[DirectX12学习笔记] 计算着色器
- 注意!本文是在下几年前入门期间所写(young and naive),其中许多表述可能不正确,为防止误导,请各位读者仔细鉴别。
用计算着色器实现高斯模糊
计算着色器简介
计算着色器在渲染管线中的位置可以这么理解
![[DirectX12学习笔记] 计算着色器_第1张图片](http://img.e-com-net.com/image/info8/9959daacdcb44409a02fae38e9d3ba2c.jpg)
GPU的并行执行能力非常强,非常适合安排多线程任务,英伟达的硬件现在是一个warp包含32个线程,ATI的则是一个wavefront包含64个线程,所以为了均匀分配任务,我们写程序的时候开的线程数最好是32和64的倍数,也就是64的倍数。
在compute shader里线程会分成很多个组,每个thread group包含很多个thread,而且thread group和thread都有三个维度
thread group的数量通过Dispatch来规定
void ID3D12GraphicsCommandList::Dispatch(
UINT ThreadGroupCountX,
UINT ThreadGroupCountY,
UINT ThreadGroupCountZ);
这个dispatch其实就是执行计算着色器的命令,类似于draw call,输入参数是三个轴的group的数量,然后每个group里包含了多少个thread,则是在Compute Shader前的方括号里标出:
// The number of threads in the thread group. The threads in a group can
// be arranged in a 1D, 2D, or 3D grid layout.
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID)
// Thread ID
{
// Sum the xyth texels and store the result in the xyth texel of
// gOutput.
gOutput[dispatchThreadID.xy] = gInputA[dispatchThreadID.xy] + gInputB[dispatchThreadID.xy];
}
上面的代码则是表示每个group里有16*16个thread。
可以看到代码里用了SV_DispatchThreadID来获取当前线程的id,其实线程id有4种,如下
- SV_GroupID可以获取group id,是一个标识group的三维向量
- SV_GroupThreadID可以获取组内的id,即相对与组的开头的id偏移,也是个三维的
- SV_DispatchThreadID可以获取总的id,总的id是这么计算的:
dispatchThreadID.xyz =
groupID.xyz * ThreadGroupSize.xyz + groupThreadID.xyz
- SV_GroupIndex系统值是一个线性版本的DispatchThreadID,是这样计算出来的:
groupIndex =
groupThreadIDzThreadGroupSize.xThreadGroupSize.y + groupThreadID.y*ThreadGroupSize.x + groupThreadID.x;
有的时候任务的数量不是刚好是线程数的整数倍,比如256个线程,然后输入的有200个数据,那么会多出来一些线程,数组会越界,不过不用担心,因为数组越界的读默认会读出0,而越界的写默认是空操作,当然有的时候还是会出问题,比如下面的高斯模糊的例子,所以要注意一下。
然后,要用计算着色器,创建PSO的时候也不再是填D3D12_GRAPHICS_PIPELINE_STATE_DESC了,而是填一个D3D12_COMPUTE_PIPELINE_STATE_DESC,后者要填的参数要少很多,编译CS和创建PSO的方法如下:
mShaders[“wavesUpdateCS”] = d3dUtil::CompileShader(L"Shaders\WaveSim.hlsl", nullptr, "UpdateWavesCS", "cs_5_0");
···
D3D12_COMPUTE_PIPELINE_STATE_DESC wavesUpdatePSO = {};
wavesUpdatePSO.pRootSignature = mWavesRootSignature.Get();
wavesUpdatePSO.CS =
{
reinterpret_cast<BYTE*>(mShaders["wavesUpdateCS"]->GetBufferPointer()), mShaders[“wavesUpdateCS”]->GetBufferSize()
};
wavesUpdatePSO.Flags = D3D12_PIPELINE_STATE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateComputePipelineState(
&wavesUpdatePSO,
IID_PPV_ARGS(&mPSOs[“wavesUpdate”])));
shader输入和输出
我们要用compute shader,那么自然就涉及到一个输入和输出的问题,我们要把数据从cpu上传到gpu让gpu来算,然后算完之后再从gpu读回cpu(有的时候不用,比如算完后当作输出到屏幕的资源或者拿去做别的处理之类的)。以下提几种输入或者输出的方法,以及要注意的点。
输入纹理
创建一个输入纹理我们以前已经做过很多次了,绑srv就行。
然而这里和以前创建贴图的SRV不同的是,要用CreateCommittedResource创建成GPU资源(因为以前读贴图的时候用了DirectX::CreateDDSTextureFromFile12,这个方法包含了gpu资源的创建,而这里我们是创建一个空的,不再是读贴图了,所以要手动创建一下gpu资源),然后创建srv的时候把gpu资源传入第一个参数。
输出纹理
要绑UAV,绑UAV的方法类似于绑SRV,这里不再列代码。此外,必须用CreateCommittedResouce创建GPU资源,而且申请resource的时候必须要带D3D12_RESOURCE_ALLOW_UNORDERED_ACCESS这个flag,只有srv的resource在申请的时候可以不带flag,因为默认就是srv的resource,其他的如render target等都要一个ALLOW的flag。
然后shader里要声明一个输出的纹理,应该这么声明:
Texture2D gInput : register(t0);
RWTexture2D<float4> gOutput : register(u0);
可以看到第二个是存在u0里的而不是t0,而且是RWTexture2D,表示可以读写,这是个模板类,float4声明了输出的类型,写的时候直接用赋值的语法写就行。
Sample Level
Compute Shader里采样不能再用Sample函数了,而是要用Sample Level,和Sample不同的是,首先采样坐标归一化了,传入的uv必须是0~1之间的浮点数,第二是多了第三个参数,也就是mipmap level,是个浮点数,0表示最高级的,1表示最高级下面一级的mipmap,浮点数则用来在不同级别mipmap之间插值。
Structured Buffer Resources
绑定到shader的t和u寄存器的不一定是纹理,可以像下面这样自己定义输入输出的类型
struct Data
{
float3 v1;
float2 v2;
};
StructuredBuffer<Data> gInputA : register(t0);
StructuredBuffer<Data> gInputB : register(t1);
RWStructuredBuffer<Data> gOutput : register(u0);
对应的SRV和UAV可以和之前创建vb和ib一样,用CreateDefaultBuffer或者CreateUploadBuffer来做,但是要注意的一点是,uav的D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS这个flag必须要指定一下,而且指定这个flag是个好习惯。
然后可以不用table而用root descriptor来接收参数(这种做法只适用于用srv和uav来缓存resource而不是texture),然后传入的时候传入mInputBuffer->GetGPUVirtualAddress()。
拷贝CS输出到内存
如果要建一个read back buffer,用CreateCommittedResource来创建一个GPU资源,然后创建的时候要指定堆的类型为D3D12_HEAP_TYPE_READBACK,这个gpu资源就可以用SetGraphicsRootUnorderedAccessView来绑定给uav。
注意这里的UAV是root parameter而不是buffer的GPU地址,UAV是在创建RootParameter的时候就创建了,而这个SetGraphicsRootUnorderedAccessView只是改变root parameter这个UAV里的内容。
此外还要注意,heap有cpu地址和gpu地址,cpu的用来创建(CreateShaderResourceView),GPU的用来传入(SetGraphicsRootDescriptorTable),创建的时候用heap的GetCPUDescriptorHandleForHeapStart获取heap的cpu首地址再offset取得srv或者uav的cpu地址,传入的时候则是用heap的GetGPUDescriptorHandleForHeapStart来获得heap的gpu首地址再offset到srv或者uav的gpu地址。
然后用mCommandList->CopyResource(mReadBackBuffer.Get(), mOutputBuffer.Get());来把输出数据读入到read back buffer里,然后用mReadBackBuffer->Map来把资源map到cpu的一个buffer里,在cpu上读取就行。
示例的代码如下
void VecAddCSApp::BuildBuffers()
{
// Generate some data.
std::vector<Data> dataA(NumDataElements);
std::vector<Data> dataB(NumDataElements);
for(int i = 0; i < NumDataElements; ++i)
{
dataA[i].v1 = XMFLOAT3(i, i, i);
dataA[i].v2 = XMFLOAT2(i, 0);
dataB[i].v1 = XMFLOAT3(-i, i, 0.0f);
dataB[i].v2 = XMFLOAT2(0, -i);
}
UINT64 byteSize = dataA.size()*sizeof(Data);
// Create some buffers to be used as SRVs.
