery.zen.ping.unicast.hosts: ["10.1.1.7:9300","10.1.1.8:9300", "10.1.1.9:9300"]
discovery.zen.minimum_master_nodes: 2
在三个ES节点分别启动ES:
[root@es1 ~]# su - elk
[elk@es1 ~]$ cd /opt/soft/elasticsearch-7.6.0/
[elk@es1 elasticsearch-7.6.0]$ bin/elasticsearch
#启动后检查没问题的话,可以进行后台启动:
[elk@es3 elasticsearch-7.6.0]$ bin/elasticsearch -d
启动完成后,在浏览器输入http://10.1.1.7:9200/_cat/nodes?v,可以看到:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.1.1.7 14 94 0 0.06 0.03 0.05 dilm * es1
10.1.1.8 12 97 3 0.14 0.09 0.11 dilm - es2
10.1.1.9 12 93 0 0.32 0.08 0.07 dil - es3
至此,ES集群搭建完了。
以上ES集群搭建过程是每台服务器都搭建一个节点,如果只有一个服务器,需要搭建多个节点的话,搭建过程可参考zookeeper、mysql或redis的单机多实例部署。
八、安装Kibana
在ES2上安装JDK和Kibana:
[root@es2 ~]# rpm -ivh jdk-8u241-linux-x64.rpm
[root@es2 ~]# tar -zxf /opt/zip/kibana-7.6.0-linux-x86_64.tar.gz -C /opt/soft/
修改配置:
[root@es2 soft]$ cat kibana-7.6.0-linux-x86_64/config/kibana.yml |grep -v "#"
server.port: 5601
server.host: "10.1.1.8"
server.name: "es2"
elasticsearch.hosts: ["http://10.1.1.7:9200","http://10.1.1.8:9200","http://10.1.1.9:9200"]
i18n.locale: "zh-CN"
启动Kibana:
[root@es2 soft]$ cd /opt/soft/kibana-7.6.0-linux-x86_64/
[root@es2 kibana-7.6.0-linux-x86_64]$ bin/kibana
#启动后无报错的话,可以后台启动
#[root@es2 kibana-7.6.0-linux-x86_64]$ nohup bin/kibana &
九、Kibana可视化界面使用
Kibana启动完成后,可以访问http://10.1.1.8:5601:
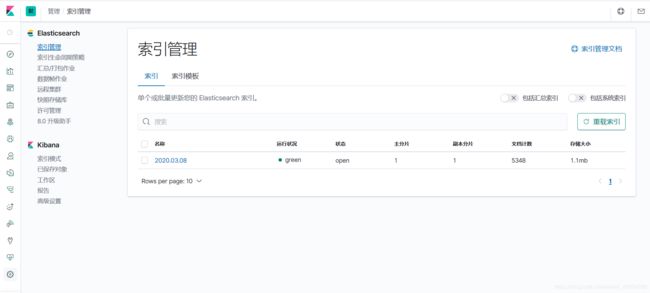
 在管理–索引管理中可以看到,根据logstash中配置好的索引命名格式而生成的索引:
在管理–索引管理中可以看到,根据logstash中配置好的索引命名格式而生成的索引:
 随后在管理–高级设置中把时区调整为Asia/Shanghai
随后在管理–高级设置中把时区调整为Asia/Shanghai
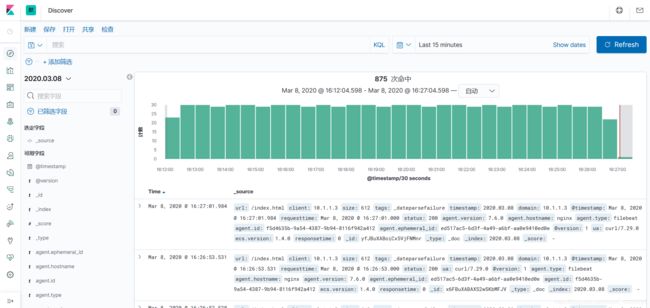
我们可以在索引模式中创建新的索引模式,并在Discovery中看到Nginx日志记录: