初步认识GBDT
个人理解:GBDT(Gradient Boosting Decision Tree),梯度提升决策树、再读一遍:梯度,提升,决策树。
所以理解GBDT,拆开理解就行了。
提升:boosting族算法,就是在迭代的每一部构建一个弱学习器,加到(弥补)已有模型的不足,使得新模型能够更好的拟合数据。
梯度:作为boosting族算法的分支,我们在求取新的第 t 个模型的过程中,需要求得当前的损失函数(L(y真,y预t-1)对当前模型F(x)的梯度,所以也成为基于梯度的提升方法。(注意,这篇文章的推导用到了泰勒公式的二阶展开,一些方法中是求得一阶导数,所以称之为梯度。作者对于这个了解的不深,还需要看别的资料才行。这里暂时这么认为把。)
决策树:我们知道可以用梯度提升方法,只是没有选定基学习器,由决策树的优点,我们可以一般用决策树(CART决策树)作为基学习器,而对于决策树有时会过拟合的缺点,通过弱化单棵决策树,再用提升方法结合策略,通过对梯度提升方法进行调参,是可以避免的。
于是,我们得到了,梯度、提升、决策树方法即GBDT。
学习作业部落 Cmd Markdown 编辑阅读器的笔记,帮助理解。
在GBDT的推导中参考机器学习-一文理解GBDT的原理一文。
一、前言
再次推荐看作业部落 Cmd Markdown 编辑阅读器这篇文章,讲的很好。下面很多句子都是摘抄此文的。
另外,并不推荐孤立的学习GBDT,网上一些只是单讲GBDT的,显得没头没尾的,所以还是从集成学习慢慢往下深入比较好。
二、综述:从ensemble learning到Boosting族到Gradient boosting 再到GBDT
集成学习==>提升方法族==>梯度提升方法==>以决策树作为基学习器的梯度提升方法
2.1集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。如何产生“好而不同”的个体学习器,是集成学习研究的核心。
根据个体学习器的生成方式,可以将集成学习方法大致分为两大类:
- 1、个体学习器间存在强依赖关系、必须串行生成的序列化方法。
比如boosting族算法,代表性的有adaboost算法,GBDT。 - 2、个体学习器之间不存在强依赖关系、可同时生成的并行化方法。
比如bagging和“随机森林”。
对于adaboost,bagging和随机森林可以参考集成学习方法1
2.2 Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。boosting方法通过分步迭代(stage-wise)的方式来构建模型,在迭代的每一步构建的弱学习器都是为了弥补已有模型的不足。(个体学习器之间存在强依赖关系。)
boosting族算法的著名代表:AdaBoost。
AdaBoost算法通过给已有模型预测错误的样本更高的权重,使得先前的学习器做错的训练样本在后续受到更多的关注的方式来弥补已有模型的不足。
2.3、相比于AdaBoost,梯度提升方法的优点
虽然同属于Boosting族,但是梯度提升方法的优点比较多。
- 1、与AdaBoost算法不同,梯度提升方法在迭代的每一步构建一个能够沿着梯度最陡的方向降低损失(steepest-descent)的学习器来弥补已有模型的不足。
- 2、经典的AdaBoost算法只能处理采用指数损失函数的二分类学习任务(参考集成学习方法1),而梯度提升方法通过设置不同的可微损失函数可以处理各类学习任务(多分类、回归、Ranking等),应用范围大大扩展。
- 3、AdaBoost算法对异常点(outlier)比较敏感,而梯度提升算法通过引入bagging思想、加入正则项等方法能够有效地抵御训练数据中的噪音,具有更好的健壮性。
2.4、GBDT==>选择决策树作为基学习器的梯度提升方法
基于梯度提升算法的学习器叫做GBM(Gradient Boosting Machine)
理论上,GBM可以选择各种不同的学习算法作为基学习器。现实中,用得最多的基学习器是决策树。
2.4.1为什么梯度提升方法倾向于选择决策树(通常是CART树)作为基学习器呢?
这与决策树算法自身的优点有很大的关系:
1、决策树可以认为是if-then规则的集合,易于理解,可解释性强,预测速度快;
2、决策树算法相比于其他的算法需要更少的特征工程,比如可以不用做特征标准化,可以很好的处理字段缺失的数据,也可以不用关心特征间是否相互依赖等
3、决策树能够自动组合多个特征,它可以毫无压力地处理特征间的交互关系并且是非参数化的,因此你不必担心异常值或者数据是否线性可分。
举个例子,西瓜a(乌黑色、纹路清晰)可能是好瓜,西瓜b(青绿色,纹路清晰)的也可能是好瓜。决策树一样可以处理。
2.4.2决策树有优点,自然也有缺点,不过,可以通过梯度提升方法解决这个缺点。
单独使用决策树算法时,有容易过拟合缺点。怎么解决呢?
- 通过各种方法,抑制决策树的复杂性,降低单棵决策树的拟合能力
- 通过梯度提升的方法集成多个决策树,则预测效果上来的同时,也能够很好的解决过拟合的问题。
(这一点具有bagging的思想,降低单个学习器的拟合能力,提高方法的泛化能力。)
由此可见,梯度提升方法和决策树学习算法可以互相取长补短,是一对完美的搭档。
2.4.3怎么降低单棵决策树的复杂度?
抑制单颗决策树的复杂度的方法有很多:
- 限制树的最大深度、限制叶子节点的最少样本数量、限制节点分裂时的最少样本数量
- 吸收bagging的思想对训练样本采样(subsample),在学习单颗决策树时只使用一部分训练样本
- 借鉴随机森林的思路在学习单颗决策树时只采样一部分特征
- 在目标函数中添加正则项惩罚复杂的树结构等。
现在主流的GBDT算法实现中这些方法基本上都有实现,因此GBDT算法的超参数还是比较多的,应用过程中需要精心调参,并用交叉验证的方法选择最佳参数。
2.5、对上面的总结
以上说明了GBDT的由来,以及GBDT采用决策树的好处,抑制决策树单棵拟合能力的方法。一直没有说boosting族最重要的一点,怎么在已有模型的基础上构建下一个基学习器?
对应到GBDT中就是:怎么用梯度提升的方法,在已有模型的基础上,学习到下一个决策树模型?
---------------------------------------------------------------------------------------------------------------------
题外话:理解机器学习的关键因素
目标函数通常定义为如下形式:
其中,第一部分是损失函数,用来衡量模型拟合训练数据的好坏程度;第二部分称之为正则项,用来衡量学习到的模型的复杂度。
比如,在下面会把树的深度、节点数等定义成正则项作为模型的复杂度。
为什么目标函数会定义为损失函数和正则项两部分?
目标函数之所以定义为损失函数和正则项两部分,是为了尽可能平衡模型的偏差和方差(Bias Variance Trade-off)。
最小化目标函数意味着同时最小化损失函数和正则项:
- 损失函数最小化表明模型能够较好的拟合训练数据,一般也预示着模型能够较好地拟合真实数据(groud true);
- 另一方面,对正则项的优化鼓励算法学习到较简单的模型,简单模型一般在测试样本上的预测结果比较稳定、方差较小(奥坎姆剃刀原则)。正则项越小,目标函数越小,同时模型复杂度越低。
也就是说,优化损失函数尽量使模型走出欠拟合的状态,优化正则项尽量使模型避免过拟合。
---------------------------------------------------------------------------------------------------------------------
三、GBDT的推导
3.1、如何在不改变原有模型的结构上提升模型的拟合能力
不改变原有模型,那么怎么减小误差?==>只能添加别的模型,去拟合误差。注意,这里的拟合,不是以学习误差为目的,而是为了学习已有模型未拟合的样本部分。(虽然结果一样,但是目的不一样)
就比如在回归模型中,预测值是一个实值,令标签值为10,模型F1(x)只能拟合到目标的6,还剩下4没拟合,那我用别的模型去拟合这剩下的4,(旧的模型只需要管好他自己就行),然后两个模型的结果相加。
对于同一个样本标签a,F1(x)拟合到了0.6a,F2(x)拟合到了剩下的0.3a(注意是剩下的,不是重复的)。然后0.6a+0.3a能够得到一个更好的结果0.9a。
相比于只用一个模型,这样的加性模型是不是结果要好很多。
3.2、从基于残差的提升方法引入基于梯度的提升方法(一阶泰勒展开)
按照上面的思想,我们可以举出这样的栗子:
假设现在你有样本集(x1,y1),(x2,y2),(x3,y3)...(xn,yn),用一个模型F(x)去拟合这些数据(即让F(x)输出值逼近标签yi),并且定义目标函数为:
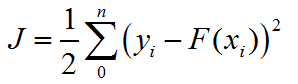
在训练一会后,你发现虽然模型的拟合能力效果不错,但是仍有一些差距。比如预测值F(x1)=0.8,真实值y1=1.0;预测值F(x2)=1.1,真实值y2=1.4。
重点来了:根据上面所说,我们可以构造一个F2(x)模型去拟合已有模型F(x)未能完全拟合的部分。即:y - F(x)。于是,对于F(x2)来说,每个样本需要拟合的值就变成了:(x1, y1 - F1(x)),(x2, y2 - F1(x)),(x3, y3 - F1(x))...(xn, yn - F1(x))。
y值已经改变成残差了。
另外,我们也能发现,我们这里想要拟合的残差,正好是原始模型目标函数的梯度:

也就是说,无意中,我们用损失函数对当前模型的梯度,去构造了新的第 t 个模型。所以,基于残差的提升方法(损失函数是平方差)也是梯度提升方法的一个特例。
到这里,我们认为的梯度提升方法构建新的模型方法,是求得当前损失函数对已有模型的梯度得到的(当L对f可微,f对x不可微时,那么L对x也就不可微,此时用一阶泰勒公式展开,也会用到梯度)。这是基于一阶泰勒公式展开得到的梯度提升方法,可以参考深入理解GBDT一文。
以上是用一阶泰勒展开时,所得到的梯度提升方法 ,下面重点介绍一下二阶泰勒展开所得到的梯度提升方法。不变的是,依然是损失函数对当前模型F(x)进行求导,只不过不止求一阶导,还要求二阶导。
3.3 加法模型
3.3.1、初步认识加法模型
梯度提升方法可以看做是由K个基学习器组成的加法模型:
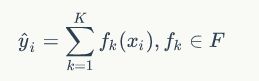
其中F为所有基学习器模型组成的函数空间。该模型的参数为Θ={f1,f2,f3,....fk},与一般的机器学习算法不同的是,加法模型不是学习单个参数,而是直接学习函数集合。
3.3.2、如何学习加法模型
为了学习到这个模型,可以用前向分步算法。如果能够从前往后每一步只学习一个即函数及其系数,逐步逼近优化目标函数,那么就可以简化复杂度。这一学习过程被称为boosting。
定义模型:
具体的说,我们从一个常量预测开始,每次学习一个新的函数,在一直学习到t个函数,构建模型的过程如下:
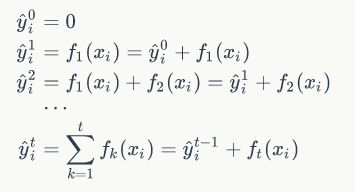
那么,如何在每一步,加入合适的函数 f 达到不断逼近目标函数的目的呢?首先定义加法模型的目标函数:
定义目标函数:
其中,后半部分Ω(fi)表示第i个基学习器的复杂度。比如,我们定义树的复杂度为节点数量,树的深度或者叶节点所对应的分数的L2范数等等。
已有了目标函数,我们以最小化目标函数为指导原则构造每一步被加入的函数 f :
因为boosting的个体学习器间存在强依赖关系,串行生成新的模型。这里也是,在前面t-1个基学习器已知的情况下,学习到第t个基学习器。
目标函数可以由 yt-t 和 ft表示。而 yt-t 是已知的,则目标函数就可以用 ft 表示。
我们想要得到 一个ft模型能够使目标函数最小,那么同理,只要我们最小化目标函数,就能得到 ft 模型。
和对于y = x2,我们想要得到一个数x使y最小,那么我们就最小化y,就能得到想要的x。令y’ = 0。求得x等于0,那么0就是我们想要的x。
在第 t 步,对于样本xi的预测值为:
其中,后者ft(xi)就是这一轮迭代中我们要学习的函数模型,这个时候,可以将目标函数写成:
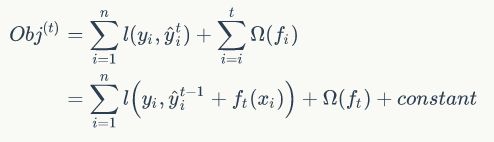
举例说明,假设损失函数为平方损失函数,则目标函数为:
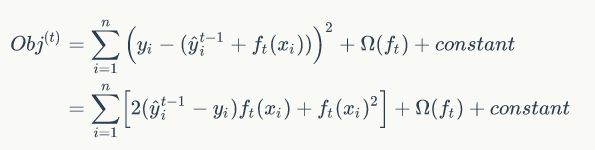
式中第一部分就是损失函数L。