mInputBufferA = d3dUtil::CreateDefaultBuffer(
md3dDevice.Get(),
mCommandList.Get(),
dataA.data(),
byteSize,
mInputUploadBufferA);
mInputBufferB = d3dUtil::CreateDefaultBuffer(
md3dDevice.Get(),
mCommandList.Get(),
dataB.data(),
byteSize,
mInputUploadBufferB);
// Create the buffer that will be a UAV.
ThrowIfFailed(md3dDevice->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS),
D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
nullptr,
IID_PPV_ARGS(&mOutputBuffer)));
ThrowIfFailed(md3dDevice->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_READBACK),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&mReadBackBuffer)));
}
void VecAddCSApp::DoComputeWork()
{
// Reuse the memory associated with command recording.
// We can only reset when the associated command lists have finished execution on the GPU.
ThrowIfFailed(mDirectCmdListAlloc->Reset());
// A command list can be reset after it has been added to the command queue via ExecuteCommandList.
// Reusing the command list reuses memory.
ThrowIfFailed(mCommandList->Reset(mDirectCmdListAlloc.Get(), mPSOs["vecAdd"].Get()));
mCommandList->SetComputeRootSignature(mRootSignature.Get());
mCommandList->SetComputeRootShaderResourceView(0, mInputBufferA->GetGPUVirtualAddress());
mCommandList->SetComputeRootShaderResourceView(1, mInputBufferB->GetGPUVirtualAddress());
mCommandList->SetComputeRootUnorderedAccessView(2, mOutputBuffer->GetGPUVirtualAddress());
mCommandList->Dispatch(1, 1, 1);
// Schedule to copy the data to the default buffer to the readback buffer.
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mOutputBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_SOURCE));
mCommandList->CopyResource(mReadBackBuffer.Get(), mOutputBuffer.Get());
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mOutputBuffer.Get(),
D3D12_RESOURCE_STATE_COPY_SOURCE, D3D12_RESOURCE_STATE_COMMON));
// Done recording commands.
ThrowIfFailed(mCommandList->Close());
// Add the command list to the queue for execution.
ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
// Wait for the work to finish.
FlushCommandQueue();
// Map the data so we can read it on CPU.
Data* mappedData = nullptr;
ThrowIfFailed(mReadBackBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mappedData)));
std::ofstream fout("results.txt");
for(int i = 0; i < NumDataElements; ++i)
{
fout << "(" << mappedData[i].v1.x << ", " << mappedData[i].v1.y << ", " << mappedData[i].v1.z <<
", " << mappedData[i].v2.x << ", " << mappedData[i].v2.y << ")" << std::endl;
}
mReadBackBuffer->Unmap(0, nullptr);
}
Append Buffer和Consume Buffer
上面说的方法读入和输出,我们都要考虑怎么根据标号分配任务,但是有的时候我们不想根据标号来分配任务,比如算一个粒子系统的运动和物理的时候,我们希望随便多少个粒子,都能取出来就算,算完了就放到输出里,这种时候就可以用Consume Buffer和Append Buffer,取的时候就gInput.Consume(),输出的时候就gOutput.Append(输出值);,一个例子如下
struct Particle
{
float3 Position;
float3 Velocity;
float3 Acceleration;
};
float TimeStep = 1.0f / 60.0f;
ConsumeStructuredBuffer<Particle> gInput;
AppendStructuredBuffer<Particle> gOutput;
[numthreads(16, 16, 1)]
void CS()
{
// Consume a data element from the input buffer.
Particle p = gInput.Consume();
p.Velocity += p.Acceleration*TimeStep;
p.Position += p.Velocity*TimeStep;
// Append normalized vector to output buffer.
gOutput.Append( p );
}
共享内存
每个组可以有一块共享的内存,这块内存里的资源访问起来是很快的,最多能有32k的共享内存,如果一个组占有太多的内存,那么别的组就会少,这样的话效率就会降低,所以不要使用太多的共享内存。
共享内存可以这样声明:
groupshared float4 gCache[256];
既然有了共享内存,那么也就有了同步的问题,有的时候别的线程还没写完这一块内存,一个线程就要去读的话,就会出问题,所以有的时候需要等所有线程都运行到某个地方了才继续运行,这就要用到同步的命令了:
GroupMemoryBarrierWithGroupSync();
渲染到贴图
如果想要渲染到贴图的话,创建GPU资源的时候要带上一个flag,D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET,然后再用mCommandList->OMSetRenderTargets设置rt就可以了。
高斯模糊Demo
这个demo里我们用GPU来算高斯模糊,首先gpu渲染输出到back buffer上,然后把back buffer作为输入输入到cs,然后cs输出模糊后的结果,再输出到屏幕上。
首先介绍高斯模糊原理,
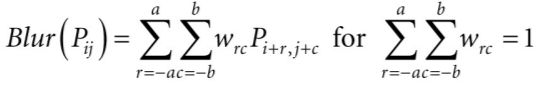
如果是高斯模糊的话,这里的权重就是正态分布,也就是 w = e x p ( − x 2 2 σ 2 ) w=exp(-\frac{x^{2}}{2\sigma^{2}}) w=exp(−2σ2x2),算完之后再归一就行。
然后二维的没必要用二维的高斯分布,而是在横向和纵向迭代一次就行,也就是先横向高斯模糊,再纵向高斯模糊,这样的话可以省计算量,比如9*9的高斯算子要采样81次,而横竖分开的话只要9+9=18次就行了。
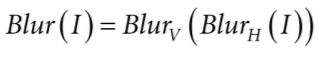
接下来介绍demo代码的一些关键步骤
首先CS要有单独的Root Signature
void BlurApp::BuildPostProcessRootSignature()
{
CD3DX12_DESCRIPTOR_RANGE srvTable;
srvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0);
CD3DX12_DESCRIPTOR_RANGE uavTable;
uavTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0);
// Root parameter can be a table, root descriptor or root constants.
CD3DX12_ROOT_PARAMETER slotRootParameter[3];
// Perfomance TIP: Order from most frequent to least frequent.
slotRootParameter[0].InitAsConstants(12, 0);
slotRootParameter[1].InitAsDescriptorTable(1, &srvTable);
slotRootParameter[2].InitAsDescriptorTable(1, &uavTable);
// A root signature is an array of root parameters.
CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(3, slotRootParameter,
0, nullptr,
D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
// create a root signature with a single slot which points to a descriptor range consisting of a single constant buffer
ComPtr<ID3DBlob> serializedRootSig = nullptr;
ComPtr<ID3DBlob> errorBlob = nullptr;
HRESULT hr = D3D12SerializeRootSignature(&rootSigDesc, D3D_ROOT_SIGNATURE_VERSION_1,
serializedRootSig.GetAddressOf(), errorBlob.GetAddressOf());
if(errorBlob != nullptr)
{
::OutputDebugStringA((char*)errorBlob->GetBufferPointer());
}
ThrowIfFailed(hr);
ThrowIfFailed(md3dDevice->CreateRootSignature(
0,
serializedRootSig->GetBufferPointer(),
serializedRootSig->GetBufferSize(),
IID_PPV_ARGS(mPostProcessRootSignature.GetAddressOf())));
}
然后创建descriptor,然后每次OnResize要重新创建resource和descriptor。
//
// Fill out the heap with the descriptors to the BlurFilter resources.
