Python程序设计与科学计算精录&总结Episode.7 Python进阶:数据分析库Pandas、Matplotlib与Scikit-learn(基于VS2019)
东街有一位老妇人,在辟旧的房子里住了几十年,邻里却无人不觉得她怪,因为她总是穿着一双蹩脚的巨鞋出门,走路时鞋梆都能兹出响声来。
终于有一天,一个小孩开口了,“您为什么老是穿这么大的鞋呀,根本不合脚。”
老妇人咯咯笑道:“大鞋小鞋都是花一样的价钱,那我为什么不买大的呢?”
西街有一位年轻人,苦读诗书渴望考举入仕,但邻里无人不觉得他怪,因为他总是穿着一双蹩脚的小鞋出门,脚趾都快把鞋头给撑破了。
终于有一天,一个老者开口了,“你为什么老是穿这么小的鞋呀,根本不合脚。”
年轻人若有所思:“我要是穿大鞋,脚就一直长。脚要一直长,我就得一直花钱买新鞋。不如穿个小鞋子,这样脚就不会继续长下去了。”
没人知道他们是否见过面,论过鞋,也不知道这之后他们还在穿什么。只知道此事一出,街拐角的鞋店又倒了一家。
《大小鞋》 頠宸
本文中有部分内容总结或者思路源自于@文哥的学习日记,在此表示感谢!
一、数据分析库:Pandas
Pandas数据分析部分在之前的自动化办公中有所总结,这里我依照异步社区图书python科学计算的内容再深入探讨其用法。
利用import pandas或者import pandas as pd可以导入我们需要的pandas类及其所有对象。
1、创建Series对象和DataFrame对象:
Series对象是一种Pnadas的基本对象,相当于是一个用来表示Numpy中ndarray数组的字典。字典的属性由索引赋予。Series的创建方式是:
pd.Series(data=None, index=None)
其中data是传入数据,index是传入索引。如果是手动输入那么index和data的长度必须相同,而且二者都应该是列表。当然,对于缺省index参数的时候,data可以是ndarray,这时候自动创建索引0~len(data)-1;data也可以是dict字典,那么直接依据字典建立键值对即可。此外data也可以是标量,那么 这个时候我们需要传入index索引值,依据索引的个数,重复data标量值以匹配索引的长度。
DataFrame是一个二维标记表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值)等。相当于二维字典或者二维Series对象的感觉,也可以被视作一个类Excel表。其创建方式是:
pd.DataFrame(data, index, columns)
其中data是传入数据,可以传入多种类型,如:二维数组、能转化为二维数组的嵌套列表、矩阵、字典(字典中的键值对会转化为DataFrame中的列)。index是行索引,columns是列索引,不指定的话都是用数值索引填充,和上面所说相同。
2、DataFrame对象的数据选取:
(1)索引、切片:
我们可以根据列名来选取一列,返回一个Series:
frame2['year']
#输出
one 2000
two 2001
three 2002
four 2001
five 2002
Name: year, dtype: int64我们还可以选取多列或者多行:
data = pd.DataFrame(np.arange(16).reshape((4,4)),index = ['Ohio','Colorado','Utah','New York'],columns=['one','two','three','four'])
data[['two','three']]
#输出
two three
Ohio 1 2
Colorado 5 6
Utah 9 10
New York 13 14
#取行
data[:2]
#输出
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7当然,在选取数据的时候,我们还可以根据逻辑条件来选取:
data[data['three']>5]
#输出
one two three four
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15pandas提供了专门的用于索引DataFrame的方法,即使用ix方法进行索引,不过ix在最新的版本中已经被废弃了,如果要是用标签,最好使用loc方法,如果使用下标,最好使用iloc方法:
#data.ix['Colorado',['two','three']]
data.loc['Colorado',['two','three']]
#输出
two 5
three 6
Name: Colorado, dtype: int64
data.iloc[0:3,2]
#输出
Ohio 2
Colorado 6
Utah 10
Name: three, dtype: int64(2)修改数据:
可以使用一个标量修改DataFrame中的某一列,此时这个标量会广播到DataFrame的每一行上:
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame2 = pd.DataFrame(data,index=['one','two','three','four','five'],columns=['year','state','pop','debt'])
frame2
frame2['debt']=16.5
frame2
#输出
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5也可以使用一个列表来修改,不过要保证列表的长度与DataFrame长度相同:
frame2.debt = np.arange(5)
frame2
#输出
year state pop debt
one 2000 Ohio 1.5 0
two 2001 Ohio 1.7 1
three 2002 Ohio 3.6 2
four 2001 Nevada 2.4 3
five 2002 Nevada 2.9 4可以使用一个Series,此时会根据索引进行精确匹配:
val = pd.Series([-1.2,-1.5,-1.7],index=['two','four','five'])
frame2['debt'] = val
frame2
#输出
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7(3)重新索引:
使用reindex方法对DataFrame进行重新索引。对DataFrame进行重新索引,可以重新索引行,列或者两个都修改,如果只传入一个参数,则会从新索引行:
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index=[1,4,5],columns=['Ohio','Texas','California'])
frame2 = frame.reindex([1,2,4,5])
frame2
#输出
Ohio Texas California
1 0.0 1.0 2.0
2 NaN NaN NaN
4 3.0 4.0 5.0
5 6.0 7.0 8.0
states = ['Texas','Utah','California']
frame.reindex(columns=states)
#输出
Texas Utah California
1 1 NaN 2
4 4 NaN 5
5 7 NaN 8填充数据只能按行填充,此时只能对行进行重新索引:
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index = ['a','c','d'],columns = ['Ohio','Texas','California'])
frame.reindex(['a','b','c','d'],method = 'bfill')
#frame.reindex(['a','b','c','d'],method = 'bfill',columns=states) 报错(4)指定丢弃轴上的值:
可以使用drop方法丢弃指定轴上的值,不会对原DataFrame产生影响。
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index = ['a','c','d'],columns = ['Ohio','Texas','California'])
frame.drop('a')
#输出
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
frame.drop(['Ohio'],axis=1)
#输出
Texas California
a 1 2
c 4 5
d 7 8
3、数据处理:
(1)算术运算:
DataFrame在进行算术运算时会进行补齐,在不重叠的部分补足NA:
df1 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
df2 = pd.DataFrame(np.arange(12).reshape((4,3)),columns = list('bde'),index=['Utah','Ohio','Texas','Oregon'])
df1 + df2
#输出
b c d e
Colorado NaN NaN NaN NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
Utah NaN NaN NaN NaN可以使用fill_value方法填充NA数据,不过两个df中都为NA的数据,该方法不会填充:
df1.add(df2,fill_value=0)
#输出
b c d e
Colorado 6.0 7.0 8.0 NaN
Ohio 3.0 1.0 6.0 5.0
Oregon 9.0 NaN 10.0 11.0
Texas 9.0 4.0 12.0 8.0
Utah 0.0 NaN 1.0 2.0(2)函数的应用和映射:
numpy的元素级数组方法,也可以用于操作Pandas对象:
frame = pd.DataFrame(np.random.randn(3,3),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
np.abs(frame)
#输出
b c d
Ohio 0.367521 0.232387 0.649330
Texas 3.115632 1.415106 2.093794
Colorado 0.714983 1.420871 0.557722另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能。
f = lambda x:x.max() - x.min()
frame.apply(f)
#输出
b 3.830616
c 2.835978
d 2.743124
dtype: float64
frame.apply(f,axis=1)
#输出
Ohio 1.016851
Texas 4.530739
Colorado 2.135855
dtype: float64
def f(x):
return pd.Series([x.min(),x.max()],index=['min','max'])
frame.apply(f)
#输出
b c d
min -0.714983 -1.415106 -0.649330
max 3.115632 1.420871 2.093794元素级的Python函数也是可以用的,使用applymap方法:
format = lambda x:'%.2f'%x
frame.applymap(format)
#输出
b c d
Ohio 0.37 -0.23 -0.65
Texas 3.12 -1.42 2.09
Colorado -0.71 1.42 -0.56(3)排序及排名:
对于DataFrame,sort_index可以根据任意轴的索引进行排序,并指定升序降序:
frame = pd.DataFrame(np.arange(8).reshape((2,4)),index=['three','one'],columns=['d','a','b','c'])
frame.sort_index()
#输出
d a b c
one 4 5 6 7
three 0 1 2 3
frame.sort_index(1,ascending=False)
#输出
d a b c
one 4 5 6 7
three 0 1 2 3DataFrame也可以按照值进行排序:
#按照任意一列或多列进行排序
frame.sort_values(by=['a','b'])
#输出
d a b c
three 0 1 2 3
one 4 5 6 7(4)汇总和计算描述统计:
DataFrame中的实现了sum、mean、max等方法,我们可以指定进行汇总统计的轴,同时,也可以使用describe函数查看基本所有的统计项:
df = pd.DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=['a','b','c','d'],columns=['one','two'])
df.sum(axis=1)
#输出
one 9.25
two -5.80
dtype: float64
#Na会被自动排除,可以使用skipna选项来禁用该功能
df.mean(axis=1,skipna=False)
#输出
a NaN
b 1.300
c NaN
d -0.275
dtype: float64
#idxmax返回间接统计,是达到最大值的索引
df.idxmax()
#输出
one b
two d
dtype: object
#describe返回的是DataFrame的汇总统计
#非数值型的与数值型的统计返回结果不同
df.describe()
#输出
one two
count 3.000000 2.000000
mean 3.083333 -2.900000
std 3.493685 2.262742
min 0.750000 -4.500000
25% 1.075000 -3.700000
50% 1.400000 -2.900000
75% 4.250000 -2.100000
max 7.100000 -1.300000DataFrame也实现了corr和cov方法来计算一个DataFrame的相关系数矩阵和协方差矩阵,同时DataFrame也可以与Series求解相关系数。
frame1 = pd.DataFrame(np.random.randn(3,3),index=list('abc'),columns=list('abc'))
frame1.corr
#输出
frame1.cov()
#输出
a b c
a 0.884409 0.357304 0.579613
b 0.357304 4.052147 2.442527
c 0.579613 2.442527 1.627843
#corrwith用于计算每一列与Series的相关系数
frame1.corrwith(frame1['a'])
#输出
a 1.000000
b 0.188742
c 0.483065
dtype: float64 (5)处理缺失数据:
Pandas中缺失值相关的方法主要有以下三个:
isnull方法用于判断数据是否为空数据;
fillna方法用于填补缺失数据;
dropna方法用于舍弃缺失数据。
上面两个方法返回一个新的Series或者DataFrame,对原数据没有影响,如果想在原数据上进行直接修改,使用inplace参数:
data = pd.DataFrame([[1,6.5,3],[1,np.nan,np.nan],[np.nan,np.nan,np.nan],[np.nan,6.5,3]])
data.dropna()
#输出
0 1 2
0 1.0 6.5 3.0对DataFrame来说,dropna方法如果发现缺失值,就会进行整行删除,不过可以指定删除的方式,how=all,是当整行全是na的时候才进行删除,同时还可以指定删除的轴。
data.dropna(how='all',axis=1,inplace=True)
data
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0DataFrame填充缺失值可以统一填充,也可以按列填充,或者指定一种填充方式:
data.fillna({1:2,2:3})
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 2.0 3.0
2 NaN 2.0 3.0
3 NaN 6.5 3.0
data.fillna(method='ffill')
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 6.5 3.0
2 1.0 6.5 3.0
3 1.0 6.5 3.0
4、Pandas中的统计函数:
这里需要先创建DataFrame或者Series对象,然后调用下表总结的统计函数之一实现我们的功能。注意下面Pandas中三种不同内置数据结构的轴参数。
Series: 没有轴参数
DataFrame: “index” (axis=0, default),“columns” (axis=1)
Panel: “items” (axis=0),“major” (axis=1, default), “minor” (axis=2)
| Function | Description | 描述 |
|---|---|---|
| count | Number of non-null observations | 观测值的个数 |
| sum | Sum of values | 求和 |
| mean | Mean of values | 求平均值 |
| mad | Mean absolute deviation | 平均绝对方差 |
| median | Arithmetic median of values | 中位数 |
| min | Minimum | 最小值 |
| max | Maximum | 最大值 |
| argmin | Calculate the index position (integer) that can get the minimum value | 计算能够获取到最小值的索引位置(整数) |
| argmax | Calculate the index position where the maximum value can be obtained | 计算能够获取到最大值的索引位置 |
| idxmin | Row index of each column minimum | 每列最小值的行索引 |
| idxmax | Row index of the maximum value per column | 每列最大值的行索引 |
| mode | Mode | 众数 |
| abs | Absolute Value | 绝对值 |
| prod | Product of values | 乘积 |
| std | Bessel-corrected sample standard deviation | 标准差 |
| var | Unbiased variance | 方差 |
| sem | Standard error of the mean | 标准误 |
| skew | Sample skewness (3rd moment) | 偏度系数 |
| kurt | Sample kurtosis (4th moment) | 峰度 |
| quantile | Sample quantile (value at %) | 分位数 |
| cumsum | Cumulative sum | 累加 |
| cumprod | Cumulative product | 累乘 |
| cummax | Cumulative maximum | 累最大值 |
| cummin | Cumulative minimum | 累最小值 |
| cov() | covariance | 协方差 |
| corr() | correlation | 相关系数 |
| rank() | rank by values | 排名 |
| pct_change() | time change | 时间序列变化 |
以下是一些常见的统计函数使用的代码示例,可供参考:
# 1汇总类统计
# 2唯一去重和按值计数
# 3 相关系数和协方差
import pandas as pd
# 0 读取csv数据
df = pd.read_csv("beijing_tianqi_2018.csv")
df.head()
# 换掉温度后面的后缀
df.loc[:,"bWendu"] = df["bWendu"].str.replace("℃","").astype("int32")
df.loc[:,"yWendu"] = df["yWendu"].str.replace("℃","").astype("int32")
df.head(3)
# 1 汇总类统计
# 一下子提取所有数字列的统计结果
df.describe()
# 查看单个Series的数据
df["bWendu"].mean()
# 最高温
df["bWendu"].max()
# 最低温
df["bWendu"].min()
# 2 唯一去重和按值计数
# 2.1 唯一性去重 一般不用于数值列,而是枚举、分类列
df["fengxiang"].unique()
df["tianqi"].unique()
df["fengli"].unique()
# 2.2 按值计数(降序排列)
df["fengxiang"].value_counts()
df["tianqi"].value_counts()
df["fengli"].value_counts()
# 3 相关系数和协方差
# 用途:
# 1、两只股票,这不是同涨同落?程度多大?正相关还是负相关?
#2、产品销量的波动,跟哪些因素正相关、负相关,程度有多大?
# 1、协方差:衡量同向反向程度。 如果协方差为正,说明想想X,Y同向程度越高;
# 如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高
# 2、相关系数:衡量相似度程度。当他们的相关系数为1时,说明两个变量变化时
# 的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大
# 协方差矩阵
df.cov()
# 相关系数矩阵
df.corr()
# 单独查看空气质量和最高温度的相关系数
df["aqi"].corr(df["bWendu"])
df["aqi"].corr(df["yWendu"])
# 空气质量和温差的相关系数
df["aqi"].corr(df["bWendu"]-df["yWendu"])
5、Pandas与文件读取操作:
以下是一些常见的文件读取功能使用的代码示例,可供参考:
import pandas as pd
pd.read_csv(filepath_or_buffer,header,parse_dates,index_col)
参数:
filepath_or_buffer:
字符串,或者任何对象的read()方法。这个字符串可以是URL,有效的URL方案包括http、ftp、s3和文件。可以直接写入"文件名.csv"
header:
将行号用作列名,且是数据的开头。
注意当skip_blank_lines=True时,这个参数忽略注释行和空行。所以header=0表示第一行是数据而不是文件的第一行。
(1)、header=None
即指定原始文件数据没有列索引,这样read_csv为其自动加上列索引{从0开始}
ceshi.csv原文件内容:
c1,c2,c3,c4
a,0,5,10
b,1,6,11
c,2,7,12
d,3,8,13
e,4,9,14
df=pd.read_csv("ceshi.csv",header=None)
print(df)
结果:
0 1 2 3
0 c1 c2 c3 c4
1 a 0 5 10
2 b 1 6 11
3 c 2 7 12
4 d 3 8 13
5 e 4 9 14
(2)、header=None,并指定新的索引的名字names=seq序列
df=pd.read_csv("ceshi.csv",header=None,names=range(2,6))
print(df)
结果:
2 3 4 5
0 c1 c2 c3 c4
1 a 0 5 10
2 b 1 6 11
3 c 2 7 12
4 d 3 8 13
5 e 4 9 14
(3)、header=None,并指定新的索引的名字names=seq序列;如果指定的新的索引名字的序列比原csv文件的列数少,那么就截取原csv文件的倒数列添加上新的索引名字
df=pd.read_csv("ceshi.csv",header=0,names=range(2,4))
print(df)
结果:
2 3
c1 c2 c3 c4
a 0 5 10
b 1 6 11
c 2 7 12
d 3 8 13
e 4 9 14
(4)、header=0
表示文件第0行(即第一行,索引从0开始)为列索引
df=pd.read_csv("ceshi.csv",header=0)
print(df)
结果:
c1 c2 c3 c4
0 a 0 5 10
1 b 1 6 11
2 c 2 7 12
3 d 3 8 13
4 e 4 9 14
(5)、header=0,并指定新的索引的名字names=seq序列
df=pd.read_csv("ceshi.csv",header=0,names=range(2,6))
print(df)
结果:
2 3 4 5
0 a 0 5 10
1 b 1 6 11
2 c 2 7 12
3 d 3 8 13
4 e 4 9 14
注:这里是把原csv文件的第一行换成了range(2,6)并将此作为列索引
(6)、header=0,并指定新的索引的名字names=seq序列;如果指定的新的索引名字的序列比原csv文件的列数少,那么就截取原csv文件的倒数列添加上新的索引名字
df=pd.read_csv("ceshi.csv",header=0,names=range(2,4))
print(df)
结果:
2 3
a 0 5 10
b 1 6 11
c 2 7 12
d 3 8 13
e 4 9 14
parse_dates:
布尔类型值 or int类型值的列表 or 列表的列表 or 字典(默认值为 FALSE)
(1)True:尝试解析索引
(2)由int类型值组成的列表(如[1,2,3]):作为单独数据列,分别解析原始文件中的1,2,3列
(3)由列表组成的列表(如[[1,3]]):将1,3列合并,作为一个单列进行解析
(4)字典(如{'foo':[1, 3]}):解析1,3列作为数据,并命名为foo
index_col:
int类型值,序列,FALSE(默认 None)
将真实的某列当做index(列的数目,甚至列名)
index_col为指定数据中那一列作为Dataframe的行索引,也可以可指定多列,形成层次索引,默认为None,即不指定行索引,这样系统会自动加上行索引。
举例:
df=pd.read_csv("ceshi.csv",index_col=0)
print(df)
结果:
c2 c3 c4
c1
a 0 5 10
b 1 6 11
c 2 7 12
d 3 8 13
e 4 9 14
表示:将第一列作为索引index
df=pd.read_csv("ceshi.csv",index_col=1)
print(df)
结果:
c1 c3 c4
c2
0 a 5 10
1 b 6 11
2 c 7 12
3 d 8 13
4 e 9 14
表示:将第二列作为索引index
df=pd.read_csv("ceshi.csv",index_col="c1")
print(df)
结果:
c2 c3 c4
c1
a 0 5 10
b 1 6 11
c 2 7 12
d 3 8 13
e 4 9 14
表示:将列名"c1"这里一列作为索引index
【注】:这里将"c1"这一列作为索引即行索引后,"c1"这列即不在属于列名这类,即不能使用df['c1']获取列值
【注】:read_csv()方法中header参数和index_col参数不能混用,因为header指定列索引,index_col指定行索引,一个DataFrame对象只有一种索引
squeeze:
布尔值,默认FALSE
TRUE 如果被解析的数据只有一列,那么返回Series类型。Pandas中read_csv和read_table的区别
注:使用pandas读取文件格式为pandas特有的dataframe格式(二维数据表格),常使用info()来查看统计特性
Pandas中常见的加载文件的方式:
- 函数:read_csv 从文件、URL、文件型对象中加载带分隔符的数据。默认分割符为逗号
- 函数:read_table从文件、URL、文件型对象中加载带分隔符的数据。默认分割符为制表符(‘\t’)
- 函数:read_fwf 读取定宽列格式数据(也就是说,没有分隔符)
- 函数:read_clipboard 读取剪贴板中的数据,也可以看做read_table的剪贴板。在将网页转换为表格时很有用。
此处博主找到了一篇总结简短而且均有实例图演示的总结文章,分享给大家,可以参考学习:https://www.pianshen.com/article/9944139169/
Pandas模块内的功能还很多,具体内容可以去网上查找Pandas中文手册,一点一点学习或者使用时直接翻看查阅。事实上对于这些模块化函数化的东西,记忆每个函数的语法和功能是不可取的。我们终究学习的其实是学习的方法。
二、可视化绘图工具库—Matplotlib:
从名字不难看出,这个原本应该叫做plotlib的库,因为建立灵感来自Matlab,所以全名被称作Matplotlib。这是Python中最强大的面向对象绘图库,而且集成了比较直观的图示界面。尤其是在直方图或者函数图像的绘制上,可以同时使用LaTeX形式进行坐标刻度的标签标记。一般来说,matplotlib和numpy配合使用效果最好,所以import工作应该同时包含这两个包。
1、初级绘制:
我们以中国银行股票收盘价曲线作为例子来作为开场。至于中国银行股票信息,一个方法是按照自动化办公章节中提到的利用yahoo进行爬虫爬取,另一个方法是直接下载现成的。链接:http://pan.baidu.com/s/1gfxRFbH 密码:d3id。当然现成数据仅限到2015年,且网盘保存容易丢失。建议返回前几章复习一下如何用get方法爬取金融数据。
首先我们通过pandas导入数据,并提取出收盘价一列:
ChinaBank = pd.read_csv('data/ChinaBank.csv',index_col = 'Date')
ChinaBank = ChinaBank.iloc[:,1:]
ChinaBank.index = pd.to_datetime(ChinaBank.index)
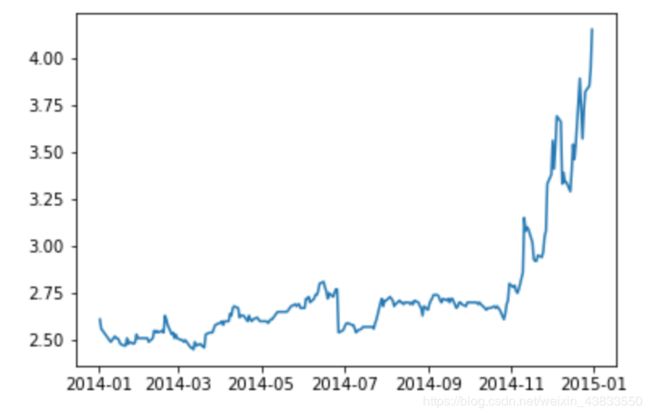
Close = ChinaBank.Close我们来绘制2014年中国银行股票收盘价的走势图:
plt.plot(Close['2014'])
plt.show()最终的绘图结果是这样的:
2、修改绘图属性:
(1)绘图坐标:
绘图时往往需要修改横纵坐标轴的范围,以使曲线位于图形的中间位置:
plt.plot([1,1,0,0,-1,0,1,1,-1])
plt.show()我们可以通过ylim方法修改y轴的范围,比如我们想修改为(-1.5,1.5),同理,我们可以通过xlim方法来修改x轴的坐标范围:
plt.plot([1,1,0,0,-1,0,1,1,-1])
plt.ylim(-1.5,1.5)
plt.show()我们可以通过xticks()和yticks()函数设定坐标的标签,两个函数主要有以下两个参数:
location:指坐标的位置.
labels:对应的坐标位置显示的标签.
两个参数一般是等长的数组,该函数另一个常用的参数是rotation参数,可以对坐标标签进行适当的旋转,看下面的例子:
plt.plot([1,1,0,0,-1,0,1,1,-1])
plt.ylim(-1.5,1.5)
plt.xticks(range(9),['02-01','02-02','02-03','02-04',
'02-05','02-06','02-07','02-08','02-09'],rotation=45)
plt.show()操作的结果是:X坐标由原来的数值1,2,3变成了我们设置的日期,同时标签与X轴成45度角。
(2)标题:
添加标题可以通过title函数来实现,该函数主要有两个参数,第一个是str,指明标题的内容,第二个是loc,指明标题的位置,可以选择center,left或者right,默认是center:
plt.plot(Close['2014'])
plt.title('中国银行2014年收盘价曲线',loc='right')
plt.show()在mac的Ipython环境下,中文是无法正常显示的,我们可以通过下面的方法解决:
from matplotlib.font_manager import FontManager, FontProperties
def getChineseFont():
return FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
plt.plot(Close['2014'])
plt.title('中国银行2014年收盘价曲线',loc='right',fontproperties=getChineseFont())
plt.show()设置坐标轴标签可以通过xlabel和ylabel函数来实现:
plt.plot(Close['2014'])
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.show()绘图时常常会在图形背景中增添方格,以便于人们更直观地读取线条中点的坐标取值以及线条整体的分布范围.可以使用grid函数增加和设定图形的背景.
函数原型:
matplotlib.pyplot.grid(b=None,which='major',axis='both',**kwargs)
参数b,设定是否显示grid,如果要显示grid,将b参数设置为True参数which,设定坐标轴的分割标示线的类型,取值为major、minor或者both,默认为major,表示以原本的坐标轴分割标示线为准;若取值为minor,则进一步细分坐标轴分割标示线,但是分割标准要提前设定,如果只是设定值为minor,则grid不会显示;both表示大小区间坐标轴分割线都有参数axis,指定绘制grid 的坐标轴,取值为both,x或y。
plt.plot(Close['2014'])
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()当多条曲线显示在同一张图中时,图例可以帮助我们区分识别不同的曲线,在中国银行的数据中,我们可以把开盘价和收盘价同时放在一张曲线图中,并为二者增加图例.
增加图例使用legend()函数,legend函数中最常见的一个参数是loc参数,表示图例在图中显示的位置,我们一般设置为best就好,表示在图中最适宜的位置显示图例成功增加图例的前提是在绘图时提供label属性值,label属性值就是图例上的文本,同时我们还要注意中文显示的问题。
Open=ChinaBank.Open
plt.plot(Close['2014'],label='收盘价')
plt.plot(Open['2014'],label='开盘价')
plt.legend(loc='best',prop=getChineseFont())
plt.show()
(3)线条:
在绘制曲线时,除了绘制实线外,还可以绘制虚线,plot函数中的linestyle参数用于设置曲线类型,为了书写方便,有时候用ls代替linestyle。有如下的常见取值:
| 类型 | 名称取值 | 符号取值 |
|---|---|---|
| 实线 | 'solid' | '-' |
| 虚线 | 'dashed' | '--' |
| 线点 | 'dashdot' | '-.' |
| 点线 | 'dotted' | ':' |
| 不画线 | 'None' | ' ' |
plt.plot(Close['2014'],label='收盘价',linestyle='solid')
plt.plot(Open['2014'],label='开盘价',ls='-.')
plt.legend(loc='best',prop=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()修改图形的颜色通过plot函数中的color参数来设置,也可以简写成c,最常用的颜色指定方式是指定颜色的名称或者简写,也可以通过RGB数组来设置:
plt.plot(Close['2014'],label='收盘价',c='r',linestyle='solid')
plt.plot(Open['2014'],label='开盘价',c='b',ls=':')
plt.legend(loc='best',prop=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()除了设置线条类型外,还可以设置数据点的形状,图形的形状通过marker参数来设置.marker参数主要有下面的取值:
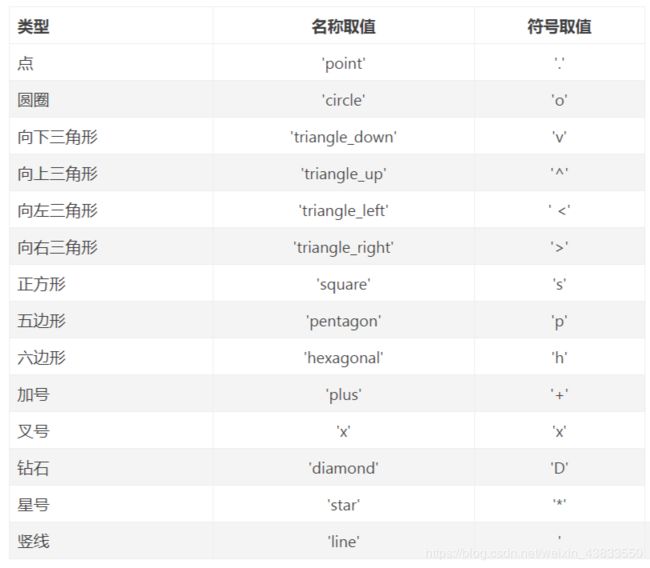
plt.plot(Close['2014'],label='收盘价',c='r',marker='o',linestyle='solid')
plt.plot(Open['2014'],label='开盘价',c='b',marker='v',ls='-.')
plt.legend(loc='best',prop=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()线条宽度可以通过plot函数中的linewidth函数指定,也可简写为lw:
plt.plot(Close['2014'],label='收盘价',c='r',marker='o',linestyle='solid',linewidth=1)
plt.plot(Open['2014'],label='开盘价',c='b',marker='>',ls='-.',lw=3)
plt.legend(loc='best',prop=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()前面讲到的线条的类型,图形的颜色和点的形状类型,可以合为一个属性,使用他们的符号取值将其拼接,这个参数的位置是有限制的,比如在下面的代码中,它只能放在label前面,在label参数后面则会报错。
plt.plot(Close['2014'],'--rD',label='收盘价',linewidth=1)
plt.plot(Open['2014'],'--b>',label='开盘价',lw=3)
plt.legend(loc='best',prop=getChineseFont())
plt.xlabel('日期',fontproperties=getChineseFont())
plt.ylabel('收盘价',fontproperties=getChineseFont())
plt.title('中国银行2014年收盘价曲线',loc='center',fontproperties=getChineseFont())
plt.grid(True,axis='y')
plt.show()
3、⭐常见图形的绘制:
(1)柱状图:
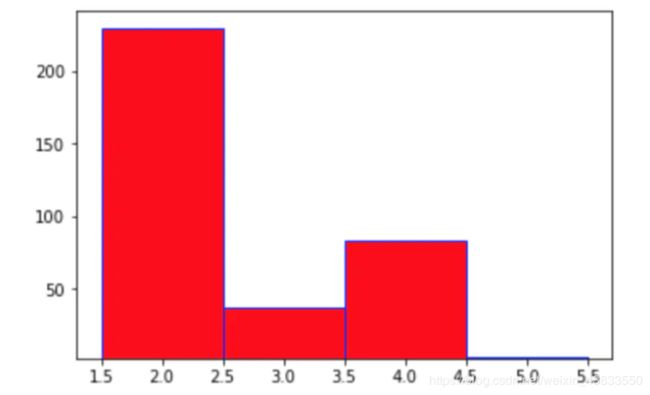
在刚才的收盘价数据中,统计收盘价落在(2,3],(3,4],(4,5],(5,6]的天数,分别有228,35,81,1天,我们来绘制柱状图:
plt.bar(left=[2,3,4,5],height=[228,35,81,1],bottom=2,width=1,color='r',edgecolor='b')
绘制的结果是:
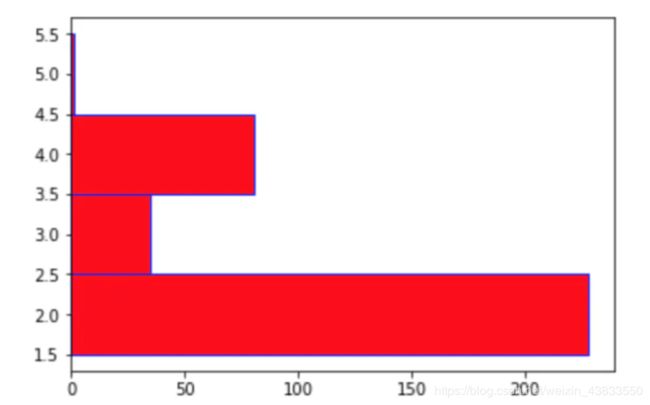
使用barh函数可以绘制水平柱状图:
plt.barh([2,3,4,5],[228,35,81,1],height=1.0,color='r',edgecolor='b')
绘制的效果是将上图完全横向:
(2)直方图:
柱状图主要用于展示定性数据的分布,对于定量数据的分布,一般使用直方图来呈现。绘制直方图用pyplot包中的hist函数来实现,主要有以下几个参数:
bins用于设置直方图分布区间的个数;
range用于设置直方图的小矩形的最小值与最大值;
orientation用于设置直方图的水平或者垂直显示,默认是竖直的直方图,可以将orientation设置为horizontal使其变为水平直方图。
plt.hist(Close,bins=12)
plt.hist(Close,bins=12,orientation='horizontal')
也可以绘制累积分布直方图,将参数cumulative设置为True即可:
plt.hist(Close,range=(2.3,5.5),orientation='vertical',cumulative=True,color='r',edgecolor='b')
用此最后一种方式进行绘制,具体的绘制效果如下所示:
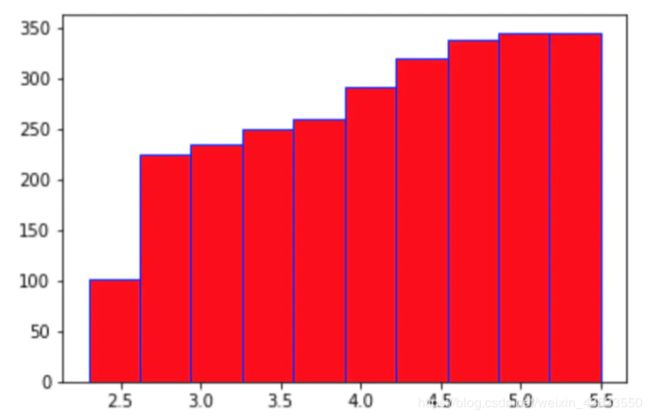
(3)饼状图:
绘制饼图使用pie方法,主要参数有:
labels:用于设置扇形图的标签
colors:用于设置扇形图的颜色
shadow:用于设定扇形图是否有阴影
plt.pie([228,35,81,1],labels=('(2,3]','(3,4]', '(4,5]','(5,6]'),colors=('b','g','r','c'),shadow=True)
具体绘制的效果如下所示:
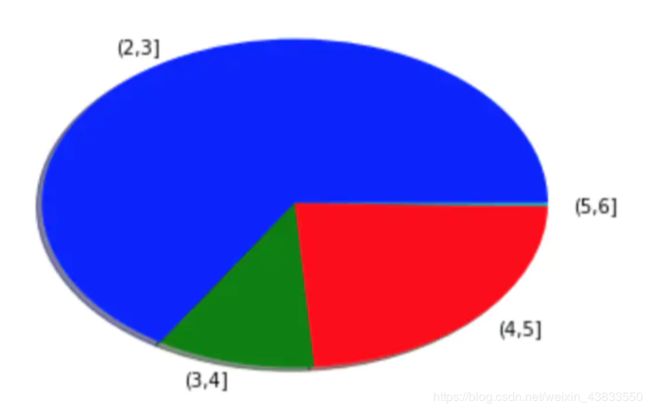
(4)箱线图:
箱线图也是在分析数据时经常用到的一种图形,正如其名,箱线图由一个矩形和两条线组成,矩形的上边和下边分别是变量的上下四分位数,中间的一条线表示数变量的中位数。在矩形的上下两边各延伸出一条线,每条线的长度一般为1.5倍的四分位距(上下四分位数之差),这两条线被视为异常值截断线,上端的线为上边缘线,下端的线为下边缘线,在线的外面可能还会有一些点,这些点一般会被认为是异常值。箱线图能够很直观地表示出一个变量的分布,也有助于检测异常值。
pyplot的boxplot函数用于绘制箱线图,主要有以下几个参数:
notch:表示箱线图的类型,默认为False,即绘制矩形箱线图,如果取值为True,表示绘制锯齿状箱线图
labels:表示箱形图的标签,一般为字符串序列类型
import numpy as np
prcData = ChinaBank.iloc[:,:4]
data = np.array(prcData)
plt.boxplot(data,labels=('Open','High','Low','Close'))
plt.title('中国银行股票箱线图',fontproperties=getChineseFont())绘制结果是:
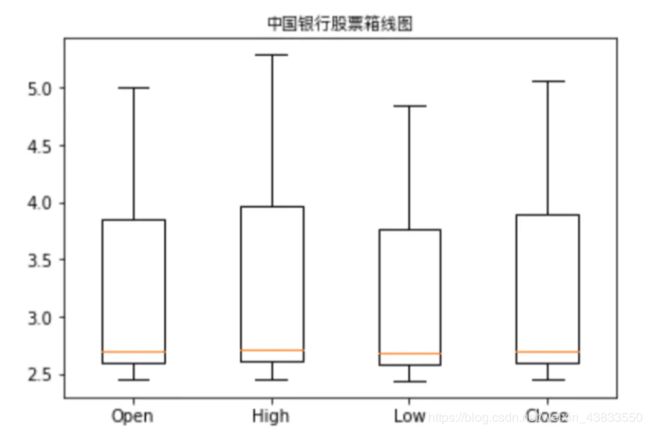
4、多图绘制:
除了上面介绍的,Matplotlib的另一大特色是面向对象的绘图,类比生活中的用纸笔绘图,我们来解释Matplotlib面向对象绘图
在使用生活中纸笔画图时,我们需要先找到一张白纸,在白纸上绘图。对于Matplotlib来说,绘图之前需要先创建一个Figure对象,Figure对象是一个空白区域,然后我们就可以在上面进行绘图。Figure对象可通过pyplot包中的figure函数来创建。
fig = plt.figure(1)在这张白纸上,我们可以选择较大区域,指画一个收盘价折线图,如果想要节约用纸或者对比两个价格序列,可以将这个纸
分成两个区域,分别绘制收盘价折线图和开盘价折线图。在Matplotlib绘图中,每个Figure对象可以包含一个或者几个Axes对象.每个Axes对象即一个绘图区域,拥有自己独立的坐标系统,假设我们现在需要两个区域,分别绘制中国银行股票的开盘价走势和收盘价走势,我们可以创建两个Axes对象。
ax1 = fig.add_axes([0.1,0.1,0.3,0.3])
ax2 = fig.add_axes([0.5,0.5,0.4,0.4])可以看到在创建Axes对象时传入了一个数值型list,list的前两个元素决定了Axes的左下角坐标,而第三个和第四个参数决定了Axes的长和宽接下来,我们基本就可以按照之前介绍的知识进行绘图了:
fig = plt.figure(1)
ax1 = fig.add_axes([0.1,0.1,0.3,0.3])
ax2 = fig.add_axes([0.5,0.5,0.4,0.4])
ax1.plot(Close[:10])
ax1.set_title('前十个交易日收盘价',fontproperties=getChineseFont())
ax1.set_xlabel('日期',fontproperties=getChineseFont())
ax1.set_ylabel('收盘价',fontproperties=getChineseFont())
ax1.set_ylim(2.4,2.65)
ax2.plot(Open[:10])
ax2.set_title('前十个交易日开盘价',fontproperties=getChineseFont())
ax2.set_xlabel('日期',fontproperties=getChineseFont())
ax2.set_ylabel('开盘价',fontproperties=getChineseFont())
ax2.set_ylim(2.4,2.65)
plt.show()绘制的效果如下,部分坐标重叠的情况可以考虑用之前提到的改坐标点范围或者修改年份表示方式来解决:
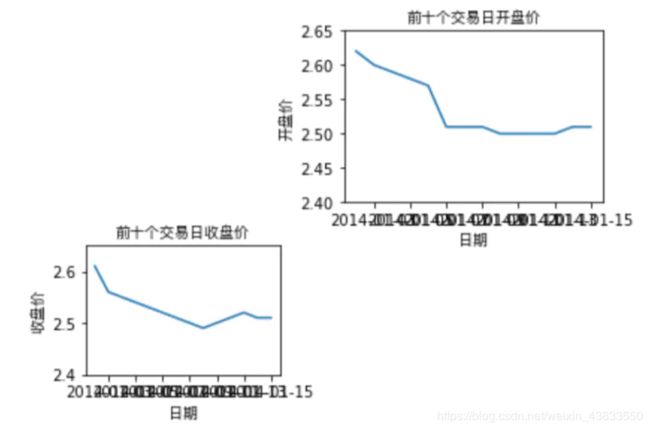
在实际绘图中,如果一个Figure对象中包含多个Axes对象,每个Axes对象的位置除了通过区域坐标和长度来设定一位,更为常用的方式是通过子图subplot()函数来设定。
fig = plt.figure()
ax1 = plt.subplot(221)
ax2 = plt.subplot(222)
ax3 = plt.subplot(223)
ax4 = plt.subplot(224)
plt.show()效果如下:
参数221中的22表示子图排列为2*2形式,1表示第一个子图,其他均为同样的道理.