其中,gi是损失函数对模型yt-1的一阶导数,hi是损失函数对模型yt-1的二阶导数。

由于前面模型已知,所以可以求出损失函数相对于当前模型的一阶导数和二阶导数,那么此时的目标函数就只有 一个参数 ft,那么通过在训练样本集上最小化等式(5),就可求得 ft,从而逐步得到加法模型。
3.3 GBDT算法
由于上面所说的决策树的优点,我们经常采用决策树作为梯度提升方法的基学习器,于是我们有了GBDT算法。

对于公式(6)的解释,首先,第一行到第二行,已经说明,决策树定义为ft(x) = wq(x)。第二行到第三行,叶子节点共有 j 个,所以样本会被划分为 j 个子集。而决策树的特点,就在于每个叶子节点上的值是相同的(回归的话就是数值相同,分类的话就是类别相同,比如一个叶节点上的都是好瓜)。所以可以认为wq(x)其实只有 j 个值,分别是wj。再带入上面的正则项定义,于是可以得到第三行的公式。

对公式(7)的解释,定义了G和H以后,目标函数只有一个参数wj了,那么直接对wj求导,并令其为0,即可得到wj的表达式。也就是叶子节点对应的值。
此时,目标函数的值为:
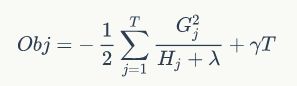
于是单棵决策树的学习过程可以大致描述为:
- 1、 枚举所有可能的树结构q
- 2、用等式(8)为每个q计算其对应的目标函数的值,最小的说明此树的结构越好,是我们想要的模型。
- 3、根据上一部的结果,找到最佳的树结构,用等式(7)为树的每个叶子节点计算预测值。
下面是对如何生成决策树的具体的介绍(并没有看懂多少。。有时间再回来看看)
注意:GBDT的基学习器是分类回归树CART,使用的是CART树中的回归树。分类回归树CART算法是一种基于二叉树的机器学习算法,其既能处理回归问题,又能处理分类为题。
对于单个分类回归树CART算法的具体步骤,参考简单易学的机器学习算法——梯度提升决策树GBDT