//
mBlurFilter->BuildDescriptors(
CD3DX12_CPU_DESCRIPTOR_HANDLE(mCbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), 3, mCbvSrvUavDescriptorSize),
CD3DX12_GPU_DESCRIPTOR_HANDLE(mCbvSrvUavDescriptorHeap->GetGPUDescriptorHandleForHeapStart(), 3, mCbvSrvUavDescriptorSize),
mCbvSrvUavDescriptorSize);
···
void BlurFilter::BuildDescriptors(CD3DX12_CPU_DESCRIPTOR_HANDLE hCpuDescriptor,
CD3DX12_GPU_DESCRIPTOR_HANDLE hGpuDescriptor,
UINT descriptorSize)
{
// Save references to the descriptors.
mBlur0CpuSrv = hCpuDescriptor;
mBlur0CpuUav = hCpuDescriptor.Offset(1, descriptorSize);
mBlur1CpuSrv = hCpuDescriptor.Offset(1, descriptorSize);
mBlur1CpuUav = hCpuDescriptor.Offset(1, descriptorSize);
mBlur0GpuSrv = hGpuDescriptor;
mBlur0GpuUav = hGpuDescriptor.Offset(1, descriptorSize);
mBlur1GpuSrv = hGpuDescriptor.Offset(1, descriptorSize);
mBlur1GpuUav = hGpuDescriptor.Offset(1, descriptorSize);
BuildDescriptors();
}
void BlurFilter::BuildDescriptors()
{
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};
srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
srvDesc.Format = mFormat;
srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D;
srvDesc.Texture2D.MostDetailedMip = 0;
srvDesc.Texture2D.MipLevels = 1;
D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};
uavDesc.Format = mFormat;
uavDesc.ViewDimension = D3D12_UAV_DIMENSION_TEXTURE2D;
uavDesc.Texture2D.MipSlice = 0;
md3dDevice->CreateShaderResourceView(mBlurMap0.Get(), &srvDesc, mBlur0CpuSrv);
md3dDevice->CreateUnorderedAccessView(mBlurMap0.Get(), nullptr, &uavDesc, mBlur0CpuUav);
md3dDevice->CreateShaderResourceView(mBlurMap1.Get(), &srvDesc, mBlur1CpuSrv);
md3dDevice->CreateUnorderedAccessView(mBlurMap1.Get(), nullptr, &uavDesc, mBlur1CpuUav);
}
编译Shader
mShaders["horzBlurCS"] = d3dUtil::CompileShader(L"Shaders\\Blur.hlsl", nullptr, "HorzBlurCS", "cs_5_0");
mShaders["vertBlurCS"] = d3dUtil::CompileShader(L"Shaders\\Blur.hlsl", nullptr, "VertBlurCS", "cs_5_0");
创建计算着色器对应的PSO
//
// PSO for horizontal blur
//
D3D12_COMPUTE_PIPELINE_STATE_DESC horzBlurPSO = {};
horzBlurPSO.pRootSignature = mPostProcessRootSignature.Get();
horzBlurPSO.CS =
{
reinterpret_cast<BYTE*>(mShaders["horzBlurCS"]->GetBufferPointer()),
mShaders["horzBlurCS"]->GetBufferSize()
};
horzBlurPSO.Flags = D3D12_PIPELINE_STATE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateComputePipelineState(&horzBlurPSO, IID_PPV_ARGS(&mPSOs["horzBlur"])));
//
// PSO for vertical blur
//
D3D12_COMPUTE_PIPELINE_STATE_DESC vertBlurPSO = {};
vertBlurPSO.pRootSignature = mPostProcessRootSignature.Get();
vertBlurPSO.CS =
{
reinterpret_cast<BYTE*>(mShaders["vertBlurCS"]->GetBufferPointer()),
mShaders["vertBlurCS"]->GetBufferSize()
};
vertBlurPSO.Flags = D3D12_PIPELINE_STATE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateComputePipelineState(&vertBlurPSO, IID_PPV_ARGS(&mPSOs["vertBlur"])));
Draw部分
DrawRenderItems(mCommandList.Get(), mRitemLayer[(int)RenderLayer::Opaque]);
mCommandList->SetPipelineState(mPSOs["alphaTested"].Get());
DrawRenderItems(mCommandList.Get(), mRitemLayer[(int)RenderLayer::AlphaTested]);
mCommandList->SetPipelineState(mPSOs["transparent"].Get());
DrawRenderItems(mCommandList.Get(), mRitemLayer[(int)RenderLayer::Transparent]);
mBlurFilter->Execute(mCommandList.Get(), mPostProcessRootSignature.Get(),
mPSOs["horzBlur"].Get(), mPSOs["vertBlur"].Get(), CurrentBackBuffer(), 4);
···
void BlurFilter::Execute(ID3D12GraphicsCommandList* cmdList,
ID3D12RootSignature* rootSig,
ID3D12PipelineState* horzBlurPSO,
ID3D12PipelineState* vertBlurPSO,
ID3D12Resource* input,
int blurCount)
{
auto weights = CalcGaussWeights(2.5f);
int blurRadius = (int)weights.size() / 2;
cmdList->SetComputeRootSignature(rootSig);
cmdList->SetComputeRoot32BitConstants(0, 1, &blurRadius, 0);
cmdList->SetComputeRoot32BitConstants(0, (UINT)weights.size(), weights.data(), 1);
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(input,
D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_COPY_SOURCE));
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
// Copy the input (back-buffer in this example) to BlurMap0.