最后,我们再来体验一个绘制多图的例子:
Close15 = Close['2015']
ax1 = plt.subplot(221)
ax1.plot(Close15,color='k')
ax1.set_xlabel('日期',fontproperties=getChineseFont())
ax1.set_ylabel('收盘价',fontproperties=getChineseFont())
ax1.set_title('中国银行2015年收盘价曲线',fontproperties=getChineseFont())
Volume15 = ChinaBank['Volume']['2015']
Open15 = Open['2015']
ax2 = plt.subplot(212)
left1 = Volume15.index[Close15>=Open15]
hight1 = Volume15[left1]
ax2.bar(left1,hight1,color='r')
left2 = Volume15.index[Close15绘制结果如下图所示:
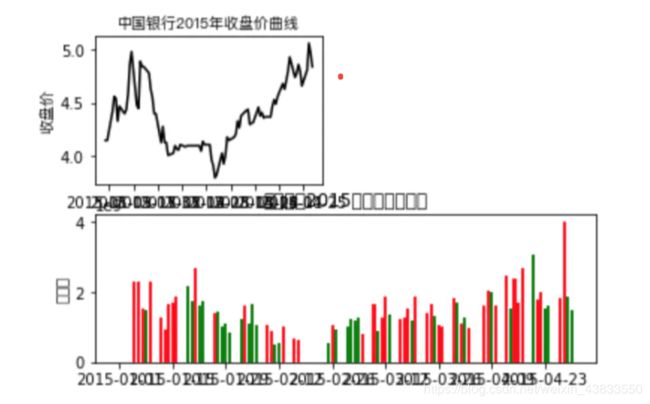
三、Scikit-learn数学建模库:以回归为例
机器学习分为监督学习、无监督学习与强化学习。不管怎么说,回归都一定是数学建模、办公方面机器学习的基础之重点。
1、30分钟学会用scikit-learn的基本回归方法(线性、决策树、SVM、KNN)和集成方法(随机森林,Adaboost和GBRT):
这一部分博主认为入门非常简单而精辟的总结是慕课网的这篇文章http://www.imooc.com/article/27096,比较全面地写了有关入门回归算法的注意和知识点,可以阅读参考。
2、来自博主自己的线性回归基本方法总结:
小数据的一元线性回归,可以精要地总结为六个步骤。
(1)数据获取与观察:
因为通常我们手中现成的数据都是以Excel文档,.xlsx方式存储的,数学建模中,我们通常利用Pandas读取文件,获取DataFrame类型数据。
import pandas as pd
data=pd.read_excel("chapter_15_1.xlsx")
其中第一行是导入pandas模块,第二行是调用excel读取函数,填入文件名称即可。另外一种方式是查看数据集的前几行,例如调用head方法,默认查询其前五行:
data.head()
利用data.shape可以获取数据的维度,返回的结果是一个二元元组,分别代表行数和列数。
(2)确定变量:
首先我们要想清楚自变量和因变量分别是哪个,设为x,y,然后用散点图的方式将数据展示出来:
X, y=data[["广告费(万元)"]], data[["销售额(万元)"]]
import matplotlib.pyplot as plt
plt.scatter(X,y)
plt.xlabel("X")
plt.ylabel("y")
从而用matplotlib模块的方法建立了一个散点图,其中X和y分别是自变量和因变量。
(3)构建模型:
from sklearn import linear_model
clf=linear_model.LinearRegression()
model=clf.fit(X,y)
首先从scikit-learn库中调出线性规划模型,然后利用Regression对象创建一个线性规划模型的实例。最后用fit对象表示将我们已经有的数据X,y去学习、适应这个模型,model是适应学习完成后的模型的实例。
如果我们到当前步骤就想要查看线性回归的结果,则使用model.coef_和model.intercept_两个对象分别调用出自变量系数(斜率)和常数项(截距)的估计值来看。在多元线性回归中,y=w0+w1x1+......+wnxn时,coef_代表向量(w1,w2,......,wn),而intercept_代表w0。
(4)模型检验:
model_score=model.score(X,y)
这是一个用来检测模型估计值准确度的函数,其背景意义,也就是返回值为决定系数:

用print方法打印score。score的值不会超过1,但有可能是负数。score值越大说明我们的模型估计越准确,性能越好。
(5)模型预测:
X=1050
y_pred=model.predict(X)
用print方法打印y_pred,输出的结果是一个单元素的array,也就是投入1050的X估计出的y的值。
(6)拟合效果图:
plt.scatter(X,y)
plt.plot(X,y_pred,"g-")
plt.xlabel("X")
plt.ylabel("y")
这里和上面初始画散点图的方式类似,但是利用plot方法结合g-绘制标签,做出了我们需要的直线。图的坐标点基本分布在直线的两侧,并没有过于异常的点,与模型检验中的高得分情况吻合。这说明在当前少量数据下,一元线性回归效果显著。
3、split方法分割矩阵参数:
很多时候我们把需要的数据都获取成为一个矩阵之后,希望既能用一部分来训练,一部分来检验,然后再进行预测。这时候需要用到split方法:
train_test_split(data, target, test_size=0.3, random_state=0)
其中data是被划分的样本特征集。target是被划分的样本标签。test_size如果是浮点数再0-1之间,则表示样本占比;如果是整数,就是指样本的数量。random_state是随机数的生成种子,用的比较少,如果填1,则需要重复的实验时保证得到一摸一样的随机数,如果填0或者不填,则重复实验的时候每次随机数都不一样。