cmdList->CopyResource(mBlurMap0.Get(), input);
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_GENERIC_READ));
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
for(int i = 0; i < blurCount; ++i)
{
//
// Horizontal Blur pass.
//
cmdList->SetPipelineState(horzBlurPSO);
cmdList->SetComputeRootDescriptorTable(1, mBlur0GpuSrv);
cmdList->SetComputeRootDescriptorTable(2, mBlur1GpuUav);
// How many groups do we need to dispatch to cover a row of pixels, where each
// group covers 256 pixels (the 256 is defined in the ComputeShader).
UINT numGroupsX = (UINT)ceilf(mWidth / 256.0f);
cmdList->Dispatch(numGroupsX, mHeight, 1);
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_GENERIC_READ));
//
// Vertical Blur pass.
//
cmdList->SetPipelineState(vertBlurPSO);
cmdList->SetComputeRootDescriptorTable(1, mBlur1GpuSrv);
cmdList->SetComputeRootDescriptorTable(2, mBlur0GpuUav);
// How many groups do we need to dispatch to cover a column of pixels, where each
// group covers 256 pixels (the 256 is defined in the ComputeShader).
UINT numGroupsY = (UINT)ceilf(mHeight / 256.0f);
cmdList->Dispatch(mWidth, numGroupsY, 1);
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_GENERIC_READ));
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
}
}
然后是完整的shader部分,其中纵向和横向原理完全一样,只是参数的横纵换了一下,注意这里有一些稍微tricky一点的操作,下面一个个讲解:
1.首先如果去贴图上采样的话,一个点会被采样很多次(每个相邻的点都要取这个点的值作为模糊的输入参数),这样很浪费,因为采样会慢一些,如果把图事先读到共享buffer里来就省很多时间,因为共享buffer读的很快。
2.假如R是模糊半径,N是一个组的线程数,那么其实buffer的大小需要N+2R,要读出界几个,因为模糊要用,所以让前R个和后R个线程每个读2个像素,其他线程每个正常读1个像素。
3.然后会有一些边界取值问题,我们需要clamp三种情况,第一种是dispatchThreadID.x<0(假如现在是横向模糊),第二种是dispatchThreadID.x>gInput.Length.x-1,第三种是因为我们这里安排了256个线程,但是假如输入图像的宽度不是256的倍数,那么会有一些线程超出边界,超出数组边界的默认读是读出0,写是空操作,但是我们这里因为要做模糊操作,会超出一点点边界,我们不希望这个边界被写入0,而是希望被clamp成边界值,所以这种情况也要clamp一下。下面把clamp的代码单独列出来一下:
// Clamp out of bound samples that occur at left image borders.
int x = max(dispatchThreadID.x - gBlurRadius, 0);
gCache[groupThreadID.x] = gInput[int2(x, dispatchThreadID.y)];
// Clamp out of bound samples that occur at right image borders.
int x = min(dispatchThreadID.x + gBlurRadius, gInput.Length.x-1);
gCache[groupThreadID.x+2*gBlurRadius] = gInput[int2(x, dispatchThreadID.y)];
// Clamp out of bound samples that occur at image
borders.gCache[groupThreadID.x+gBlurRadius] =
gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
需要注意的就以上这些,整个compute shader的代码如下
cbuffer cbSettings : register(b0)
{
// We cannot have an array entry in a constant buffer that gets mapped onto
// root constants, so list each element.
int gBlurRadius;
// Support up to 11 blur weights.
float w0;
float w1;
float w2;
float w3;
float w4;
float w5;
float w6;
float w7;
float w8;
float w9;
float w10;
};
static const int gMaxBlurRadius = 5;
Texture2D gInput : register(t0);
RWTexture2D<float4> gOutput : register(u0);
#define N 256
#define CacheSize (N + 2*gMaxBlurRadius)
groupshared float4 gCache[CacheSize];
[numthreads(N, 1, 1)]
void HorzBlurCS(int3 groupThreadID : SV_GroupThreadID,
int3 dispatchThreadID : SV_DispatchThreadID)
{
// Put in an array for each indexing.
float weights[11] = { w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10 };
//
// Fill local thread storage to reduce bandwidth. To blur
// N pixels, we will need to load N + 2*BlurRadius pixels
// due to the blur radius.
//
// This thread group runs N threads. To get the extra 2*BlurRadius pixels,
// have 2*BlurRadius threads sample an extra pixel.
if(groupThreadID.x < gBlurRadius)
{
// Clamp out of bound samples that occur at image borders.
int x = max(dispatchThreadID.x - gBlurRadius, 0);
gCache[groupThreadID.x] = gInput[int2(x, dispatchThreadID.y)];
}
if(groupThreadID.x >= N-gBlurRadius)
{
// Clamp out of bound samples that occur at image borders.
int x = min(dispatchThreadID.x + gBlurRadius, gInput.Length.x-1);
gCache[groupThreadID.x+2*gBlurRadius] = gInput[int2(x, dispatchThreadID.y)];
}
// Clamp out of bound samples that occur at image borders.
gCache[groupThreadID.x+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
// Wait for all threads to finish.
GroupMemoryBarrierWithGroupSync();
//
// Now blur each pixel.
//
float4 blurColor = float4(0, 0, 0, 0);
for(int i = -gBlurRadius; i <= gBlurRadius; ++i)
{
int k = groupThreadID.x + gBlurRadius + i;
blurColor += weights[i+gBlurRadius]*gCache[k];
}
gOutput[dispatchThreadID.xy] = blurColor;
}
[numthreads(1, N, 1)]
void VertBlurCS(int3 groupThreadID : SV_GroupThreadID,
int3 dispatchThreadID : SV_DispatchThreadID)
{
// Put in an array for each indexing.
float weights[11] = { w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10 };
//
// Fill local thread storage to reduce bandwidth. To blur
// N pixels, we will need to load N + 2*BlurRadius pixels
// due to the blur radius.
//
// This thread group runs N threads. To get the extra 2*BlurRadius pixels,
// have 2*BlurRadius threads sample an extra pixel.
if(groupThreadID.y < gBlurRadius)
{
// Clamp out of bound samples that occur at image borders.
int y = max(dispatchThreadID.y - gBlurRadius, 0);
gCache[groupThreadID.y] = gInput[int2(dispatchThreadID.x, y)];
}
if(groupThreadID.y >= N-gBlurRadius)
{
// Clamp out of bound samples that occur at image borders.
int y = min(dispatchThreadID.y + gBlurRadius, gInput.Length.y-1);
gCache[groupThreadID.y+2*gBlurRadius] = gInput[int2(dispatchThreadID.x, y)];
}
// Clamp out of bound samples that occur at image borders.
gCache[groupThreadID.y+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
// Wait for all threads to finish.
GroupMemoryBarrierWithGroupSync();
//
// Now blur each pixel.
//
float4 blurColor = float4(0, 0, 0, 0);
for(int i = -gBlurRadius; i <= gBlurRadius; ++i)
{
int k = groupThreadID.y + gBlurRadius + i;
blurColor += weights[i+gBlurRadius]*gCache[k];
}
gOutput[dispatchThreadID.xy] = blurColor;
}
最终得到的结果如图所示
![[DirectX12学习笔记] 计算着色器_第2张图片](http://img.e-com-net.com/image/info8/b1af44c5311d4c9d9cdd1ca6f4c3a871.jpg)